This article was published as a part of the Data Science Blogathon.
Introduction to Data Warehouse
In today’s data-driven age, a large amount of data gets generated daily from various sources such as emails, e-commerce websites, healthcare, supply chain and logistics, transaction processing systems, etc. It is difficult to store, maintain and keep track of such data as it grows exponentially with time and comes in various file formats such as text, parquet, CSV, etc. Due to the above reasons, a data warehouse is needed as it will analyze a huge amount of data and produce useful data insights with the help of data visualizations and reports.
A data warehouse aggregates data from various sources into a central, consistent data repository to generate business insights and helps stakeholders in effective decision-making.
Big Query is a server-less, fully managed, multi-cloud data warehouse Platform as a Service (PaaS) service provided by Google Cloud Platform that helps to get valuable business insights from big data. Big Query also provides a query engine for SQL to write SQL queries and has built-in machine learning capability. We can develop a highly scalable data warehouse using Google Big Query.

Source: https://kochasoft.com/fr/uncategorized-fr/google-bigquery-datawarehouse-for-s4-hana-system-3/
In this guide, I’ll show you how to build a data warehouse that will store data from two sources, i.e., mobiles data and mobile brands scraped data from Flipkart, and query the data stored in the data warehouse to get valuable insights.
Data warehouse Working
A data warehouse aggregates data from various sources into a central, consistent data repository to generate business insights and helps stakeholders in effective decision-making. Data inside a data warehouse is loaded hourly, daily, or periodic from multiple applications and systems and does not change within that period. After that, data gets processed to convert into the format of already existing data in the data warehouse.
The processed data is stored in the data warehouses and later used by the organizations for effective decision-making. The data processing procedure depends upon the data format. The data could be unstructured, semi-structured, or structured based on the source from which it is coming such as transaction processing systems, healthcare, supply chain, etc.
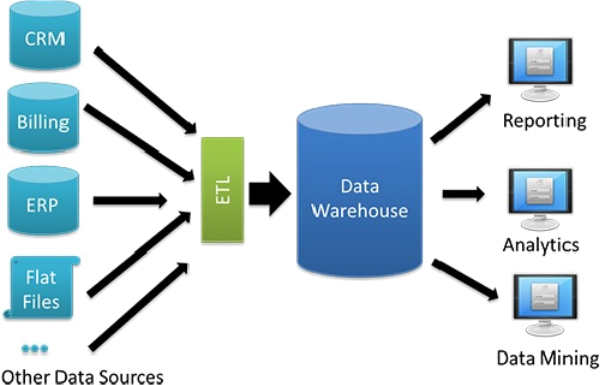
Source: https://databricks.com/glossary/unified-data-warehouse
Well-designed data warehouses improve query performance and deliver high-quality data. Data warehouse enables data integration and helps make smarter decisions using data mining, artificial intelligence, etc.
Today, almost all the major cloud service providers provide data warehouse tools. Cloud-based data warehouse tools are highly scalable, provide disaster recovery, and are available on a pay-as-you-go basis. Some cloud-based data warehouse tools are Google Big Query, Amazon RedShift, Azure Synapse, Teradata, etc.
Now, we will see the details about Google Big Query.
Getting Started with Google Big Query
Big Query is a scalable, multi-cloud, distributed, fully managed, and server-less data warehouse Platform as a Service (PaaS) provided by Google Cloud Platform. Big Query is a central repository that collects data from various sources like Cloud Storage, Cloud SQL, Amazon S3, Azure Blob Storage, etc.
Using federated queries, we can directly access the data from external sources and analyze that data in Big Query without importing that data. Big Query also provides a query engine for SQL to write SQL queries and has built-in machine learning capability. We can develop a highly scalable data warehouse using Google Big Query. Big Query provides prescriptive and descriptive analysis, data storage for storing data, and centralized data management and computer resources.
