
Sexism is discrimination or prejudice based on an individual’s gender. It has to do with the beliefs that one sex is worthier to or more valuable than the other, and the roles that each should play in society. It, like other forms of prejudice and discrimination, serves to perpetuate status and power disparities between groups in society. Although sexism can affect anybody, regardless of gender, women and girls are disproportionately affected. A rising number of developmental and educational psychologists have expressed concern about sexism directed against women and children. Considering the gravity of the situation, it’s critical to establish effective methods for detecting sexism in schools, colleges, offices, public transit, etc. To accommodate this need here is an attempt to create an app that can detect whether the sexist language exists in Spanish audios.
Things Required
- Python programming language
- Pre-trained model for ASR (Module 1)
- Pre-trained model for sexism detection for the Spanish language (Module 2)
- Gradio Interface class
- Hugging Face Spaces
Core Idea
The key concept is that we will feed the spoken audio input into the ASR module (Module1), which will convert Spanish speech into text. After that, the resulting audio transcription will be transferred to the Sexism detection module (Module 2), which will discern whether the resulting audio transcription (and hence the spoken audio) has objectionable sexist content.

Figure 1: Diagram depicting the flow of the application
👉 Module 1 (ASR module):
For converting Spanish speech to the text we will be leveraging “jonatasgrosman/wav2vec2-xls-r-1b-spanish” pre-trained model from the Hugging Face hub. This model has been trained and contributed by Jonatas Grosman. It is basically a fine-tuned