Technology is evolving round the clock in recent times. This has resulted in job opportunities for people all around the world. It comes with a hectic schedule that can be detrimental to people’s mental health. So During the Covid-19 pandemic, mental health has been one of the most prominent issues, with stress, loneliness, and depression all on the rise over the last year. Diagnosing mental health is difficult because people aren’t always willing to talk about their problems.
Machine learning is a branch of artificial intelligence that is mostly used nowadays. ML is becoming more capable for disease diagnosis and also provides a platform for doctors to analyze a large number of patient data and create personalized treatment according to the patient’s medical situation.
In this article, we are going to predict the mental health of Employees using various machine learning models. You can download the dataset from this link.
Library and Data Loading
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from scipy import stats
from scipy.stats import randint
# prep
from sklearn.model_selection import train_test_split
from sklearn import preprocessing
from sklearn.datasets import make_classification
from sklearn.preprocessing import binarize, LabelEncoder, MinMaxScaler
# models
from sklearn.linear_model import LogisticRegression
from sklearn.tree1 import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier, ExtraTreesClassifier
# Validation libraries
from sklearn import metrics
from sklearn.metrics import accuracy_score, mean_squared_error, precision_recall_curve
from sklearn.model_selection import cross_val_score1
#Neural Network
from sklearn.neural_network import MLPClassifier
from sklearn.model_selection import RandomizedSearchCV
#Bagging
from sklearn.ensemble import BaggingClassifier, AdaBoostClassifier
from sklearn.neighbors import KNeighborsClassifier
#Naive bayes
from sklearn.naive_bayes import GaussianNB
#Stacking
from mlxtend.classifier import StackingClassifier
#Get rid of bullshit
stk_list = ['A little about you', 'p']
train_df = train_df[~train_df['Gender'].isin(stk_list)]
print(train_df['Gender'].unique())
[‘female’ ‘male’ ‘trans’]
#complete missing age with mean
train_df['Age'].fillna(train_df['Age'].median(), inplace = True)
