This article was published as a part of the Data Science Blogathon.
Introduction
Apache Oozie is a distributed workflow scheduler for performing and controlling Hadoop tasks. MapReduce, Sqoop, Pig, and Hive jobs can be easily scheduled with this tool. It allows for the sequential enforcement of several difficult tasks to finish a bigger task. It is also possible to set up a job sequence so that many jobs can run at the same time.By starting workflows, it directs the Hadoop execution engine to carry them out. The present Hadoop infrastructure may be used by Oozie for load balancing, fail-over, etc. It’s broken up into two sections:
Hadoop jobs like MapReduce, Pig, etc. are used in a workflow engine to store and run workflows. Predefined schedules and data availability are used by the coordinator engine to carry out workflow jobs. Oozie uses callbacks and polling to identify job completion. As soon as an Oozie job is started, a unique URL is assigned and notified when the work completes. Whether the callback URL is not invoked, Oozie can poll the job to see if it has been completed.
Oozie Workflow
There are control flow nodes and action nodes in Apache Oozie Workflow.
Action Nodes:- The Action nodes are the triggers to carry out computation activities. Oozie provides out-of-the-box support for several kinds of Hadoop activities, including Hadoop MapReduce, Hadoop file system, Pig, etc. In addition, Oozie provides support for system-specific tasks, like SSH, HTTP, and email.
Control Flow Nodes:- The Control flow nodes are the things that tell the workflow where it starts and where it ends (start, end, fail). Also, control flow nodes provide a way to control the workflow’s execution path (decision, fork, and join)
The following control flow nodes initiate or terminate workflow enforcement in the Apache Oozie process:
- Start Control Node – The start node is the initial node to which an Oozie workflow job switches and the entrance point for a workflow job. Every workflow definition in Apache Oozie must include a start node.
- End Control Node – The end node is the final node that an Oozie workflow job moves to, and it signifies that the workflow job has successfully finished. When a workflow job reaches the end node, it successfully completes and its status is updated to SUCCESSFUL. Every workflow definition in Apache Oozie must include an end node.
- Kill Control Node – The kill node enables workflow jobs to terminate themselves. When a workflow job reaches the kill node, it terminates with an error, and its status changes to KILLED.
.png)
Interview Questions on Apache Oozie
1. What are the critical characteristics of Apache Oozie?
The key characteristics of Apache Oozie are:
- Oozie has a client API and command-line interface that Java applications may use to begin, manage, and monitor tasks.
- Using its Web Service APIs, jobs may be managed from anywhere.
- Oozie provides the ability to carry out jobs that are regularly scheduled to run.
- Oozie is capable of sending email reminders when tasks are done.
2. Which important EL functionalities are available in the Oozie workflow?
Oozie’s workflow includes the following important EL functionalities.
- wf: name() This function is used to return the workflow application’s name.
- wf: id () This function returns the job id of the active workflow job.
- wf:errorCode (String node) This function returns the error code of the action node now performing.
- wf:lastErrorNod() This function returns the name of the most recently completed action node.
3. What are the several control flow nodes provided by Apache Oozie workflows that direct workflow execution?
The following control flow nodes regulate the workflow’s execution route in an Apache Oozie workflow.
- Decision Control Nodes – Like a switch-case statement, the decision control node lets a workflow choose which enforcement route to take.
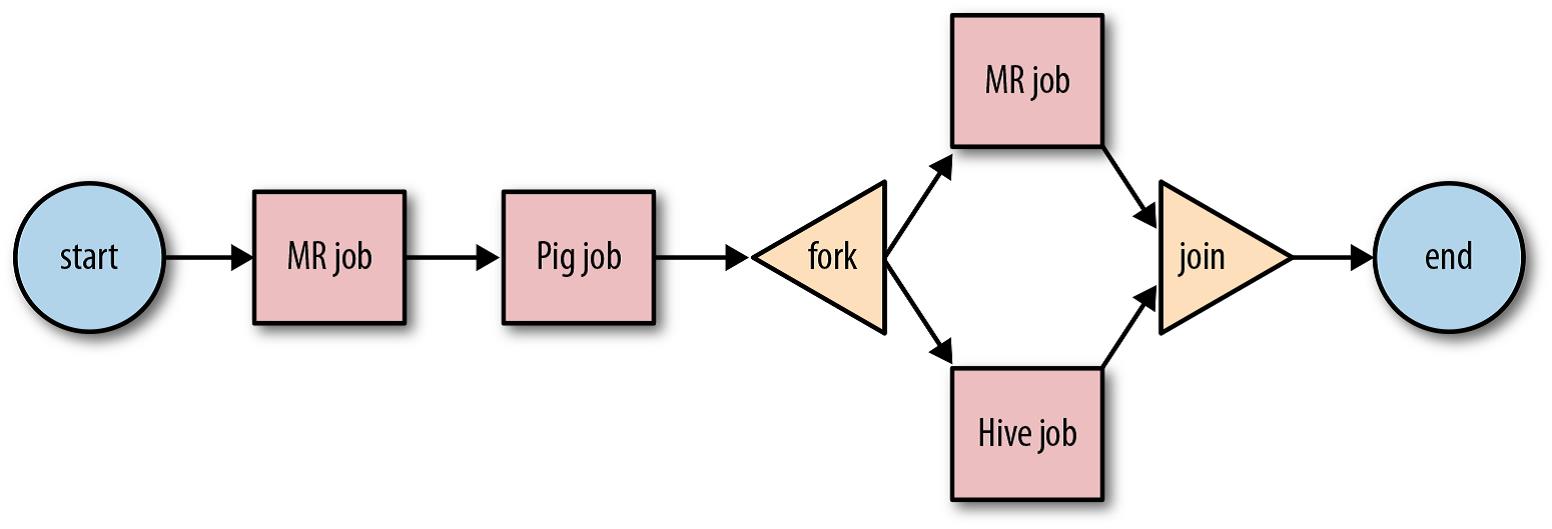
- Fork and Join Control Nodes – As illustrated below, fork and join control nodes are used in pairs and functions. The fork node divides a single execution path into several concurrent enforcement pathways. The join node awaits the arrival of all concurrent execution paths from the appropriate fork node.
