
This article was published as a part of the Data Science Blogathon.
Introduction
ETL is the process that extracts the data from various data sources, transforms the collected data, and loads that data into a common data repository. It helps organizations across the globe in planning marketing strategies and making critical business decisions. Azure Data Factory (ADF) is a cloud-based ETL and data integration service provided by Azure. We can build complex ETL processes and scheduled event-driven workflows using Azure Data Factory.
In this guide, I’ll show you how to build an ETL data pipeline to convert a CSV file into JSON File with Hierarchy and array using Data flow in Azure Data Factory.
Source: https://github.com/mspnp/azure-data-factory-sqldw-elt-pipeline
What is ETL?
ETL is the process that collects data from various sources, then transforms the data into a usable and trusted resource using various operations like filtering, concatenation, sorting, etc., and loads that data into a destination store. ETL, which stands for extract, transform, and load, describes the end-to-end process by which an organization can prepare data for business intelligence processes.
ETL is commonly used for data integration, data warehousing, cloud migration, machine learning, and artificial intelligence. ETL provides a mechanism to move the data from various data sources into a common data repository. It helps companies in planning marketing strategies or making critical business decisions by analyzing their business data.
An ETL pipeline or data pipeline is the set of processes used to move data from various sources into a common data repository such as a data warehouse. Data pipelines are a set of tools and activities that ingest raw data from various sources and move the data into a destination store for analysis and storage.
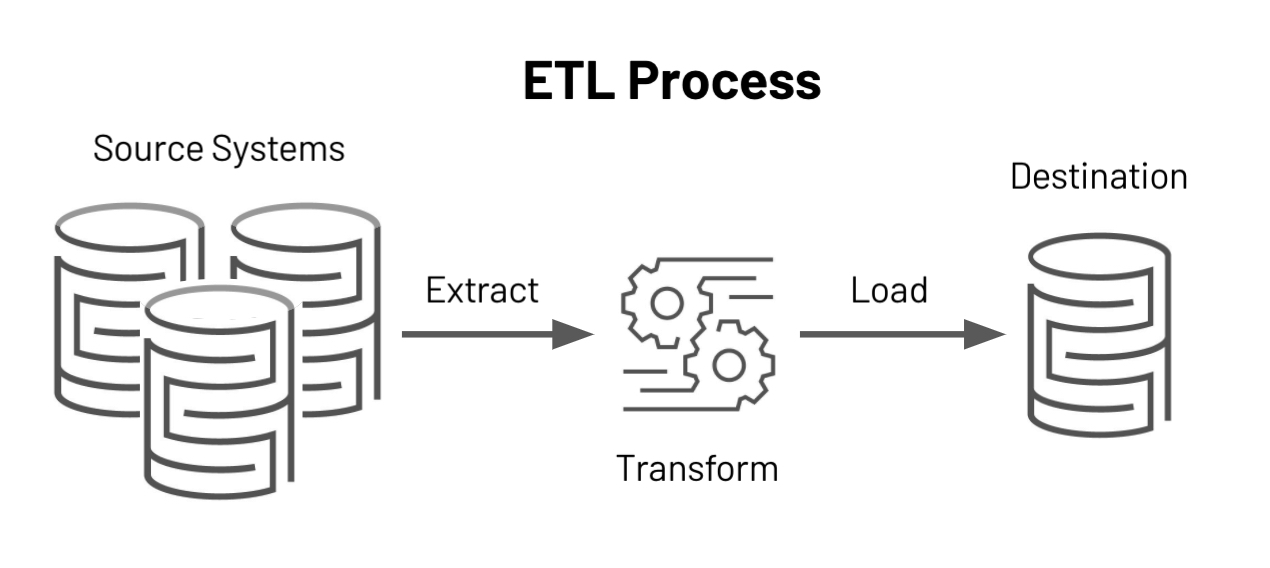
Source: https://databricks.com/glossary/extract-transform-load
Now, we will learn how the ETL process works.
How does ETL Work?
