This article was published as a part of the Data Science Blogathon.
Introduction
Delta lakes lakehouses have gained tremendous popularity due to the support of ACID transactions and out-of-the-box features. Databricks open-sourced deltalake.io recently. Organizations are integrating delta lake into their data stack to gain all the benefits that delta lake delivers.
With an elevated demand for data engineering roles, staying up to date with the market is crucial, if not mandatory.
Let’s get right into it and strengthen our understanding of delta lake.

Frequently Asked Interview Questions
Q1. Why choose lakehouse over data lake?
Delta lake is a hybrid of a data lake and a data warehouse, and adapting delta lake’s lakehouse will deliver the best of both worlds. Harnessing the benefits of a delta lake for storing unstructured data with ACID transactions, serving BI operations, and training ML models on the data is efficient.
Delta lake presents multiple propitiatory features for handling streaming data, machine learning models, data quality, governance, and scalability.
Q2. What are the different layers of a lakehouse?
Deltalake supports multiple layers by different names – “Delta”, “multi-hop”, “medallion”, and “bronze/silver/gold” layers.
Bronze / Raw Layer: This is the docking layer for upstream data sources to ingest raw data.
The bronze layer is for storing raw files or data as it arrives. This layer is a source layer for downstream silver layers.
Silver / Aggregate Layer: This is the central layer where ETL and aggregations take place.
The silver layer is where we perform data quality checks, governance, joins, and aggregations.
Gold / Business Layer: This is the final layer where business-level use-case-specific aggregations take place.
The gold layer is the source for dashboards, analytics, and BI tasks.
Q3. What is the delta format?
Delta format is an exclusive open-source product derived from parquet data format by data bricks.
delta_format = spark.read.format("delta").load("path_to_file")
Delta format uses parquet’s schema-on-read and supports schema-on-write by providing a transactional storage layer. Delta format maintains versioning to support lineage and state. Delta format stores metadata in the _delta_log folder to support ACID transactions.
Q4. what is a transaction in delta lake?
Delta lake transaction is an entry in the _delta_log table to mark a query/operation completed successfully. Delta lake supports transactions at table level. for example,
CREATE OR REPLACE TABLE test_table (name STRING, reputation INT, count INT);
INSERT INTO test_table VALUES ('Analytics_vidya', 2, 10);
The above SQL query creates two transactions in the _delta_log folder for the CRAS statement and INSERT. If we insert multiple entries via individual insert queries, a transaction will get appended for each insert.
Multiple entries in a single insert will add one transaction log.
INSERT INTO test_table VALUES ('Analytics_vidya', 2, 10),
('Databricks', 5, 20);
All the transactions are logged as JSON files in the _delta_log folder incrementally.
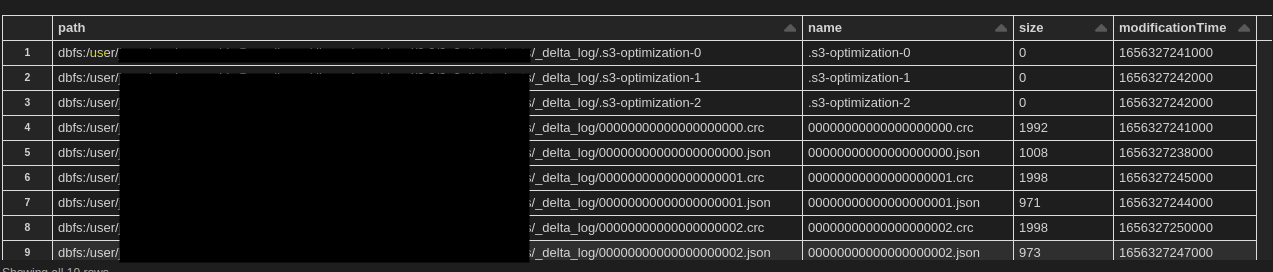
These files are tables holding information about commit info added and removed fields.

Q5. Does delta lake support upserts?
Yes, Delta lake offers upsert operations via the MERGE function.
In SQL, upserts are a means to accomplish updates and inserts simultaneously. Delta lake’s MERGE operates similarly by providing the mechanism to execute insert, update and delete operations in one go.
In SQL, upserts are a means to accomplish updates and inserts simultaneously. Delta lake’s MERGE operates similarly by providing the mechanism to execute insert, update and delete operations in one go.
MERGE INTO table_1 a USING table_2 b ON a.id=b.id WHEN MATCHED AND b.type = condition_1 THEN UPDATE SET * WHEN MATCHED AND b.type = condition_2 THEN DELETE WHEN NOT MATCHED AND b.type = "condition_3" THEN INSERT *;
Although executing multiple operations, MERGE contributes towards a single transaction in the _delta_log.
Q6. How does delta lake provide fault tolerance?
Delta lake supports checkpointing with write-ahead logs / Journaling to overcome data loss with robust recovery mechanisms and guarantees.
