This article was published as a part of the Data Science Blogathon.

In this article, we shall provide some background on how multilingual multi-speaker models work and test an Indic TTS model that supports 9 languages and 17 speakers (Hindi, Malayalam, Manipuri, Bengali, Rajasthani, Tamil, Telugu, Gujarati, Kannada).
It seems a bit counter-intuitive at first that one model can support so many languages and speakers provided that each Indic language has its own alphabet, but we shall see how it was implemented.
Also, we shall list the specs of these models like supported sampling rates and try something cool – making speakers of different Indic languages speak Hindi. Please, if you are a native speaker of any of these languages, share your opinion on how these voices sound, both in their respective language and in Hindi.
Basic Background on Text-to-Speech
Text-to-speech (TTS) is a broad subject, but we need to get a basic understanding of how it works in general or what are the main components.
Unlike more traditional TTS models that relied on specific linguistic information as inputs, modern TTS models usually work with text or phoneme inputs. The main components of most modern TTS systems are (even newer fully end-to-end models still have similar components inside):
- Text preprocessing module and cleaning plus some form of text to phoneme transcription, transcription, or transliteration;
- An acoustic model;
- A vocoder;
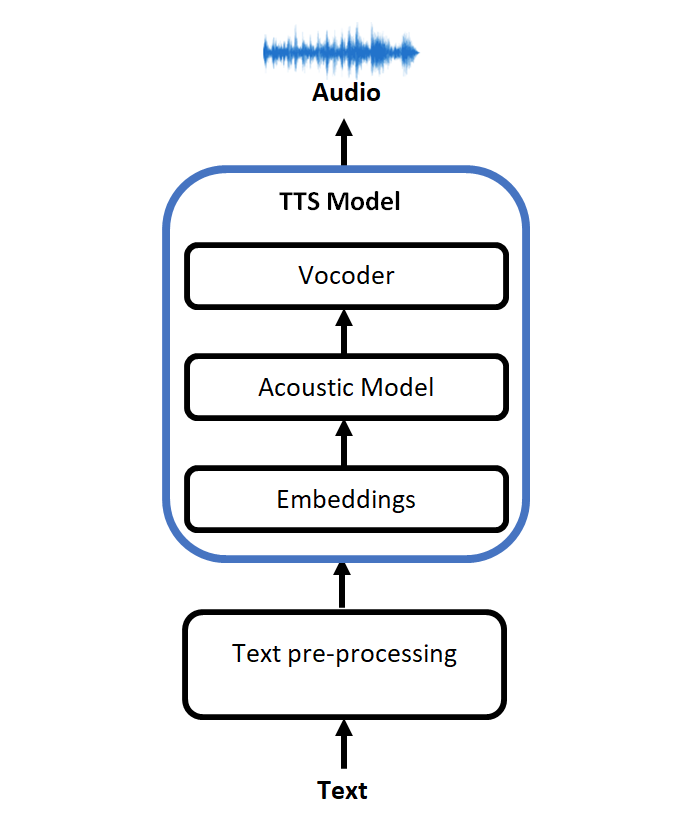
Modern TTS models typically rely on curated graphemes or phonemes as input. This input is then passed into an embedding layer that maps this alphabet to a set of tensors.
Usually, Mel Spectrograms are chosen as a modelling unit for the acoustic model and the vocoder. In simple terms, the acoustic model transfers input text embeddings into a Mel Spectrogram, which the vocoder turns into the actual audio.
There is a whole plethora of different approaches and architectures for vocoders and acoustic models (please see the paper below for a comprehensive review), but this is out of scope for this article.
Each Indic language has its own alphabet and basically, there are only 2 ways we can combine them into one unified model (of course we also can train several distinct models):
- Use some transliteration or transcription scheme;
- Combine the alphabets together and increase the number of embeddings;
The second approach is a bit problematic because the phonemes are very similar in closely related languages using such an approach may hurt the model’s generalization and convergence.
Also, each speaker should get his or her own embedding. As for the languages – it does not make sense to include language embeddings in case the number of speakers is not much larger than the number of languages.
How does it Work?
The secret sauce is that the model uses ISO romanization techniques supported by a widely used aksharamukha tool and its python package. This process is a transliteration (not a transcription) and some language’s letters have a bit different sounds, but this works well enough as you will see.