Below are the three steps of the ETL process:
1. Extract: The first step is to extract the raw data from various data sources and place it in the staging area. Data came from different data sources such as CRM, transactional processing, APIs, sensor data, etc could be structured, semi-structured, or unstructured. If any transformations are required on data, they are performed in the staging area so that the performance of the source system is not degraded. Extraction can be further divided into three types:
a. Partial Extraction
b. Partial Extraction (with update notification)
c. Full extract
2. Transform: The data extracted in the previous step is raw and we need to clean, map and transform the data to convert the data into a format that can be used by different applications. Data inconsistency and inaccuracies are removed during data transformation. Apart from this, data mapping and data standardization are also done. Data standardization refers to the process of converting all data types to the same format. Various functions and rules are applied to prevent the entrance of bad or inconsistent data into the destination repository.
3. Load: Loading data in the destination repository is the last step of the ETL process. For better performance, the load process should be optimized. Data is delivered and shared in a secure way to required users and departments so that it can be used for effective decision-making and storytelling.
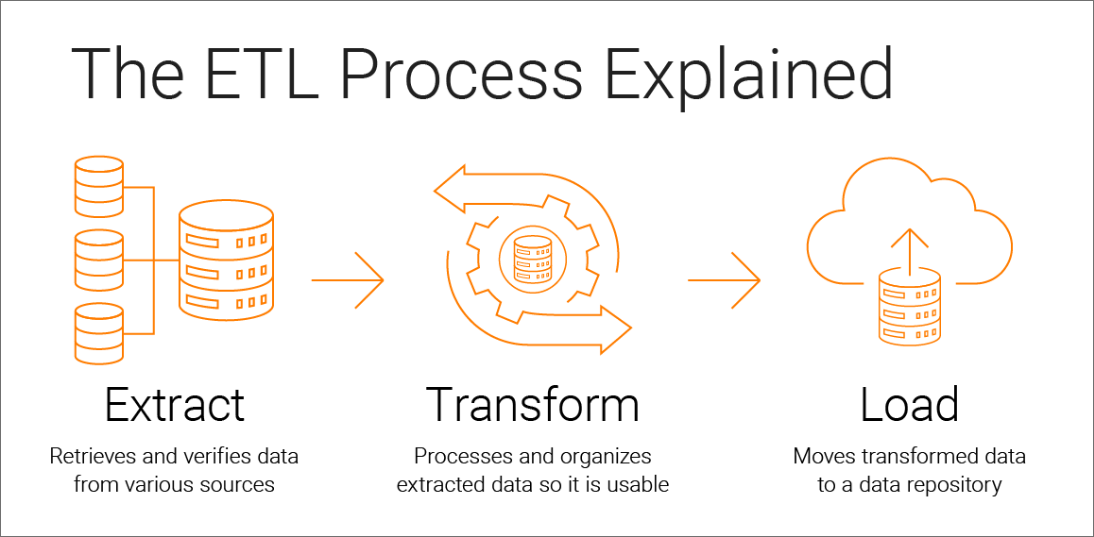
Source: https://www.informatica.com/hk/resources/articles/what-is-etl.html
What is ADF?
In today’s world, a huge amount of data is generated every day. Among this, a large volume of data is mostly raw and unorganized. However, we cannot use raw data to provide meaningful insights to analysts, ML engineers, data scientists, or business decision-makers. Therefore, for fulfilling the above requirements a mechanism is required to convert raw data into actionable business insights.
Azure Data Factory (ADF) is a cloud-based ETL and data integration service provided by Azure. We can build complex ETL processes and scheduled event-driven workflows using Azure Data Factory.
For example, imagine an e-commerce company that collects petabytes of product purchase logs that are produced by selling products in the cloud. The company wants to analyze these logs to gain insights into customer preferences, customer retention, active customer base, etc.
The logs are stored inside a container in Azure Blob Storage. To analyze these logs, the company needs to use reference data such as marketing campaign information, customer location & purchase details which are stored in the Azure SQL database. The company wants to extract and combine data from both sources to gain useful insights. In such scenarios, it is best to use Azure Data Factory for ETL purposes. Additionally, the company can publish the transformed data to data stores such as Azure Synapse Analytics, so that the business intelligence (BI) applications such as Power BI can consume it for storytelling and dashboarding.