# Fill with media() values 120
s = pd.Series(train_df['Age'])
s[s<18] = train_df['Age'].median()
train_df['Age'] = s
s = pd.Series(train_df['Age'])
s[s>120] = train_df['Age'].median()
train_df['Age'] = s
#Ranges of Age
train_df['age_range'] = pd.cut(train_df['Age'], [0,20,30,65,100], labels=["0-20", "21-30", "31-65", "66-100"], include_lowest=True)
#There are only 0.014% of self employed so let's change NaN to NOT self_employed
#Replace "NaN" string from defaultString
train_df['self_employed'] = train_df['self_employed'].replace([defaultString], 'No')
print(train_df['self_employed'].unique())
[‘No’ ‘Yes’]
#There are only 0.20% of self work_interfere so let's change NaN to "Don't know
#Replace "NaN" string from defaultString
train_df['work_interfere'] = train_df['work_interfere'].replace([defaultString], 'Don't know' )
print(train_df['work_interfere'].unique())
#Encoding data
labelDict = {}
for feature in train_df:
le = preprocessing.LabelEncoder()
le.fit(train_df[feature])
le_name_mapping = dict(zip(le.classes_, le.transform(le.classes_)))
train_df[feature] = le.transform(train_df[feature])
# Get labels
labelKey = 'label_' + feature
labelValue = [*le_name_mapping]
labelDict[labelKey] =labelValue
for key, value in labelDict.items():
print(key, value)
#Get rid of 'Country'
train_df = train_df.drop(['Country'], axis= 1)
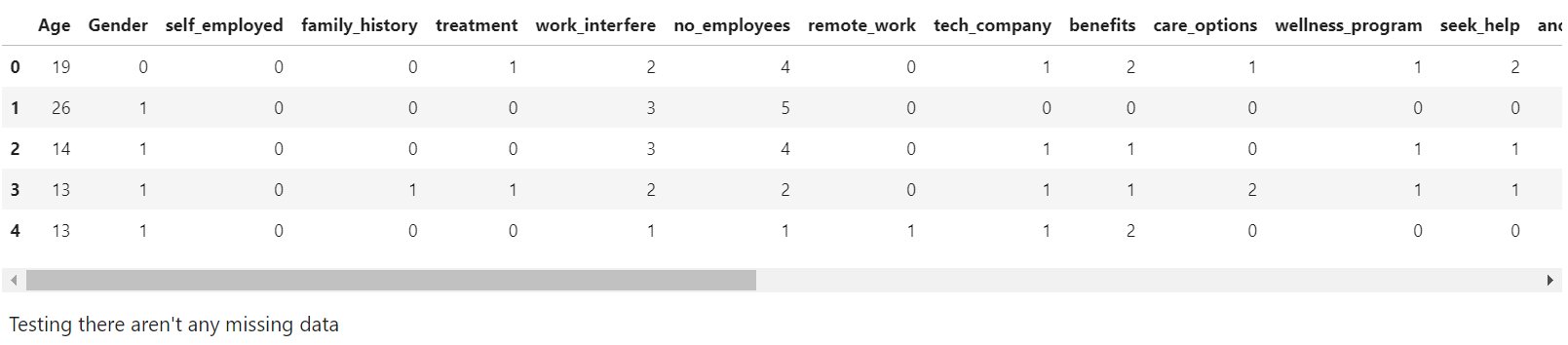
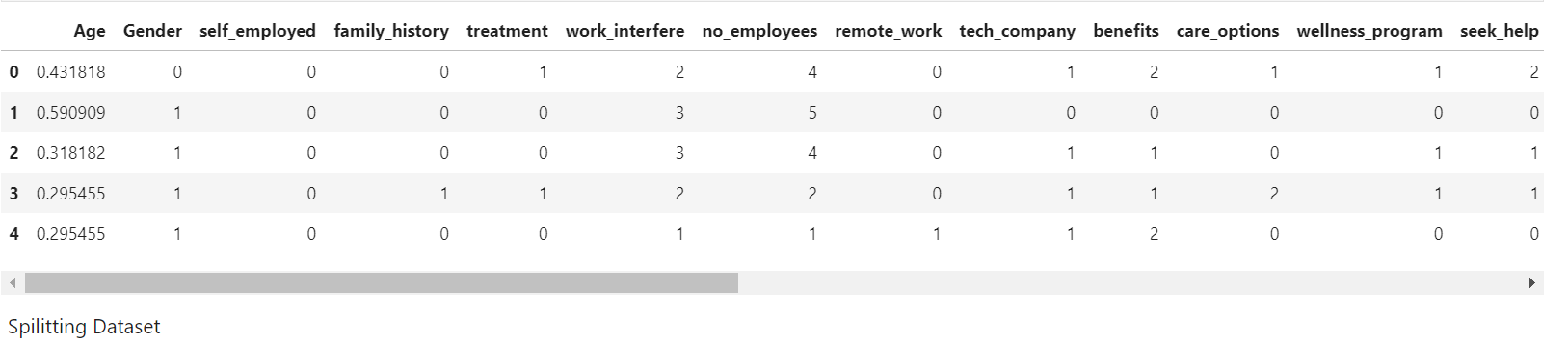
train_df.head()
#missing data
total = train_df.isnull().sum().sort_values(ascending=False)
percent = (train_df.isnull().sum()/train_df.isnull().count()).sort_values(ascending=False)
missing_data = pd.concat([total, percent], axis=1, keys=['Total', 'Percent'])
missing_data.head(20)
print(missing_data)
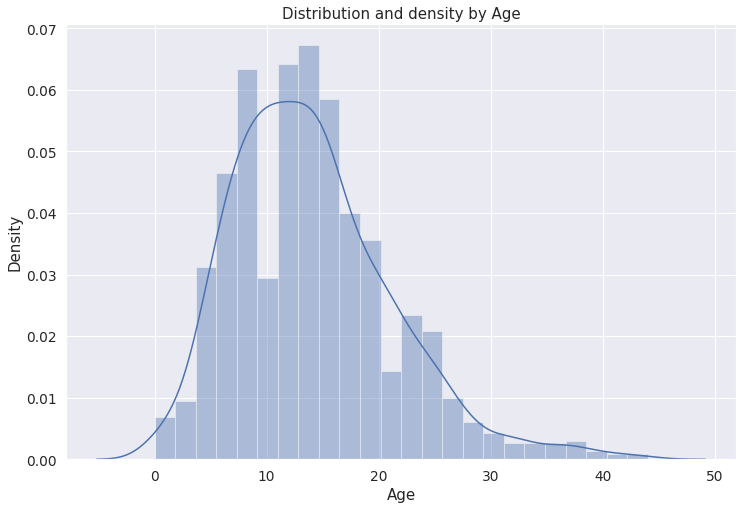
# Distribution and density by Age
plt.figure(figsize=(12,8))
sns.distplot(train_df["Age"], bins=24)
plt.title("Distribution and density by Age")
plt.xlabel("Age")
Text(0.5, 0, ‘Age’)
Inference: The above plot shows the Age column with respect to density. We can see that density is higher from Age 10 to 20 years in our dataset.
Inference: Treatment 0 means treatment is not necessary 1 means it is. First Barplot shows that from age 0 to 10-year treatment is not necessary and is needed after 15 years.
plt.figure(figsize=(12,8))