To use this tool for all of these languages, for example using python, we need to:
| Language |
Romanization function |
| hindi | transliterate.process(‘Devanagari’, ‘ISO’, orig_text) |
| malayalam | transliterate.process(‘Malayalam’, ‘ISO’, orig_text) |
| manipuri | transliterate.process(‘Bengali’, ‘ISO’, orig_text) |
| bengali | transliterate.process(‘Bengali’, ‘ISO’, orig_text) |
| rajasthani | transliterate.process(‘Devanagari’, ‘ISO’, orig_text) |
| tamil | transliterate.process(‘Tamil’, ‘ISO’, orig_text, pre_options=[‘TamilTranscribe’]) |
| telugu | transliterate.process(‘Telugu’, ‘ISO’, orig_text) |
| gujarati | transliterate.process(‘Gujarati’, ‘ISO’, orig_text) |
| kannada | transliterate.process(‘Kannada’, ‘ISO’, orig_text) |
After converting the input text to ISO, now we can try the model:
import torch
from aksharamukha import transliterate
model, example_text = torch.hub.load(repo_or_dir='snakers4/silero-models',
model='silero_tts',
language='indic',
speaker='v3_indic')
orig_text = "प्रसिद्द कबीर अध्येता, पुरुषोत्तम अग्रवाल का यह शोध आलेख, उस रामानंद की खोज करता है"
roman_text = transliterate.process('Devanagari', 'ISO', orig_text)
print(roman_text)
audio = model.apply_tts(roman_text,
speaker='hindi_male')
The created audio is a PyTorch Tensor containing a 48 kHz (the default sampling rate) audio with the generated phrase. Of course, lower sampling rates are also available.
The romanization is a lossless process, and for the majority of texts that I have tried, it can be transliterated back and forth without any errors using the aksharamukha tool.
Model Performance and Characteristics
After a bit of fiddling, prodding, and testing we can see that the model:
- Can generate audio with a sampling rate of 8 000, 24 000, or 48 000 kHz;
- Works both on CPUs and GPUs. Also, it works even on old and outdated x86 CPUs without AVX2 instructions;
- Weighs about 50 MB for all speakers and languages (yes, really!);
If we properly measure the model speed on 1 and 4 CPU threads (turns out adding 6 or more threads does not really help), we can see that it quite quick (I measured the seconds of audio generated per second):
| Sampling Rate | 1 CPU Thread | 4 CPU Threads |
| 8 kHz | 15 — 25 | 30 — 60 |
| 24 kHz | 10 | 15 — 20 |
| 48 kHz | 5 | 10 |
The model also supports SSML markdown, but it is still a bit glitchy for some tags.
Audio Samples
Now let’s generate some audio samples for each of the languages and listen to them:
https://soundcloud.com/alexander-veysov/sets/silero-tts-v3-indic
I am not a native speaker of these languages to evaluate the speech quality, but as far as TTS models go, most of these speakers sound passable. The most obvious problems can be traced to source material – mostly slow pace of speech and audio quality (some audios were noisy or upsampled from lower quality).
I asked a native speaker from India (he speaks Hindi, Telugu, Tamil and understands Malayalam, Bengali, Kannada and Gujarati to a certain extent) to evaluate the anecdotal quality, and this is what he replied:
- Hindi. The pronunciations were accurate. It sounded a bit mechanical (like reading out phrase by phrase), probably because that’s how the speakers spoke it in the dataset;
- Telugu was perfect. Was natural and smooth with accurate pronunciations;
- Tamil. The output could have been a bit smoother if it was generated for a single sentence. Nevertheless, it was still good;
- Malayalam. The pauses and phrasing were somewhat uncomfortable to hear. Female output was better, probably because it has a bit higher speed;
- Bengali was good. The female sample was perfect;
- Kannada. The male sample was perfect. The female one had awkward pauses;
- Gujarati – seemed too mechanical;
Non Hindi Speakers Speaking Hindi
Now for something extra. Let’s see what happens if non-Hindi speakers are asked to speak Hindi!
Take a listen: https://soundcloud.com/alexander-veysov/sets/silero-indic-language-transfer
And here is what a native speaker thinks:
- In general, when we use a speaker of another language Y for an input text language X, it does not sound natural. And it also loses the accent of Y when in such cases. But neither does it have the accent of X;
- It was a plain read-out of the roman text using the voice of another speaker. Although the basic voice characteristics were maintained;
- But it was accurately able to pronounce some phonemes of X which they would have never encountered for Y. So definitely there’s sharing of phonetics across languages, wherever non-ambiguous;
- The model is definitely useful when using appropriate languages for the respectively trained speakers;
- More precisely, it sounds like a person of native language Y trying hard to fluently read the script of language X, without knowing the language;
And what do you think? Do these conclusions hold? It is next to impossible for me to make these judgments apart from observing and fixing standard TTS problems shared by all non-tonal languages.
Conclusion
In this article, we have briefly touched upon the subject of how TTS models work and have shown that the ISO romanization scheme (provided by the aksharamukha tool) can serve as a decent foundation to build a universal Indic TTS model, that not only can “speak” several Indic languages, but also can make speakers “speak” a language that they originally did not even record.
This did not work for the Assamese language, because some of its romanized phonemes sounded too different compared to other languages (according to our non-native ear).
Also, a surprising finding is that the model generalizes that speakers can produce “non-native” phonemes for other languages and speak “unfamiliar” languages not fluently, but at least diligently. And if you are a native speaker of any of these languages, what do you think? Hope you liked my article on Indic languages? Share in the comments below.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.