ADF has built-in connectors for retrieving data from various data sources such as HDFS, Azure Services, Teradata, Amazon Redshift, Google BigQuery, ServiceNow, Salesforce, etc. ADF makes the process of creating a data pipeline easy by providing data transformations with code-free data flows, CI/CD support, built-in connectors for data ingestion, orchestration, and pipeline monitoring support.
Now, we have got a good understanding of ETL and Azure Data Factory. Let’s move forward to see top-level concepts in ADF.

Source: https://azure.microsoft.com/en-in/services/data-factory/#features
Top-level Concepts in ADF
Below are top-level concepts in Azure Data Factory:
1. Dataset: Datasets identify data within different data stores which are used as inputs and outputs in the Activity. For example, the Azure SQL Table dataset specifies the SQL table in your Azure SQL Database from which you either want to take or insert data inside an activity. You must create Linked Service to link your data store to the required service before creating a dataset.
2. Linked Services: Linked Services define the connection information needed by the service to connect to the data sources. For example, An Azure SQL Database-linked service specifies a connection string to connect to the Azure SQL Database. Additionally, the Azure SQL Table dataset specifies the SQL table in your Azure SQL Database that contains the data. Linked Services are used to either represent a data store or a compute resource in ADF.
3. Activity: Activity is the task that is performed on the data. There are three types of activities in ADF: data movement activities, data transformation activities, and control activities. For example, you can use a copy activity to copy data from Azure Blob Storage to Azure SQL.
4. Pipeline: A pipeline is a logical grouping of activities that together perform a unit of work. A data factory may have one or more than one pipelines. The activities in the pipeline specify the task to be performed on the data. Users can validate, publish and monitor pipelines. For example, you can create a pipeline that gets triggered when a new blob arrives in the Azure Blob Storage container to copy data from Azure Blob Storage to Azure SQL.

Source: https://docs.microsoft.com/en-us/azure/data-factory/concepts-pipelines-activities?tabs=data-factory
5. Mapping data flows: Mapping Data Flows provides a way to perform data transformation in the data flow designer without writing any code. The mapping data flow is executed as an activity within the ADF pipeline.
6. Integration runtimes: Integration runtime provides the computing environment where the activity either runs on or gets dispatched from.
7. Triggers: Triggers determine when a pipeline execution needs to be kicked off. A pipeline can be manually triggered or based on the occurrence of an event. For example, you can create a pipeline that gets triggered when a new blob arrives in the Azure Blob Storage container to copy data from Azure Blob Storage to Azure SQL.
8. Pipeline runs: An instance of the pipeline execution is known as a Pipeline run.
9. Parameters: Parameters are defined in the pipeline and their values are consumed by activities inside the pipeline.
10. Variables: Variables are used inside the pipelines to store value temporarily.
11. Control Flow: Control flow allows for building iterative, sequential, and conditional logic within the pipeline.

Source: https://docs.microsoft.com/en-us/azure/data-factory/concepts-pipelines-activities?tabs=data-factory
Benefits of using ADF
1. Code-free data transformation: ADF provides mapping data flow to be executed as an activity in a pipeline. Mapping Data Flows provides a way to perform data transformation in the data flow designer. Thus, data transformation can be easily performed without writing any code.
2. Easy Migration of ETL Workloads to Cloud: ADF can be used to easily migrate workloads from one data source to another.
3. Consumption-based pricing: Data Factory provides a pay-as-you-go pricing model and no upfront cost is required from the customer end.
4. Better scalability and performance: ADF provides built-in parallelism and time-slicing features. Therefore, users can easily migrate a large amount of data to the cloud in a few hours. Thus, the performance of the data pipeline is improved.
5. Security: User can protect their data stores credentials in the ADF pipeline by either storing them in Azure Key Vault or by encrypting them with certificates managed by Microsoft.
What are the activities and types of activities in ADF?