version of facebook/wav2vec2-xls-r-1b on the Spanish Common Voice 8.0 dataset. When leveraging this model, one needs to ensure that the speech input is sampled at 16 kHz.
👉Module 2 (Sexism Detection):
The pre-trained model used for Sexism detection is “twitter_sexismo-finetuned-robertuito-exist2021“. It is essentially a fine-tuned version of pysentimiento/robertuito-base-uncased on the EXIST dataset.
Furthermore, we will also utilize Gradio‘s Interface class to create a UI for the machine learning model(s) and then will subsequently deploy our app on Hugging Face Spaces.
Step-by-step Implementation
The steps below will guide you through creating a Gradio app for acquiring Spanish audio transcriptions and determining whether or not the resulting transcription and hence audio contain sexist content.
Step 1: Creating a Hugging Face account and repo for the Gradio App
Please go to this website and create a Hugging Face account if you don’t already have one. After you’ve finished creating your account, go to the top-right corner of the page and click the profile icon. After that, you’ll be sent to a new page where you’ll be asked to name the repository you want to create. Give the space a name and then choose Gradio from the SDK options before clicking the “create new space” button. As a result, a repository for your app will be established. If you’re having difficulties setting it up, please watch the demonstration video I’ve included below.
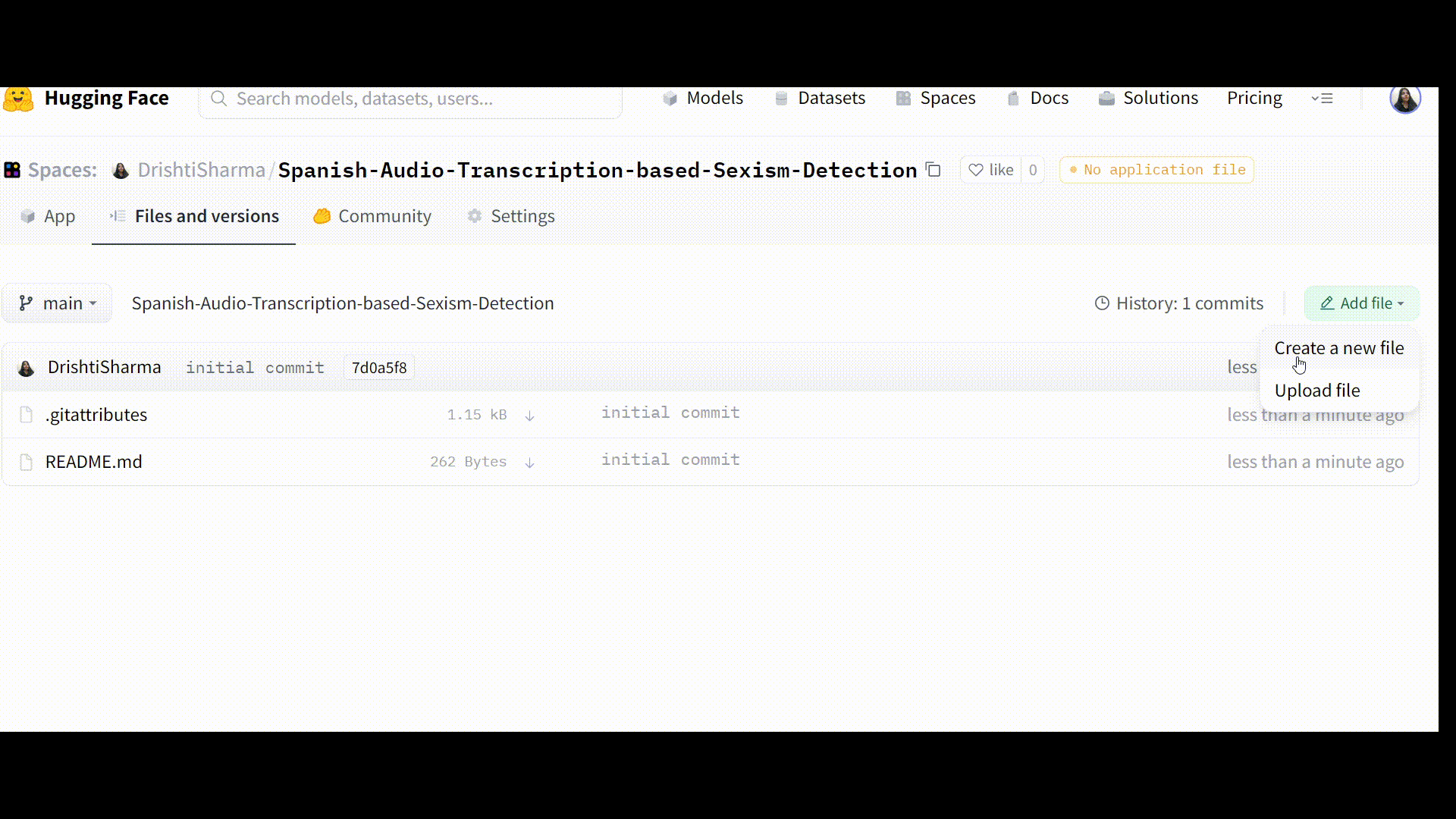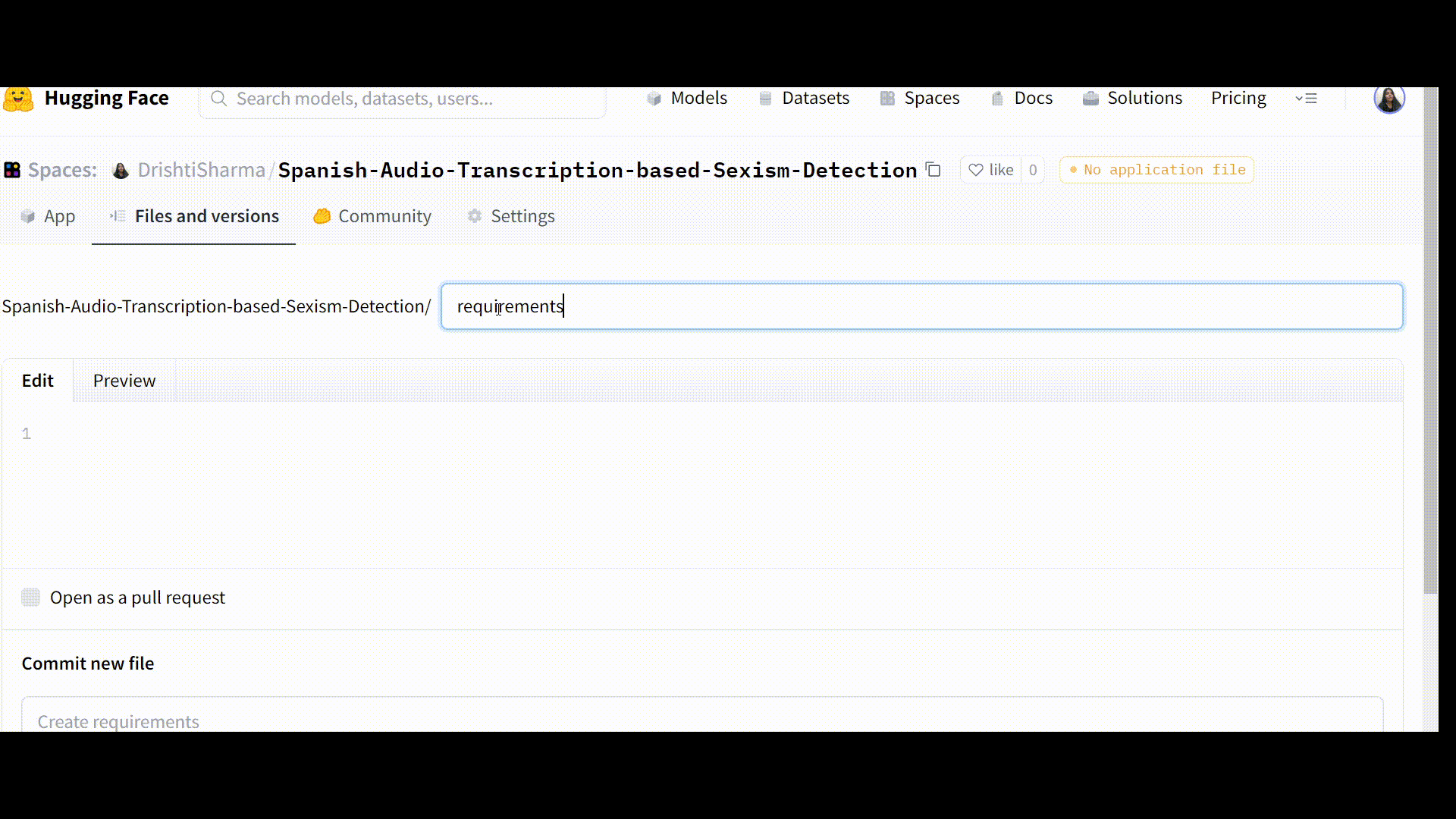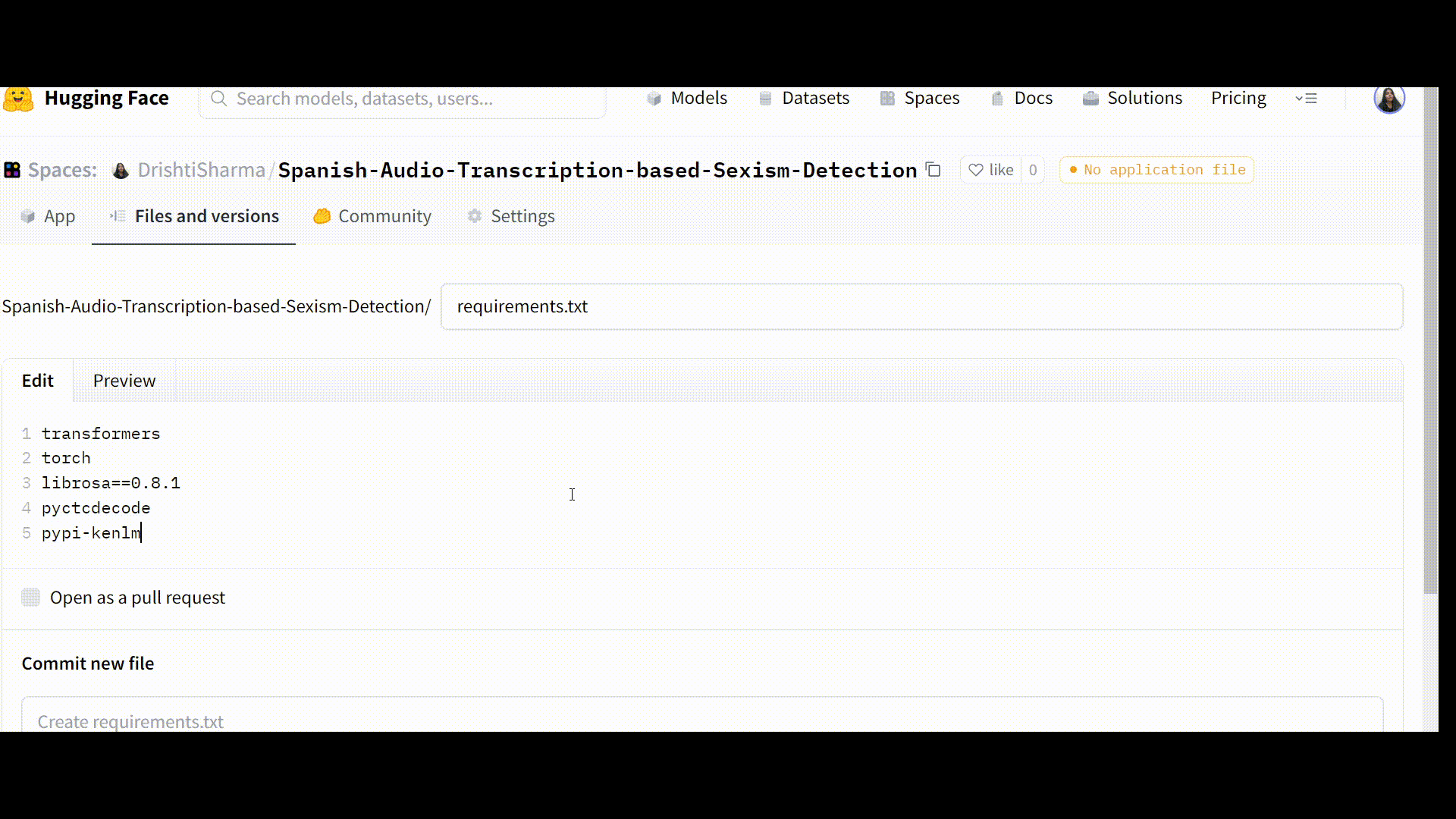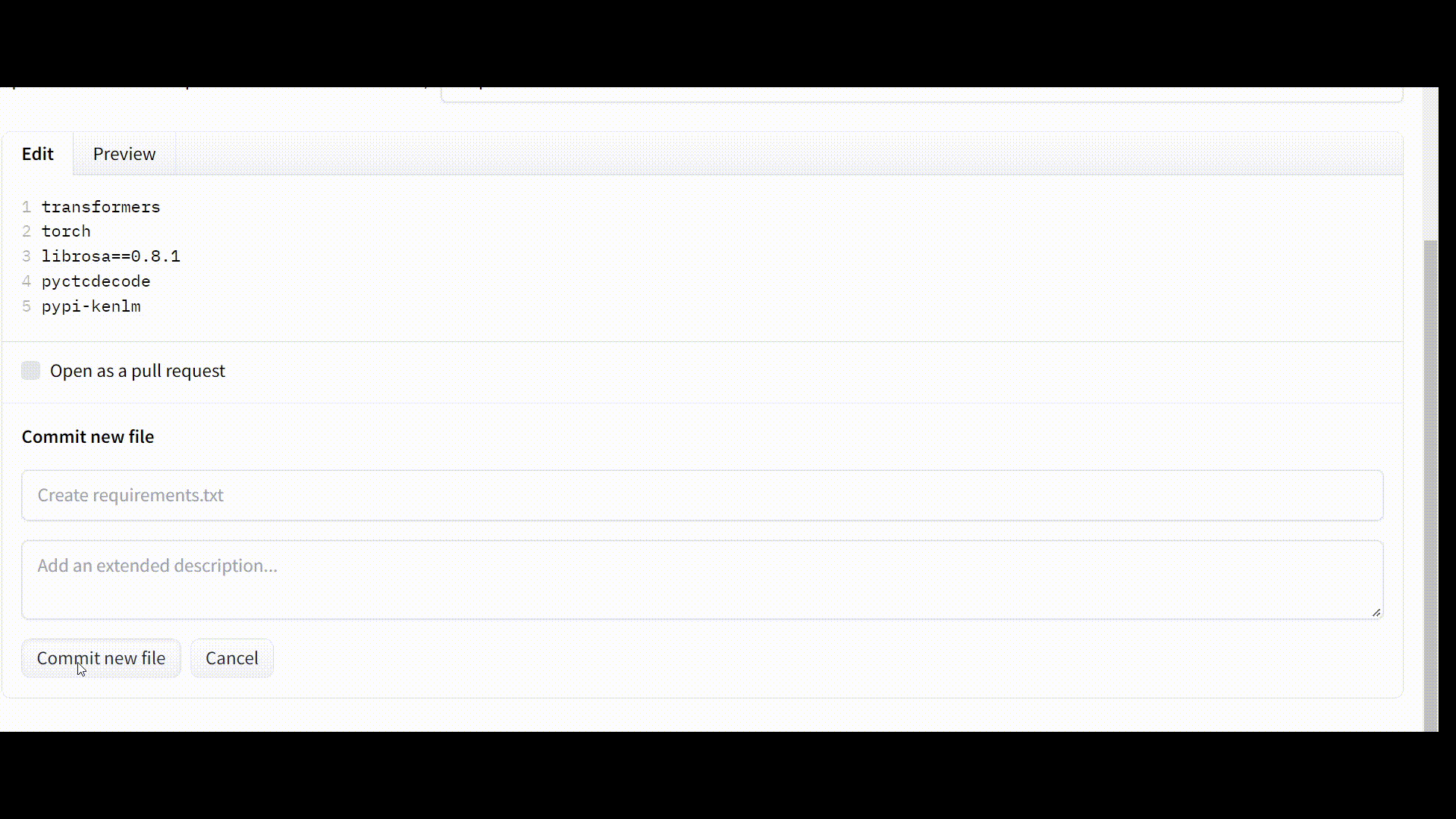
Step 2: Creating a requirements.txt file
Then select the ‘add file’ button and create a new file, name it “requirements.txt,” and list the necessary dependencies there.