4. What are the actions supported in Oozie?
Apache Oozie supports the following action node types.
- MapReduce Action
- Java Action
- Pig Action
- FS Action
- Sub-Workflow Action
- Hive Action
- DistCp Action
- Email Action
- Shell Action
- SSH Action
- Sqoop Action
5. What purposes does Apache Oozie serve?
Apache Oozie provides a fantastic way of managing many tasks. There are several kinds of jobs that customers wish to plan for later enforcement or activities that require a specific execution order. With Apache Oozie, these kinds of executions may be simplified. Using Apache Oozie, the administrator or the user may carry out several independent processes in parallel, run the jobs sequentially, or control them from anywhere, making it a precious tool.
6. Explain Oozie Coordinator?
Oozie Coordinator jobs are recurring Oozie Workflow jobs triggered by time and data availability. Additionally, Oozie Coordinator may oversee several processes that are dependent on the outcomes of future workflows. The result of one process becomes the input of the next workflow. This sequence stands as a “data application pipeline.”
Oozie handles coordinator jobs at a defined timezone with no Daylight Savings Time (usually UTC); this timezone is characterized as the “Oozie processing timezone.” The Oozie processing timezone determines coordinator task start/end times, job pause timings, and the initial instance of datasets. Additionally, each coordinator dataset instance URI template is resolved to a DateTime inside the Oozie processing timezone.
Usage of Oozie Coordinator is frequently divided into three distinct categories.
- Small: One coordinator application including embedded dataset definitions.
- Medium: Comprised of a single common dataset description and a few coordinator apps
- Large: Consisting of many standard dataset definitions and various coordinator applications.
7. Describe the different action nodes supported by the Oozie workflow.
The list of action nodes that the Apache Oozie workflow supports and aids in computing tasks are shown below.Map Reduce Action: This action node launches the Map-Reduce job in Hadoop.
Pig Action: This node initiates the Pig process from Apache Oozie.
FS Action (HDFS). This action node facilitates the Oozie process to manage all files and directories associated with HDFS. Additionally, it supports the mkdir, moves, chmod, delete, chgrp, and touchz commands.
Java Action: In the Oozie workflow, the sub-workflow action node aids in the enforcement of the public static void main(String[] args) function of the main java class.
8. Name the database that Oozie uses by default to store job ids and job status?
Oozie uses the Derby database to store job ids and job status.
9. Can you explain the different stages of an Apache Oozie workflow job?
The Apache Oozie workflow job experiences the following states.
- PREP: Preparation is the basic prerequisite of an Oozie workflow job. In this state, the workflow job has been defined but has not proceeded yet.
- RUNNING: When an Oozie workflow proceeds, it enters the RUNNING state. While the workflow is in a RUNNING state, it does not achieve its end state, ends in error, or is temporarily paused.
- SUSPENDED: Oozie workflow jobs move to the SUSPENDED state when they are no longer active. Once halted, the workflow will stay thus until it is restarted or terminated.
- SUCCEDED: When a running Oozie job reaches the end node, it changes to the SUCCEEDED state.
- KILLED: When an administrator kills a running, created, or suspended workflow job, the job switches to a KILLED state.
- FAILED: RUNNING Oozie jobs become FAILED if the workflow job fails with an unexpected error during enforcement.
10. Describe Oozie Bundle briefly.
Oozie Bundle might be a higher-level Oozie abstraction that batches a group of coordinator apps. The user can start/stop/suspend/resume/rerun at the bundle level, resulting in a more streamlined and effective operational control. In particular, the Oozie Bundle system enables the user to design and enforce a group of coordinator apps, sometimes described as a knowledge pipeline. During a bundle, there is no explicit dependency between coordinator apps. A user might, however, use the information reliance of coordinator applications to create an implicit data application pipeline.
Oozie supports workflow enforcement.
o Time Dependency (Frequency)
o Data Dependency
Conclusion
This article discusses a scheduler system named Apache Oozie used to run and manage Hadoop’s distributed jobs.
These Apache Oozie Interview Questions can assist you in preparing for your subsequent personal interview. These are the most often asked questions by interviewers during Oozie-related interviews. You must review these Apache Oozie interview questions before attending an interview, as they will aid you in reviewing the ideas and bolster your confidence.
This article also addresses the following additional points:
- Workflow of Oozie and the many nodes made available by Apache Oozie Workflow.
- EL functionalities in the Oozie Workflow.
- Features and purpose of Apache Oozie.
- Various actions are performed by Apache Oozie and so on.
Are you preparing for Data Science job role interviews? If yes, head on to our blog for more questions.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Hello, my name is Prashant, and I'm currently pursuing my Bachelor of Technology (B.Tech) degree. I'm in my 3rd year of study, specializing in machine learning, and attending VIT University.
In addition to my academic pursuits, I enjoy traveling, blogging, and sports. I'm also a member of the sports club. I'm constantly looking for opportunities to learn and grow both inside and outside the classroom, and I'm excited about the possibilities that my B.Tech degree can offer me in terms of future career prospects.
Thank you for taking the time to get to know me, and I look forward to engaging with you further!