A pipeline is a logical grouping of activities that together perform a unit of work. Activity is the task that is performed on the data. For example, you can use a copy activity to copy data from Azure Blob Storage to Azure SQL.
Below are the three types of activities present inside ADF:
1. Data movement activities: Data movement activities are used to move data from one data source to another. For example, a Copy activity is used to copy the data from a source location to a destination.
2. Data transformation activities: Data transformation activities are used to perform data transformation in ADF. Below are some important data transformation activities:
a. Data Flow: Data flow activity is used to perform data transformation via mapping data flows.
b. Stored Procedure: Stored Procedure activity invokes a SQL Server Stored Procedure in a pipeline.
c. Azure Functions: This activity helps to run Azure Functions in a data pipeline. The azure function is a serverless compute service that helps users to run the event-triggered code.
d. Databricks Notebook: This activity helps to run the Databricks notebook in your Azure Databricks workspace from a pipeline.
e. Spark: Spark activity executes a Spark program in the HDInsight cluster.
3. Control activities: Control flow activities are used to build iterative, sequential, or conditional logic in a pipeline. There are various control activities available in ADF such as until activity, For Each, If Condition activity, execute the pipeline, Lookup activity, etc.
Source:https://docs.microsoft.com/en-us/azure/data-factory/concepts-pipelines-activities?tabs=data-factory
Building ETL Data Pipeline for a Scenario
Now, you are familiar with various types of ADF activities and top-level ADF concepts. Let’s see how we can build an ETL data pipeline to convert a CSV file into JSON File with Hierarchy and array using Data flow in Azure Data Factory.
We are going to use a container in Azure Storage Account for storing CSV and JSON files as blobs. For building an ETL data pipeline for the above scenario, you will be required to create Azure Storage Account and Azure Data Factory. Follow the below steps to build an ETL data pipeline:
Create Azure Storage Account
Azure storage account provides highly available and secure storage for storing a variety of unstructured data such as text, images, binary data, log files, etc. Create an Azure account and sign in to it. Then, follow the below steps to create Azure Storage Account:
Step 1: Visit the Azure home page. Click on Create a resource (+).
.png)
Step 2: Select Storage Account in Popular Azure Services -> Create.
.png)
Step 3: On the Basics page, select your subscription name, create a resource group, provide the storage account name, select the performance, redundancy, and region, and click Next.
.png)
Step 4: On the Advanced page, configure the hierarchical namespace, blob storage, security, and azure files settings as per your requirements and click Next. For frequent data access, choose Hot tier.
.png)
Step 5: On the Networking page, enable public access from all networks, configure network routing and click Next.
.png)
Step 6: Click on Review + Create. The home page gets displayed, when the storage account is created successfully. Now, select Data storage-> Containers.
Step 7: Click on + Container. Provide employee as new container name and select Container in the public access level. Click Create.
.png)
Step 8: Create a blob, launch excel, copy the following text and save it in a file named Emp1.csv in your system.