Data from various sources are stored inside table rows and columns in Capacitor columnar storage format inside Google Big Query storage, as that format is optimized for performing analytical queries. Big Query provides full support for ACID transactions. Big Query ML provides geospatial analysis, business intelligence, machine learning, and predictive analytics capability, ad-hoc analysis, etc. Tools such as Looker, Data Studio, etc., provide business intelligence support in Google Big Query.
Identity and access management (IAM) is used to secure resources with the help of the access model. IAM provides data security and governance. Jobs run in Big Query to export, query, copy or load data are secured using roles that restrict the user or group from performing various activities. Storage is separated from the compute engine in Big Query, making it highly flexible while designing the large-scale data warehouse.

Source: https://cloud.google.com/bigquery
We have got a good understanding of the storage, security, and analytics mechanisms in Google Big Query. Now, let’s look at the details of Big Query architecture.
Big Query Architecture
Big Query has a scalable, flexible, and server-less architecture, due to which the storage and computing resources utilized in developing the data warehouse could be scaled independently.
Big Query also provides a built-in engine for SQL, which improves query performance for large data and has built-in machine learning capability that helps stakeholders make smarter decisions and design better marketing and promotional strategies. The above features of the Big Query architecture help the customers develop the data warehouse cost-effectively without worrying about infrastructure, security, database operations, and system engineering.
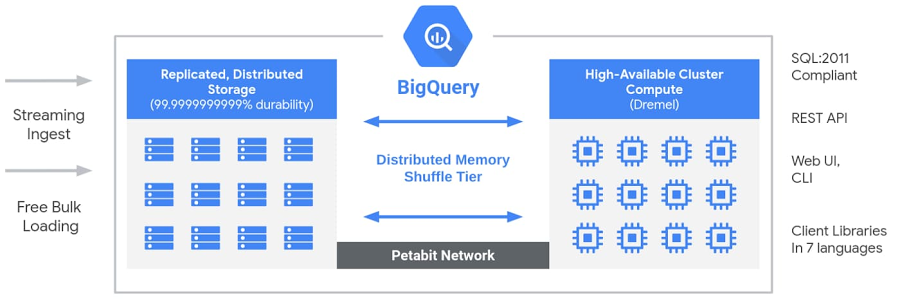
Source: https://cloud.google.com/blog/products/data-analytics/new-blog-series-bigquery-explained-overview
Low-level infrastructure technologies offered by Google, such as Borg, Dremel, Colossus, and Jupiter, are internally used by the Google Big Query architecture. A large number of multi-tenant services are accompanied by low-level infrastructure technologies to provide scalability and flexibility to the Big Query architecture.
Colossus: Big Query uses Colossus for data storage purposes. Colossus performs data recovery, replication, and distributed management operations to ensure data security.
Dremel: For performing computation operations internally, Big Query uses Dremel. Dremel is a multi-tenant cluster that converts SQL queries into execution trees for executing the queries.
Jupiter: Storage and computing resources use the Jupiter network to communicate.
Borg: Borg does orchestration by performing automated configuration, management, and coordination between services in Big Query.
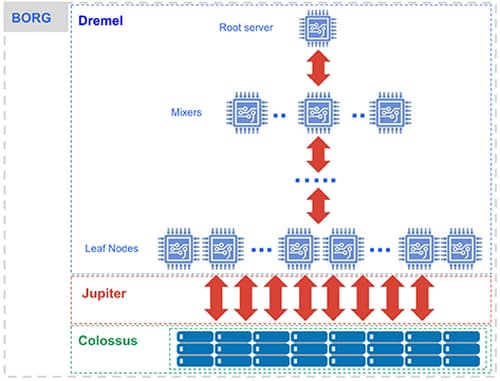
Source: https://cloud.google.com/blog/products/data-analytics/new-blog-series-bigquery-explained-overview
Advantages of using Google Big Query
Below are some advantages of using Google Big Query
a. Enhanced business intelligence capabilities: Using Big Query, we can integrate data from multiple sources. Whether it’s some external data source or services present inside GCP, data of various formats from all the sources could be easily managed in Big Query. This data is then processed, formatted, and later used by the organizations for effective decision-making through enhanced business intelligence capabilities.