labels = labelDict['label_Gender']
j = sns.countplot(x="treatment", data=train_df)
j.set_xticklabels(labels)
plt.title('Total Distribution by treated or not')
Text(0.5, 1.0, ‘Total Distribution by treated or not’)
Inference: Here we can see that more males are treated as compared to females in the dataset.
o = labelDict['label_age_range']
j = sns.factorplot(x="age_range", y="treatment", hue="Gender", data=train_df, kind="bar", ci=None, size=5, aspect=2, legend_out = True)
j.set_xticklabels(o)
plt.title('Probability of mental health condition')
plt.ylabel('Probability x 100')
plt.xlabel('Age')
new_labels = labelDict['label_Gender']
for t, l in zip(j._legend.texts, new_labels): t.set_text(l)
j.fig.subplots_adjust(top=0.9,right=0.8)
plt.show()
Inference: This barplot shows the mental health of females, males, and transgender according to different age groups. we can analyze that from the age group of 66 to 100, mental health is very high in females as compared to another gender. And from age 21 to 64, mental health is very high in transgender as compared to males.
o = labelDict['label_family_history']
j = sns.factorplot(x="family_history", y="treatment", hue="Gender", data=train_df, kind="bar", ci=None, size=5, aspect=2, legend_out = True)
j.set_xticklabels(o)
plt.title('Probability of mental health condition')
plt.ylabel('Probability x 100')
plt.xlabel('Family History')
new_labels = labelDict['label_Gender']
for t, l in zip(g._legend.texts, new_labels): t.set_text(l)
j.fig.subplots_adjust(top=0.9,right=0.8)
plt.show()
o = labelDict['label_care_options']
j = sns.factorplot(x="care_options", y="treatment", hue="Gender", data=train_df, kind="bar", ci=None, size=5, aspect=2, legend_out = True)
j.set_xticklabels(o)
plt.title('Probability of mental health condition')
plt.ylabel('Probability x 100')
plt.xlabel('Care options')
new_labels = labelDict['label_Gender']
for t, l in zip(g._legend.texts, new_labels): t.set_text(l)
j.fig.subplots_adjust(top=0.9,right=0.8)
plt.show()
Inference: In the dataset, for those who are having a family history of mental health problems, the Probability of mental health will be high. So here we can see that probability of mental health conditions for transgender is almost 90% as they have a family history of medical health conditions.