| FirstName | LastName | Department | Salary | Skill1 | Skill2 | Skill3 |
| Rahul | Patel | Sales | 90000 | C | HTML | CSS |
| Chaitanya | Shah | R&D | 95000 | C# | SQL | Azure |
| Ashna | Jain | HR | 93000 | Python | Debugging | |
| Mansi | Garg | Sales | 81000 | Java | Hibernate | |
| Vipul | Gupta | HR | 84000 | ADF | Synapse | Azure |
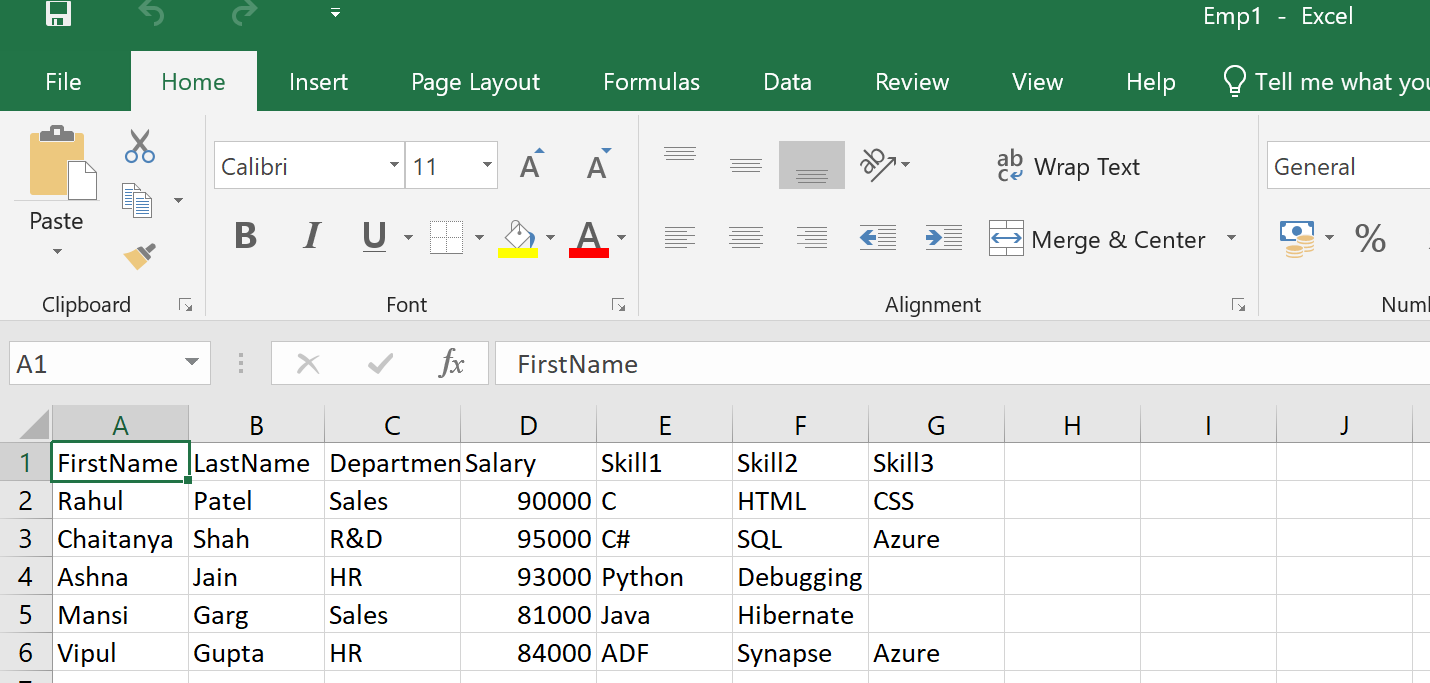
Step 9: Upload the Emp1.csv CSV file to the employee container inside the storage account.
.png)
Step 10: Click on + Container. Provide employeejson as a new container name and select Container in the public access level. Click Create.
.png)
Now, we have successfully uploaded the CSV file to the blob storage.
Create a Data Factory in Azure
Azure Data Factory (ADF) is a cloud-based ETL and data integration service provided by Azure. We can build complex ETL processes and scheduled event-driven workflows using Azure Data Factory.
Using the below steps create a data factory:
Step 1: Visit the Azure home page. Click on Create a resource (+).
.png)
Step 2: In the Azure Marketplace, search for a data factory. Select Create -> Data Factory.
.png)
Step 3: On the Basics page, select your subscription name, select the existing resource group, provide the data factory name, select the region and data factory version, and click Next.
.png)
Step 4: On the Git configuration page, choose to configure git and click Next.
.png)
Step 5: On the Networking page, fill in the required options and click Next.
.png)
Step 6: Click on Review + Create. Once the data factory is created successfully, the data factory home page is displayed. Open Azure Data Factory Studio in a new tab.
.png)
.png)
Create an ETL data pipeline to convert CSV file into JSON File with Hierarchy and array using Data flow in ADF
We have already created Azure Data Factory in the above. Now, follow the below steps inside Azure Data Factory Studio to create an ETL pipeline:
Step 1: Click New-> Pipeline. Rename the pipeline to ConvertPipeline from the General tab in the Properties section.