Step 3: Creating app.py File
For this, I’ve broken down the code into sections for clarity and to make things easier to understand. We will go over each section of code one by one.
1. Importing necessary libraries
#importing all the required libraries import gradio as gr import librosa from transformers import AutoFeatureExtractor, pipeline
2. Defining a function for loading and correcting the speech
def load_and_fix_data(input_file, model_sampling_rate):
speech, sample_rate = librosa.load(input_file)
if len(speech.shape) > 1:
speech = speech[:, 0] + speech[:, 1]
if sample_rate != model_sampling_rate:
speech = librosa.resample(speech, sample_rate, model_sampling_rate)
return speech
3. Loading the feature extractor and instantiating the ASR pipeline
#Loading the feature extractor and instantiating the pipeline by launching pipeline()
model_name1 = "jonatasgrosman/wav2vec2-xls-r-1b-spanish"
feature_extractor = AutoFeatureExtractor.from_pretrained(model_name1)
sampling_rate = feature_extractor.sampling_rate
asr = pipeline("automatic-speech-recognition", model=model_name1)
4. Instantiating the pipeline for sexism detection
#Instantiating a pipeline for classifying the text
model_name2 = "hackathon-pln-es/twitter_sexismo-finetuned-robertuito-exist2021"
classifier = pipeline("text-classification", model = model_name2)
5. Defining a function for ASR
#Defining a function for speech-to_text conversion def speech_to_text(input_file): speech = load_and_fix_data(input_file, sampling_rate) transcribed_text = asr(speech, chunk_length_s=15, stride_length_s=1)["text"] return transcribed_text
6. Instantiating the pipeline for sexism detection
#Defining a function for sexism detection def sexism_detector(transcribed_text): sexism_detection = classifier(transcribed_text)[0]["label"] return sexism_detection
7. Defining a function that outputs the audio transcription and the result of the Sexism detection module
#Defining a function which will output Spanish audio transcription and the detected output
new_line = "nnn"
def asr_and_sexism_detection(input_file):
transcribed_text = speech_to_text(input_file)
sexism_detection = sexism_detector(transcribed_text)
if sexism_detection == "LABEL_0":
return f"Audio Transcription : {transcribed_text} {new_line} Sexism Detector Output: The input audio contains NON-SEXIST language"
else:
return f"Audio Transcription : {transcribed_text} {new_line} Sexism Detector Output: SEXIST LANGUAGE DETECTED"
8. Creating a UI to the model using gr.Interface
Next, we will utilize Gradio’s Interface class to establish a UI for the machine learning model by providing (1) the function, (2) the desired input components, and (3) the desired output components, which will allow us to quickly prototype and test our model. In our case, the function is asr_and_sexism_detection. For providing the audio input, we will use a microphone or drop an audio file. In this regard, we will use this code: for providing input. And since the intended output is a string we will use outputs = gr.outputs.Textbox(label=”Output Text”) for displaying the string output. Finally, to launch the demo, call the launch() method.
⚠️If you wish to test audio files stored locally, ensure sure they’ve been uploaded and the location to them is listed in the examples (as shown in the code snippet below). It’s worth mentioning that the components can be specified as either instantiated objects or string shortcuts.
To upload audio files, click on the following tabs in the order listed here: “Files and versions” –> “Contribute” –> “Upload Files”
inputs=[gr.inputs.Audio(source="microphone", type="filepath", label="Record your audio")] outputs=[gr.outputs.Textbox(label="Predicción")] examples=[["audio1.wav"], ["audio2.wav"], ["audio3.wav"], ["audio4.wav"], ["sample_audio.wav"]] title="Spanish Audio Transcription based Sexism Detection" description = """ This is a Gradio demo for Spanish audio transcription-based Sexism detection. The key objective is to detect whether the sexist language is present in the audio or not. To use this app, simply provide an audio input (audio recording or via microphone), which will subsequently be transcribed and classified as sexism/non-sexism pertaining to audio (transcription) with the help of pre-trained models.
