
This article was published as a part of the Data Science Blogathon.
Introduction on Video Game Clustering
In this article, I am going to cluster some of the popular video games according to their given features. I have done this project while learning about the K-Means Clustering. After reading this article, you can able to:
- Data manipulation using Pandas.
- Impute missing values using KNN.
- Reduce the dimensionality of data.
- Apply K-Means for clustering.
I am writing this article in such a way that anyone can understand what I am doing. So, take a cup of coffee and read on.
Import Necessary Packages
Let’s import the necessary packages. The packages are given below.
Reading the Data
Now I read the data using pandas and then do some preprocessing steps on data before feeding the data into the model and gaining insights about the data. The data is in CSV format. You can download the data from my GitHub repo.
data = pd.read_csv("data/video_games.csv")if you print the top 5 rows in this dataset, the table will look something like this.
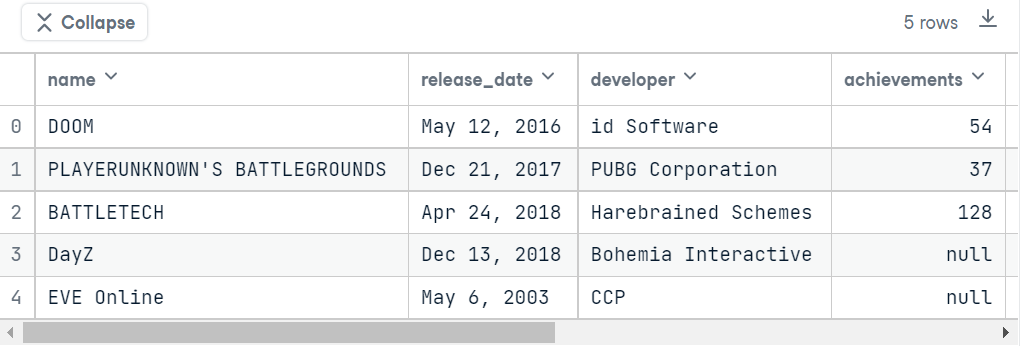
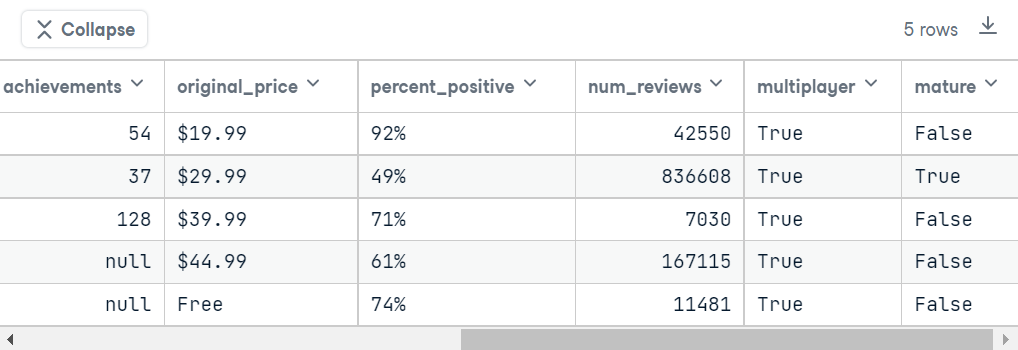
From the above images, we can easily notice that there are 9 columns in this data. Those are:
.png)
Data Preprocessing
Now, Let’s see if there are any null values available in the dataset. For this, run the below code.
plt.figure(figsize=(10,8))
sns.heatmap(data.isnull(), cmap='magma', yticklabels=False)if you run this code, the output will look something like the below.
.png)
Let’s see the number of null values numerically.
data.isnull().sum()
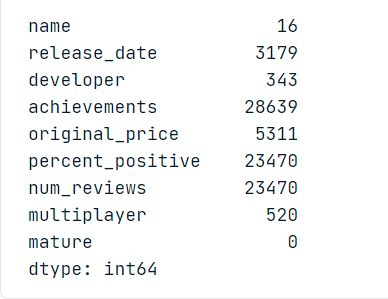
Woah! there exist so many null values in the dataset. So for better imputation, I am using the KNearestNeighbors algorithm from the fancyimpute package. But before doing that, I want to remove some of the null values:
- rows containing name columns as null, because this makes no sense for imputing those using KNN.
- rows containing developer, percent_positive, num_reviews, and multiplayer as null are the main features. Without those values, KNN will unable to find a pattern for replacing those values.
I also want to drop some columns. release_date and achievements neither matter for searching for a game nor determining the genre. and for now, I am removing the original_price column for simplicity. If you have previously seen the table, the original_price column contains mixed values. Below is the image of 50 unique values of the original_price column.

Just see the image. Some of the games are free and some of them are paid. But there is no way that I can change this column data type. So, I am dropping this column.
data.drop(['release_date', 'achievements', 'original_price'], axis=1, inplace=True)Now, Let’s drop the null values.
After dropping all the unnecessary rows, now the size of the dataset is (40748, 6). As this is a huge dataset, I have to take a small part of this. I took two parts from the data. One for training and one for testing. After that, I encode the categorical variables and impute them.