.png)
.png)
Step 2: After this, click Data flows-> New data flow. Inside data flow, click Add Source. Rename the source to CSV.
.png)
.png)
Step 3: In the Source tab, select source type as Dataset, and in dataset click +New to create the source dataset.
.png)
Search for Azure Blob Storage.
.png)
Select Continue-> Data Format DelimitedText -> Continue
.png)
Provide the linked service name, select the checkbox first row as a header, and click +New to create a new Linked Service.
.png)
In the new Linked Service, provide service name, select authentication type, azure subscription, and storage account name. Click Create.
.png)
After the linked service is created, the page gets redirected to the Set properties page. Now, select the Emp1.csv path in the File path.
.png)
Click OK.
.png)
Step 4: Now, click +. Select Derived Column in Schema modifier.
.png)
In the Derived column page, select Create New -> Column.
.png)
Provide info as the column name. Inside info, select +-> Add subcolumn. Write fName as column name and in the Expression select FirstName from the Expression values.
.png)
Inside info, select +-> Add subcolumn. Write lName as column name and in the Expression select LastName from the Expression values.
.png)
Now, again select Create New -> Column.
.png)
Provide skills as column name and in the Expression select array() from Expression elements and provide Skill1, Skill2, Skill3 from the Expression values as the parameters to the array(). Click Save and finish.
.png)
Step 5: Now, click +. Select Sink in Destination.
.png)
In the Sink tab, write outputfile as the output stream name.
Select derivedColumn1 as the incoming stream. Select source type as Dataset and in dataset click +New to create the source dataset.
.png)
Search for Azure Blob Storage.
.png)
Select Continue-> Data Format JSON -> Continue
.png)
Write OutputJsonFile as the name, choose the Linked Service created in step3 as the Linked service, and select employeejson container path in the File path.
.png)
Click OK.
Provide the File name in the Settings tab and select the input columns and output columns in the Mapping tab.
.png)
.png)
Step 6: In the ConvertPipeline pipeline, search for Data Flow activity in the activities and drag it to the designer surface. Select the above-created dataflow, inside the Data Flow activity.
.png)
Step 7: Validate the Pipeline by clicking on Validate All. After validating the pipeline, publish the pipeline by clicking Publish All.
.png)
.png)
Step 8: Run the pipeline manually by clicking trigger now.
.png)
.png)
Step 9: Verify that ConvertPipeline runs successfully by visiting the Monitor section in Azure Data Factory Studio.
.png)
.png)
Step 10: You can see that the uploaded CSV file is successfully converted into JSON File with Hierarchy and array by seeing the file contents inside employeejson container.
.png)
Conclusion
We have seen how we can create an ETL data pipeline to convert a CSV file into a JSON file using Azure Data Factory. We got an understanding of how ETL pipelines built using Azure Data Factory are cost-effective, secure, and easily scalable. We learned how we can build an ETL pipeline for a real-time scenario. The following were the major takeaways from the above :
1. What is ETL and how organizations can use ETL for effective decision-making.
2. How we can extract different types of data using different extraction methods?
3. We have seen how Azure Data Factory can be used to ingest data from various sources.
4. We got an understanding of how we can use pipelines, activities, linked services, datasets, etc. in Azure Data Factory.
5. We have also seen how we can easily perform data transformations using data flows.
6. We learned how to validate and publish a pipeline.
7. We understand how we can connect pipelines and dataflows with each other.
8. We got a good understanding of how we can use control flow and what are the various types of activities available in Azure Data Factory.
9. Further, we have executed an ETL data pipeline to convert a CSV file into JSON File with Hierarchy and array.
10. Apart from this, we saw how we can create containers in Azure Storage Account, Linked Service in Azure Data Factory, etc.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Full Stack developer with 2.6 years of experience in developing applications using
Azure, SQL Server & Power BI. I love to read and write blogs. I am always willing to learn new technologies, easily adaptable to changes, and have a good time
management, problem-solving, logical and communication skills
Free Courses






Very good article. best regards from Mexico City