To achieve durability in an operation, databases and file systems offer write-ahead logs. Delta lake makes use of this feature through checkpointing.
To achieve durability in an operation, databases and file systems offer write-ahead logs. Delta lake makes use of this feature through checkpointing.
spark.readStream.table("raw_table")
.writeStream
.foreachBatch("custom_logic")
.outputMode("append")
.option("checkpointLocation", test_checkpoint)
.trigger(once=True)
.start()
In Delta lake’s context, a checkpoint is a directory where all the received data are logged as files and then processed. When a failure has been encountered, a stream or job can pick up from where the operation terminated.
Q7. What is a constraint in delta lake?
Constraints are a way to enforce checks on our data to verify the quality and integrity of the data.
ALTER TABLE test_table ADD CONSTRAINT dateWithinRange CHECK (birthDate > '1995-01-01');
Delta lake offers NULL and CHECK constraints to handle nulls and filter data during load/modification.
Q8. What is delta time travel in the lakehouse?
Time travel is a way/technique to roll back or reference a prior data version for audit or to roll back data in case of bad writes or accidental deletes.
Delta lake creates snapshots of the data and maintains versioning. All the changes to the data get logged as metadata in _delta_log.
Delta lake provides two variants to accomplish time travel. One uses version, and the other uses timestamps.
Version format-
Delta lake creates snapshots of the data and maintains versioning. All the changes to the data get logged as metadata in _delta_log.
Delta lake provides two variants to accomplish time travel. One uses version, and the other uses timestamps.
Version format-
SELECT count(*) FROM test_table VERSION AS OF 5 SELECT count(*) FROM test_table@v
Timestamp format-
SELECT count(*) FROM test_table TIMESTAMP AS OF "2022-07-01"
Q9. What is Autoloader?
The autoloader is Databricks’ recommended way to handle streaming data efficiently and with ease. Autoloader offers a way to read data from cloud object storage as it arrives, resulting in limited REST calls to the cloud storage with added security.
spark.readStream.format("cloudFiles")
.option("cloudFiles.format", "json")
.schema(schema)
.load("path_to_file")
The autoloader provides many exceptional features, such as schema inference and evolution.
Q10. How do you tackle the small file problem and skewness in delta lake?
Delta lake is packed with tons of optimizations to handle many know issues that we encounter with big data.
Most of the time to make sure that our cluster resources utilization and our aggregations are getting executed optimally, it is necessary to make sure we partition our data.
But, Databricks recommends avoiding partitioning the data until necessary because delta lake takes care of the partitions based on their cardinality using proprietary algorithms(auto-optimize).
Databricks performs multiple scans on partitions to check if the data can be compacted further based on small file size to collate small files and avoid skewness in data.
delta.autoOptimize.autoCompact = true delta.autoOptimize.optimizeWrite = true
We can manually perform optimization and use Zorder to index our files to merge small files into a manageable partition.
OPTIMIZE test_table ZORDER BY id
ZORDER is a mechanism used by delta lake data-skipping algorithms for scanning a set of files to Colocate column information and compact files based on an index.
Bonus Questions
1. What is VACCUM?
Continuous data upserts get logged in the _delta_logs folder with a versioned copy.
SET spark.databricks.delta.retentionDurationCheck.enabled = false; VACUUM test_table RETAIN 0 HOURS; SET spark.databricks.delta.vacuum.logging.enabled = true;
VACCUM is useful for truncating files from the directory that are no longer valid after a period.
Default Vaccum period to 7 days. Overwrite this carefully in production to avoid data loss.
2. What is ZORDER?
ZORDER is a mechanism used by delta lake data-skipping algorithms for scanning a set of files to Colocate column information and compact files based on an index.
3. How to roll back or restore data?
Delta lake offers a way similar to time travel to restore the files which are deleted or modified accidentally.
RESTORE TABLE test_table TO VERSION AS OF 8;
4. What is a Dry run?
The dry run is a way to perform checks before executing the operation. A dry run returns a list of files set to delete without deleting them.
VACUUM test_table RETAIN 0 HOURS DRY RUN;
Conclusion
Delta lake can be a forefront for creating genius offerings to eliminate the barriers between Data engineering and Date science. Understanding the features and learning your way through is how you can tackle any problem and face the interviews. The features highlighted above are the most commonly asked queries. Advanced concepts are proving to be very useful in organizations, providing exclusive functions to accomplish a complex integration or triggering task with ease.
Takeaways:
- Lakehouse is being adapted everywhere as it is proving to be a viable replacement to data lake from both cost and architectural standpoint.
- Delta format is derived from parquet to act as an optimal and feature-rich alternative.
- Transactions are an interesting concept supporting ACID guarantees and allowing recovery from the previous state.
- OPTIMIZE and ZORDER are very useful in handling partitioned data and small compact files for better query and performance
- The AUTOLOADER is a proprietary feature in delta lake to support streaming jobs without any overhead.
- VACCUM and DRY RUN can be a great way to reduce the logs and visualize the query results without logging them in transactions.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.