Inference: This barplot shows health status with respect to care options. In the dataset, for Those who are not having care options, the Probability of mental health situation will be high. So here we can see that the mental health of transgender is very high who have not care options and low for those who are having care options.
o = labelDict['label_benefits']
j = sns.factorplot(x="care_options", y="treatment", hue="Gender", data=train_df, kind="bar", ci=None, size=5, aspect=2, legend_out = True)
j.set_xticklabels(o)
plt.title('Probability of mental health condition')
plt.ylabel('Probability x 100')
plt.xlabel('Benefits')
new_labels = labelDict['label_Gender']
for t, l in zip(j._legend.texts, new_labels): t.set_text(l)
j.fig.subplots_adjust(top=0.9,right=0.8)
plt.show()
Inference: This barplot shows the probability of health conditions with respect to Benefits. In the dataset, for those who are not having any benefits, the Probability of mental health conditions will be high. So here we can see that probability of mental health conditions for transgender is very high who have not getting any benefits. and probability is low for those who are having benefits options.
o = labelDict['label_work_interfere']
j = sns.factorplot(x="work_interfere", y="treatment", hue="Gender", data=train_df, kind="bar", ci=None, size=5, aspect=2, legend_out = True)
j.set_xticklabels(o)
plt.title('Probability of mental health condition')
plt.ylabel('Probability x 100')
plt.xlabel('Work interfere')
new_labels = labelDict['label_Gender']
for t, l in zip(g._legend.texts, new_labels): t.set_text(l)
j.fig.subplots_adjust(top=0.9,right=0.8)
plt.show()
Inference: This barplot shows the probability of health conditions with respect to work interference. For those who are not having any work interference, the Probability of mental health conditions will be very less. and probability is high for those who are having work interference rarely.
Scaling and Fitting
# Scaling Age
scaler = MinMaxScaler()
train_df['Age'] = scaler.fit_transform(train_df[['Age']])
train_df.head()
# define X and y
feature_cols1 = ['Age', 'Gender', 'family_history', 'benefits', 'care_options', 'anonymity', 'leave', 'work_interfere']
X = train_df[feature_cols1]
y = train_df.treatment
X_train1, X_test1, y_train1, y_test1 = train_test_split(X, y, test_size=0.30, Random_state1=0)
# Create dictionaries for final graph
# Use: methodDict['Stacking'] = accuracy_score
methodDict = {}
rmseDict = ()
forest = ExtraTreesClassifier(n_estimators=250,
Random_state1=0)
forest.fit(X, y)
importances = forest.feature_importances_
std = np.std([tree1.feature_importances_ for tree in forest.estimators_],
axis=0)
indices = np.argsort(importances)[::-1]
labels = []
for f in Range(x.shape[1]):
labels.append(feature_cols1[f])
plt.figure(figsize=(12,8))
plt.title("Feature importances")
plt.bar(range(X.shape[1]), importances[indices],
color="r", yerr=std[indices], align="center")
plt.Xticks(range(X.shape[1]), labels, rotation='vertical')
def tuningCV(knn):
k_Range = list(Range(1, 31))
k_scores = []
for k in k_range:
knn = KNeighborsClassifier(n_neighbors=k)
scores = cross_val_score1(knn, X, y, cv=10, scoring='accuracy')
k_scores.append(scores.mean())
print(k_scores)
plt.plot(k_Range, k_scores)
plt.xlabel('Value of K for KNN')
plt.ylabel('Cross-Validated Accuracy')
plt.show()
Tuning with GridSearchCV
def tuningGridSerach(knn):
k_Range = list(range(1, 31))
print(k_Range)
param_grid = dict(n_neighbors=k_range)
print(param_grid)
grid = GridSearchCV(knn, param_grid, cv=10, scoring='accuracy')
grid.fit(X, y)
grid.grid_scores1_
print(grid.grid_scores_[0].parameters)
print(grid.grid_scores_[0].cv_validation_scores)
print(grid.grid_scores_[0].mean_validation_score)
grid_mean_scores1 = [result.mean_validation_score for result in grid.grid_scores_]
print(grid_mean_scores1)
# plot the results
plt.plot(k_Range, grid_mean_scores1)
plt.xlabel('Value of K for KNN')
plt.ylabel('Cross-Validated Accuracy')
plt.show()
# examine the best model
print('GridSearch best score', grid.best_score_)
print('GridSearch best params', grid.best_params_)
print('GridSearch best estimator', grid.best_estimator_)
The final prediction consists of 0 and 1. 0 means the person is not needed any mental health treatment and 1 means the person is needed mental health treatment.