If everything is fine, the first 5 rows for train and test will look like this after encoding.
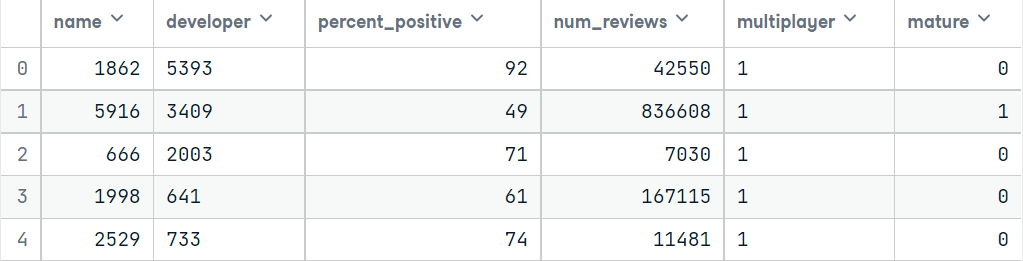
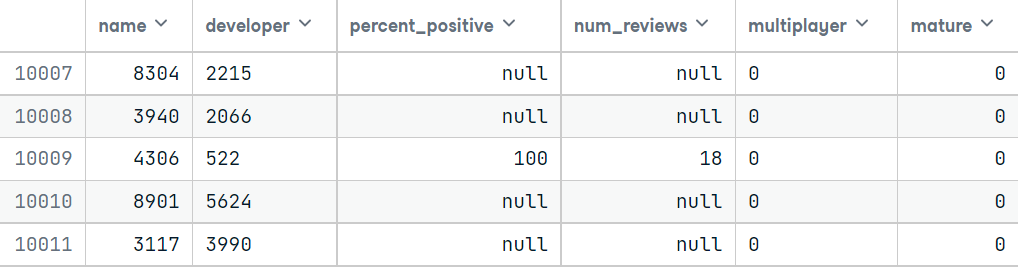
Now it’s the time for imputation. but before that, we have to install fancyimpute. You can install this by running the below command.
pip install fancyimpute
After the successful installation, we can use the KNN algorithm from fancyimpute.
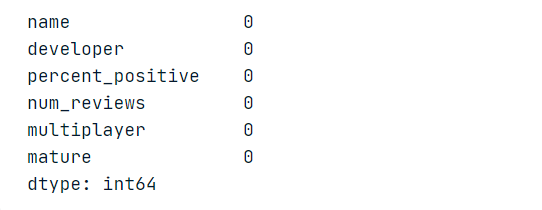
Now, if you want to verify that there are no null values in the dataset, just run the below code.
print(data1.isnull().sum())
print(data2.isnull().sum())
You will get the below output for both:
Time for Modelling
After imputing all the values and verifying them, now it is time for modeling. According to the problem we have to classify using clustering techniques. I am using K-Means Clustering here. before feeding this data into the model, we have to encode it again.
Applying PCA
Now I am going to extract the important features using Principal Component Analysis (PCA). Without this, K-Means works very badly in clustering the data.
Here I am taking two components for PCA. You can try with different numbers.
Determining the Number of Clusters
Now there is a question that how to determine the number of clusters in K-means. there are two methods for this – silhouette score and elbow method. I am using the Elbow method here. We have to plot a graph on different inertias based on different cluster numbers in this method. we have to choose a cluster number from where there is minimal change in values. as this graph seems to be a human’s elbow, so this method name is the elbow method.
If you run the above code, you will get the below output.
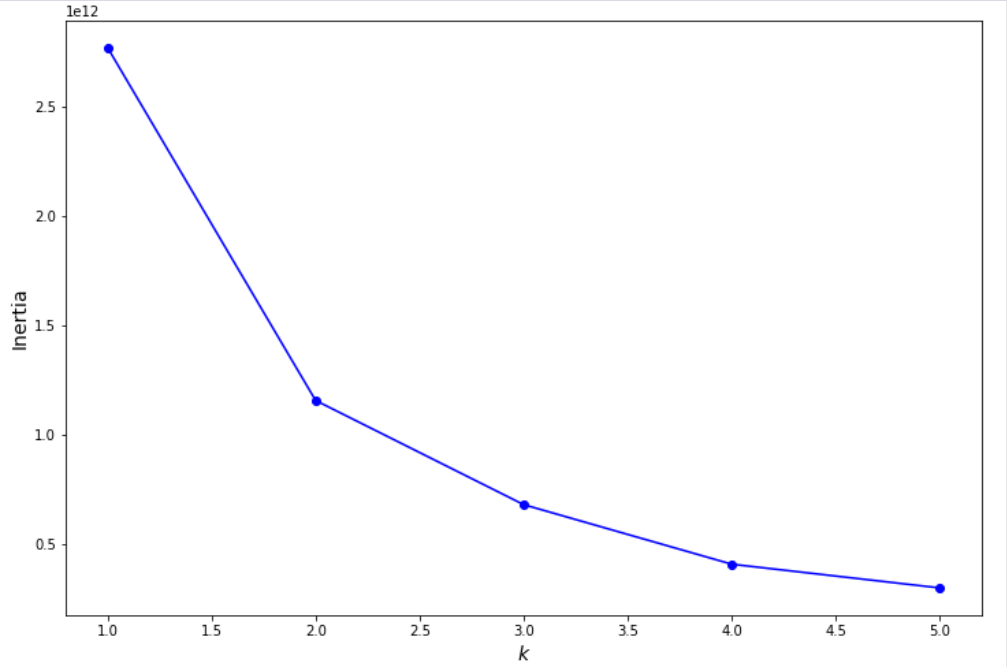
From this graph, we can see that 2 is the desired cluster number.