b. Data consistency and enhanced data quality: Data from various sources are stored inside table rows and columns in Capacitor columnar storage format after compressing data using a compression algorithm inside Google Big Query storage as that format is optimized for performing analytical queries. Big Query provides full support for ACID transactions. The compressed data takes less space. Thus, enhanced data quality and data consistency is achieved using data compression and Capacitor columnar storage format in Big Query.
c. Scalability and real-time performance: Using federated queries, we can directly access the data from external sources and analyze that data in Big Query without importing that data. Also, the amount or number of data sources could be easily increased or decreased. Apart from that, Big Query Omni allows you to analyze the data stored in Amazon S3 or Azure blob storage with the flexibility to replicate data when necessary. This all improves the real-time performance and scalability of the data warehouse.
d. Security: Identity and access management (IAM) is used to secure resources with the help of the access model. IAM provides data security and governance. Jobs run in Big Query to export, query, copy or load data are secured using roles as roles restrict the user or group from performing various activities. Thus, a secured data warehouse is developed in Big Query with the help of Identity and access management and roles.
e. Disaster recovery & fault tolerance: Data stored in Big Query is replicated across different regions. In case of any unwanted circumstances, data can be easily recovered using Recovery Time Objective (RTO) and Recovery Point Objective (RPO). Data in Big Query is highly consistent, durable, easily recoverable, and has better fault tolerance and disaster recovery mechanism.
Big Query Use Case Scenarios
Below are some scenarios in which Google Big Query can be used:
1. E-commerce recommendation system: Google Big Query can be used for developing an e-commerce recommendation system. Customer review data could generate product recommendations using Big Query’s artificial intelligence, machine learning, and predictive analytics capability. Apart from this, customer Lifetime, shopping patterns, etc., can also be predicted using Vertex AI, which may help e-commerce organizations to plan their promotional and marketing strategies.
2. Migrating data warehouses: For accelerating real-time insights, organizations may prefer to migrate their existing data warehouses to the Google Big Query. Other data warehouses like Snowflake, Redshift, Teradata, etc., can be easily migrated to Big Query for better security and scalability.
Source: https://cloud.google.com/blog/topics/developers-practitioners/how-migrate-premises-data-warehouse-bigquery-google-cloud
3. Supply chain analytics: For better risk management, predicting equipment availability and labor shortage it is best to use advanced predictive capabilities. For predicting things like equipment availability, labor & skill requirements, production site raw material availability, etc., based on the already existing data, Big Query ML could be used. Thus, production site raw material availability, labor & skill requirements, etc., could be managed efficiently using Google Big Query.
Building Data Warehouse in Big Query for E-commerce Scenario
Now, you are familiar with what is Google Big Query, how its internal architecture works, the benefits of using Big Query, and the use cases in which Big Query is recommended.
Let’s see how we can develop a data warehouse for an e-commerce scenario.
We are assuming that we have an e-commerce company that stores data from two different sources, i.e., mobiles data and mobile brands scraped data from Flipkart, based on the type of details the company needs to store for performing peer performance analysis.
We want to develop a data warehouse in Big Query to aggregate data from all these sources, perform some operations, query the data to get valuable insights and make effective decisions.
Follow the below steps to create a data warehouse in Big Query:
Step 1: Create a new Project in GCP
For organizing and managing resources in an efficient manner, the project is created in GCP.
To start working in GCP to create a data warehouse, you can either create an account on GCP or use the Big Query sandbox.
To use the sandbox, visit the below link and log in with your Google account:
https://console.cloud.google.com/bigquery
Now, follow the below steps:
1. After logging in to the sandbox, click Create New Project.
.png)
2. Provide the details about the project, such as folder name or parent organization and project name and click on CREATE button. The project will get created successfully. Now, you can select and view the project in the sandbox.