**Note regarding the predicted label: LABEL_0: "NON SEXISM" or LABEL_1: "SEXISM"** Pre-trained Model used for Spanish ASR: [jonatasgrosman/wav2vec2-xls-r-1b-spanish](https://huggingface.co/jonatasgrosman/wav2vec2-xls-r-1b-spanish) Pre-trained Model used for Sexism Detection : [hackathon-pln-es/twitter_sexismo-finetuned-robertuito-exist2021](https://huggingface.co/hackathon-pln-es/twitter_sexismo-finetuned-robertuito-exist2021) """
gr.Interface( asr_and_sexism_detection, inputs=inputs, outputs=outputs, examples=examples, title=title, description=description, layout="horizontal", theme="huggingface", ).launch(enable_queue=True)
Step 4: Debugging
If you get an error, please go to the “See log” tab, which is right next to the spot where Runtime Error is shown, take a cue from the error log and fix the error.
Once the Space is up and running error-free, it should work like this:
Link to the Space: https://huggingface.co/spaces/CVMX-jaca-tonos/Spanish-Audio-Transcription-based-Sexism-Detection
Loading the built Space from the Hugging Face Spaces and recreating it locally
To load any Space from the Hugging Face Hub and recreate it locally, you can pass `spaces/` to the `Interface`, followed by the name of the Space.
Let’s load the space we built from the Hugging Face Spaces:
gr.Interface.load("spaces/CVMX-jaca-tonos/Spanish-Audio-Transcription-based-Sexism-Detectio").launch()
Limitations & Solutions
1. Limitation associated with the Pre-trained model used for ASR– The pre-trained model for ASR plays a critical role; if the audio isn’t accurately detected, the transcription will be wrong, and there is a good chance that the output of the Sexism detection module will be erroneous.
👉Solution to the aforementioned limitation: To get around this limitation, the pre-trained ASR model should be further trained on example audios that closely reflect the auditory environment in which the app will be used/tested to meet the needs.
2. Limitation associated with Module 2: On evaluating the pre-trained model used for sexism detection (Module 2) extensively and I found that in most of the scenarios this model was performing well, however, for certain inputs it wasn’t not providing correct output.
👉Solution to the aforementioned limitation: After evaluating and determining which kind of audio inputs the Sexism detection module fails to accurately output, the pre-trained model can be further trained on that kind of example audios to get reliable output.
Things to Try
1. How about creating a one-stop app for sexism detection using audio transcriptions for your country’s indigenous languages, or any other country’s indigenous languages?
2. If you find that one of the two modules (ie. ASR and sexism detection module) isn’t functioning for the use case you’re most interested in, perhaps consider training that particular model to do the targeted improvement for the class in which the model often misclassifies.
3. Try building this app using Gradio Blocks.
Conclusion
So, in this article, we learned how to create a gradio app that can detect whether audio content is sexist or not. Because this is a two-step problem (ie. speech-to-text conversion and sexism detection), the overall accuracy is dependent on each module individually. If the result of the ASR module is erroneous, the sexism detector’s output will most likely be erroneous as well. To make our app more robust, we can attempt to develop a system that takes multi-modal inputs into account while discerning whether the audio has event qualifies as sexist.
Lastly, to sum it up, we saw:
1. How to create an app for detecting whether the audio contains sexist content?
2. How to load and recreate the built space from the Hugging Face Spaces?
3. What are the potential applications of audio transcription-based sexism detection?
4. What are the limitations, and what are the ways to circumvent those limitations?
Thanks for reading. If you have any questions or concerns please post them in the comments section below. Happy learning!
References
- https://huggingface.co/hackathon-pln-es/twitter_sexismo-finetuned-robertuito-exist2021
- https://huggingface.co/pysentimiento/robertuito-base-uncased
- https://www.analyticsvidhya.com/blog/2022/01/named-entity-recognition-app-using-spacy-gradio-and-hugging-face-spaces/
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
I'm a Researcher who works primarily on various Acoustic DL, NLP, and RL tasks. Here, my writing predominantly revolves around topics related to Acoustic DL, NLP, and RL, as well as new emerging technologies. In addition to all of this, I also contribute to open-source projects @Hugging Face.
For work-related queries please contact: [email protected]