Conclusion
After using all these Employee records, we are able to build various machine learning models. From all the models, ADA–Boost achieved 81.75% accuracy with an AUC of 0.8185 along with that we were able to draw some insights from the data via data analysis and visualization.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
I currently working as an Assistant professor in the Information technology department at SAL COLLEGE OF ENGINEERING, AHMEDABAD .I am currently doing Ph.D. in Medical Image processing. My research interest are computer vision, deep learning, machine learning, database etc.
We use cookies essential for this site to function well. Please click to help us improve its usefulness with additional cookies. Learn about our use of cookies in our Privacy Policy & Cookies Policy.
Show details
Powered By
Cookies
This site uses cookies to ensure that you get the best experience possible. To learn more about how we use cookies, please refer to our Privacy Policy & Cookies Policy.
brahmaid
It is needed for personalizing the website.
csrftoken
This cookie is used to prevent Cross-site request forgery (often abbreviated as CSRF) attacks of the website
Identityid
Preserves the login/logout state of users across the whole site.
sessionid
Preserves users' states across page requests.
g_state
Google One-Tap login adds this g_state cookie to set the user status on how they interact with the One-Tap modal.
MUID
Used by Microsoft Clarity, to store and track visits across websites.
_clck
Used by Microsoft Clarity, Persists the Clarity User ID and preferences, unique to that site, on the browser. This ensures that behavior in subsequent visits to the same site will be attributed to the same user ID.
_clsk
Used by Microsoft Clarity, Connects multiple page views by a user into a single Clarity session recording.
SRM_I
Collects user data is specifically adapted to the user or device. The user can also be followed outside of the loaded website, creating a picture of the visitor's behavior.
SM
Use to measure the use of the website for internal analytics
CLID
The cookie is set by embedded Microsoft Clarity scripts. The purpose of this cookie is for heatmap and session recording.
SRM_B
Collected user data is specifically adapted to the user or device. The user can also be followed outside of the loaded website, creating a picture of the visitor's behavior.
_gid
This cookie is installed by Google Analytics. The cookie is used to store information of how visitors use a website and helps in creating an analytics report of how the website is doing. The data collected includes the number of visitors, the source where they have come from, and the pages visited in an anonymous form.
_ga_#
Used by Google Analytics, to store and count pageviews.
_gat_#
Used by Google Analytics to collect data on the number of times a user has visited the website as well as dates for the first and most recent visit.
collect
Used to send data to Google Analytics about the visitor's device and behavior. Tracks the visitor across devices and marketing channels.
AEC
cookies ensure that requests within a browsing session are made by the user, and not by other sites.
G_ENABLED_IDPS
use the cookie when customers want to make a referral from their gmail contacts; it helps auth the gmail account.
test_cookie
This cookie is set by DoubleClick (which is owned by Google) to determine if the website visitor's browser supports cookies.
_we_us
this is used to send push notification using webengage.
WebKlipperAuth
used by webenage to track auth of webenagage.
ln_or
Linkedin sets this cookie to registers statistical data on users' behavior on the website for internal analytics.