Step 2: Create a dataset in Big Query
1. Click Resource-> Big Query-> ProjectName -> Create dataset.
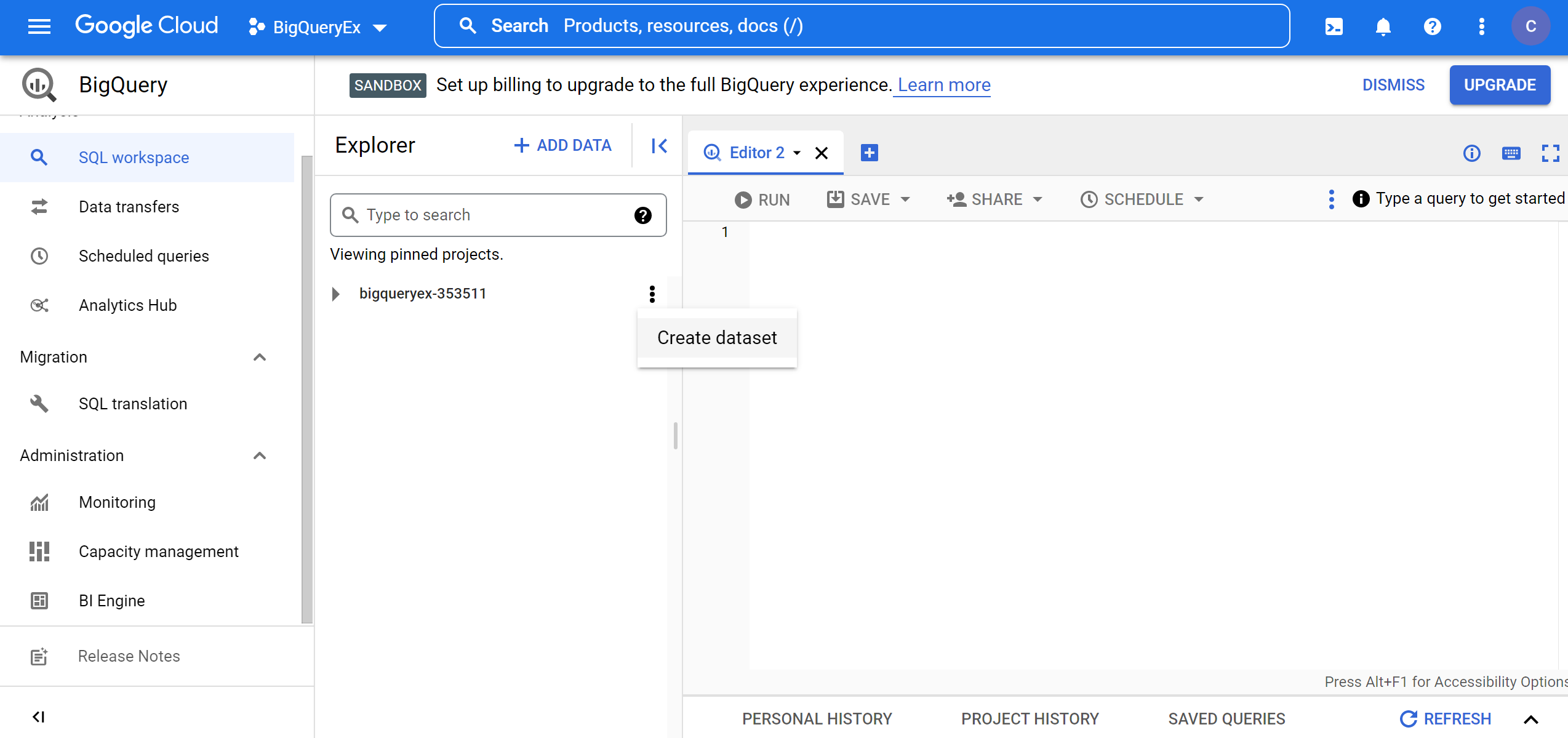
2. Now, a dialog with the title Create dataset opens. Provide ecommerce as a Dataset ID, select the location nearest to you as Data location, keep all other options at their default values and click CREATE DATASET button.
.png)
3. Now, visit https://www.kaggle.com/datasets/devsubhash/flipkart-mobiles-dataset and download the Flipkart mobiles dataset. You will find two files named Flipkart_mobile_brands_scraped_data.csv and Flipkart_Mobiles.csv. Download both the files and save them locally.