Now we are ready for clustering😁.
If the code is running successfully, you can see the below plot.
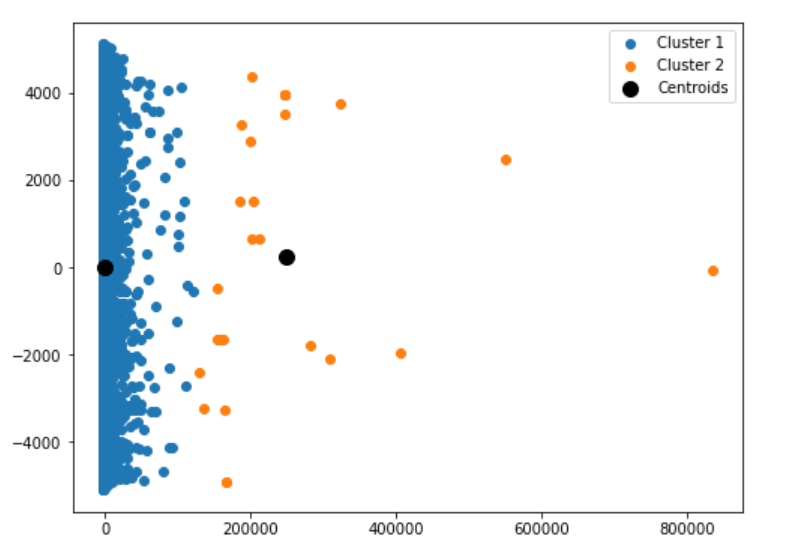
after training the model on 2 clusters and predicting on the training set, this is the result of the machine clustering the games into two sections. though I don’t include the price column here, the machine still clusters them into two parts. Let’s see the results in the testing set.
If you run the above code, you can see the below plot:
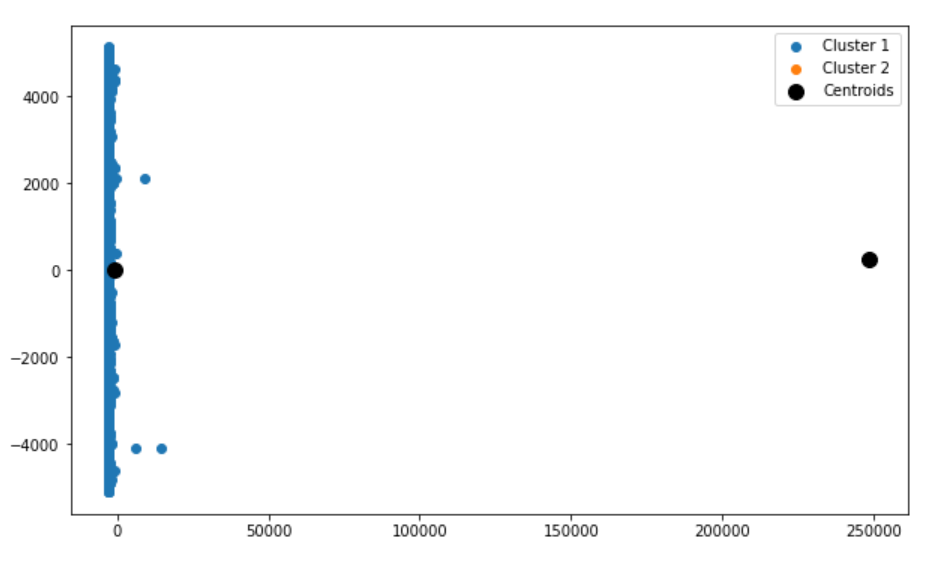
The games are also divided into the two clusters, but the data points are missing for cluster 2. The testing set may contain only those data points related to cluster 1.
Conclusion on Video Game Clustering
From the above two plots, we can clearly say that the model successfully makes the distinction between the two categories.
The Video Game Clustering Model can be improved by
- considering the original_price column.
- With limited computational resources, I have to take a sample of the data and have to work on them. If I can take the whole data for model training, this model can be much more accurate in clustering the data.
- There is also scope for feature engineering like making a new column positive_review using positive_percent and num_reviews column.
So, that’s all for today. I hope you like this article. If you want to know about me and want to read my other articles, visit here. For now, goodbye👋.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Recently pursuing M.Tech in Artificial Intelligence and love to do anything about Data Science, Machine Learning, and AI. I also like to share my knowledge through Blogs. Ask me anything about Data Science, Machine Learning, and AI at [email protected].
Free Courses