JSESSIONID
Use to maintain an anonymous user session by the server.
li_rm
Used as part of the LinkedIn Remember Me feature and is set when a user clicks Remember Me on the device to make it easier for him or her to sign in to that device.
AnalyticsSyncHistory
Used to store information about the time a sync with the lms_analytics cookie took place for users in the Designated Countries.
lms_analytics
Used to store information about the time a sync with the AnalyticsSyncHistory cookie took place for users in the Designated Countries.
liap
Cookie used for Sign-in with Linkedin and/or to allow for the Linkedin follow feature.
visit
allow for the Linkedin follow feature.
li_at
often used to identify you, including your name, interests, and previous activity.
s_plt
Tracks the time that the previous page took to load
lang
Used to remember a user's language setting to ensure LinkedIn.com displays in the language selected by the user in their settings
s_tp
Tracks percent of page viewed
AMCV_14215E3D5995C57C0A495C55%40AdobeOrg
Indicates the start of a session for Adobe Experience Cloud
s_pltp
Provides page name value (URL) for use by Adobe Analytics
s_tslv
Used to retain and fetch time since last visit in Adobe Analytics
li_theme
Remembers a user's display preference/theme setting
li_theme_set
Remembers which users have updated their display / theme preferences
We do not use cookies of this type.
_gcl_au
Used by Google Adsense, to store and track conversions.
SID
Save certain preferences, for example the number of search results per page or activation of the SafeSearch Filter. Adjusts the ads that appear in Google Search.
SAPISID
Save certain preferences, for example the number of search results per page or activation of the SafeSearch Filter. Adjusts the ads that appear in Google Search.
__Secure-#
Save certain preferences, for example the number of search results per page or activation of the SafeSearch Filter. Adjusts the ads that appear in Google Search.
APISID
Save certain preferences, for example the number of search results per page or activation of the SafeSearch Filter. Adjusts the ads that appear in Google Search.
SSID
Save certain preferences, for example the number of search results per page or activation of the SafeSearch Filter. Adjusts the ads that appear in Google Search.
HSID
Save certain preferences, for example the number of search results per page or activation of the SafeSearch Filter. Adjusts the ads that appear in Google Search.
DV
These cookies are used for the purpose of targeted advertising.
NID
These cookies are used for the purpose of targeted advertising.
1P_JAR
These cookies are used to gather website statistics, and track conversion rates.
OTZ
Aggregate analysis of website visitors
_fbp
This cookie is set by Facebook to deliver advertisements when they are on Facebook or a digital platform powered by Facebook advertising after visiting this website.
fr
Contains a unique browser and user ID, used for targeted advertising.
bscookie
Used by LinkedIn to track the use of embedded services.
lidc
Used by LinkedIn for tracking the use of embedded services.
bcookie
Used by LinkedIn to track the use of embedded services.
aam_uuid
Use these cookies to assign a unique ID when users visit a website.
UserMatchHistory
These cookies are set by LinkedIn for advertising purposes, including: tracking visitors so that more relevant ads can be presented, allowing users to use the 'Apply with LinkedIn' or the 'Sign-in with LinkedIn' functions, collecting information about how visitors use the site, etc.
li_sugr
Used to make a probabilistic match of a user's identity outside the Designated Countries
MR
Used to collect information for analytics purposes.
ANONCHK
Used to store session ID for a users session to ensure that clicks from adverts on the Bing search engine are verified for reporting purposes and for personalisation
We do not use cookies of this type.
Cookie declaration last updated on 24/03/2023 by Analytics Vidhya.
Cookies are small text files that can be used by websites to make a user's experience more efficient. The law states that we can store cookies on your device if they are strictly necessary for the operation of this site. For all other types of cookies, we need your permission. This site uses different types of cookies. Some cookies are placed by third-party services that appear on our pages. Learn more about who we are, how you can contact us, and how we process personal data in our Privacy Policy.



.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)