Step 3: Creating tables inside the dataset in Big Query
1. Now, Click eCommerce -> Create table.
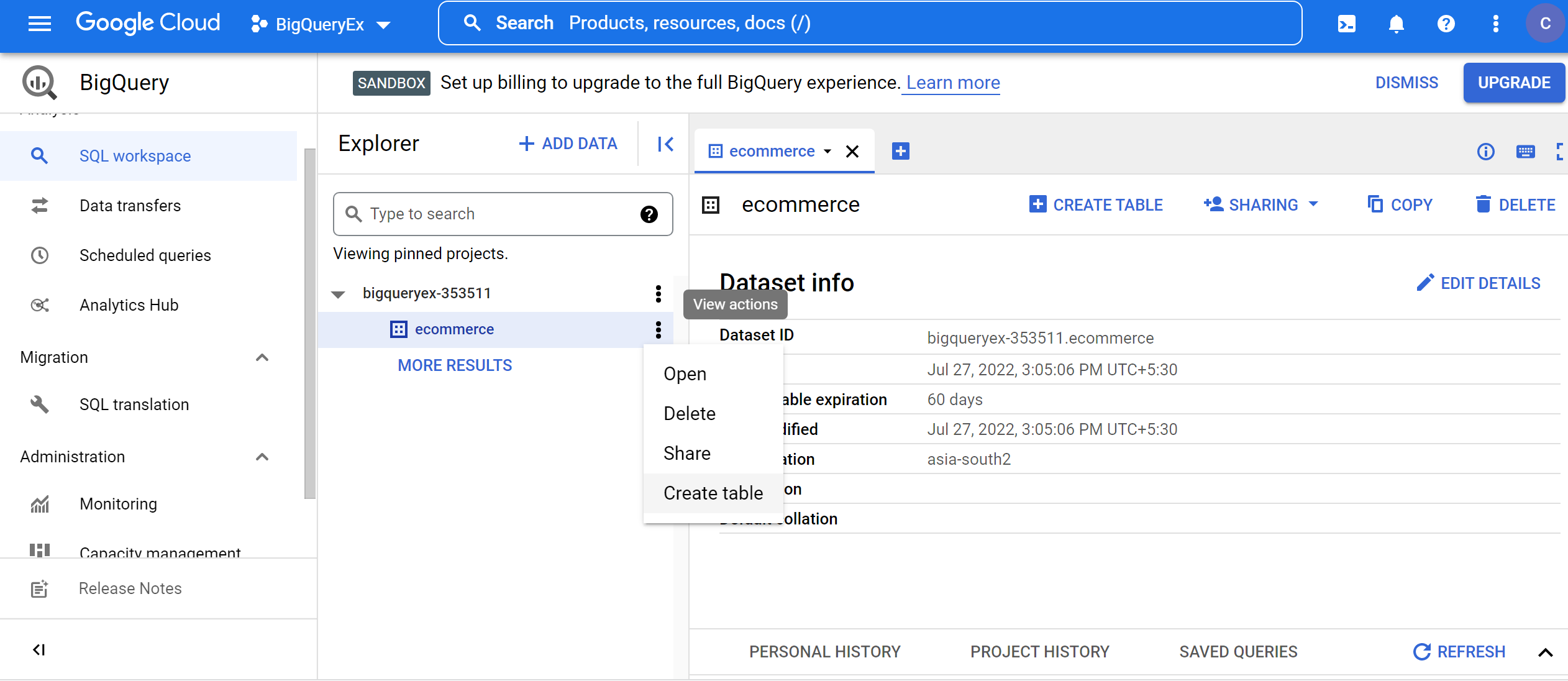
2. Select create table from upload, then choose the Flipkart_mobile_brands_scraped_data.csv file downloaded from Kaggle, select CSV as File Format, keep the project and dataset name as the default, provide table name as Mobile_scraped_data, table type as Native table, schema as auto-detect and keep default partition and cluster settings, then click CREATE TABLE button.
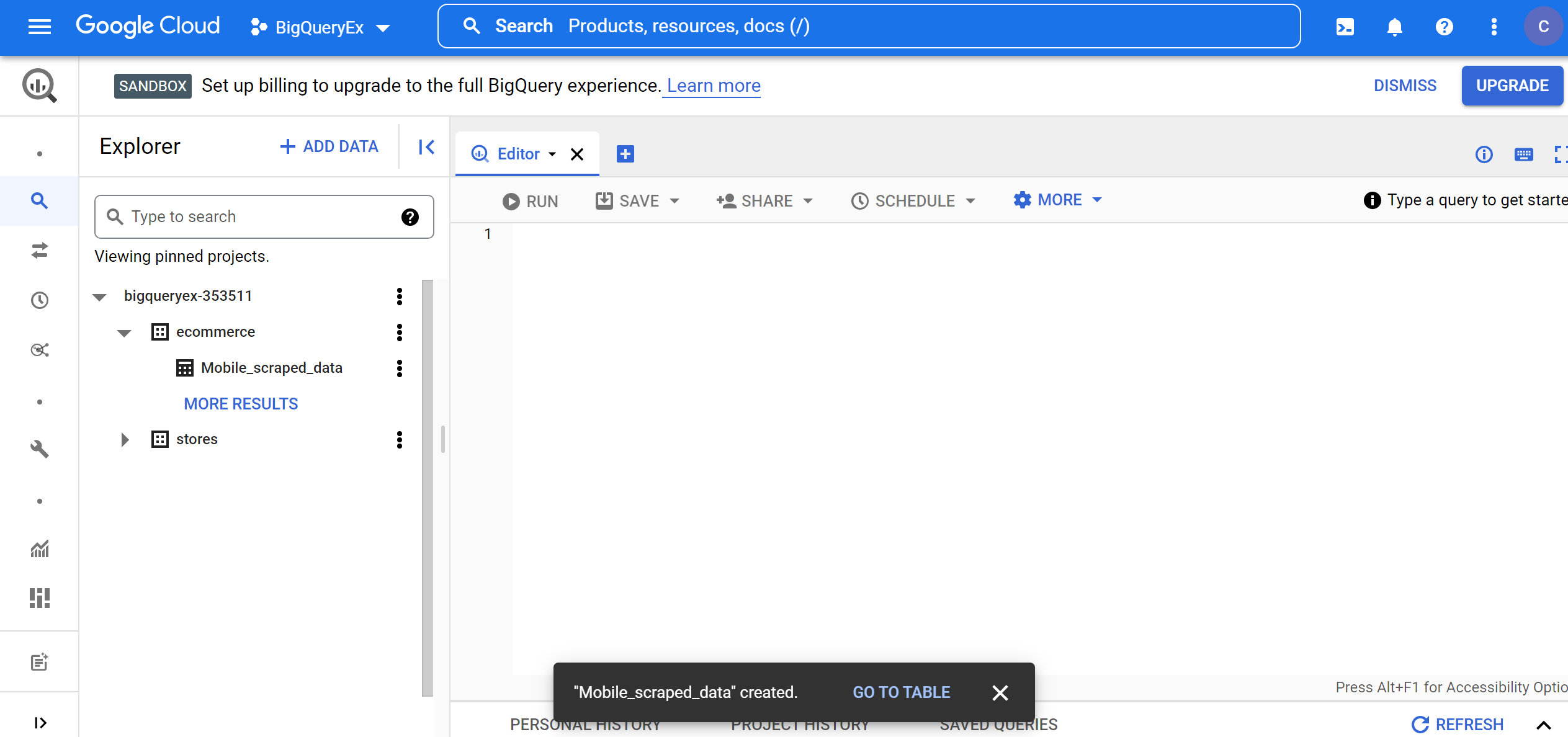
3. Go to the created table by clicking the GO TO TABLE button. We can see details about row access policies, schema, and edit schema if you want to change in schema format.
4. Now, again, Click eCommerce -> Create table.
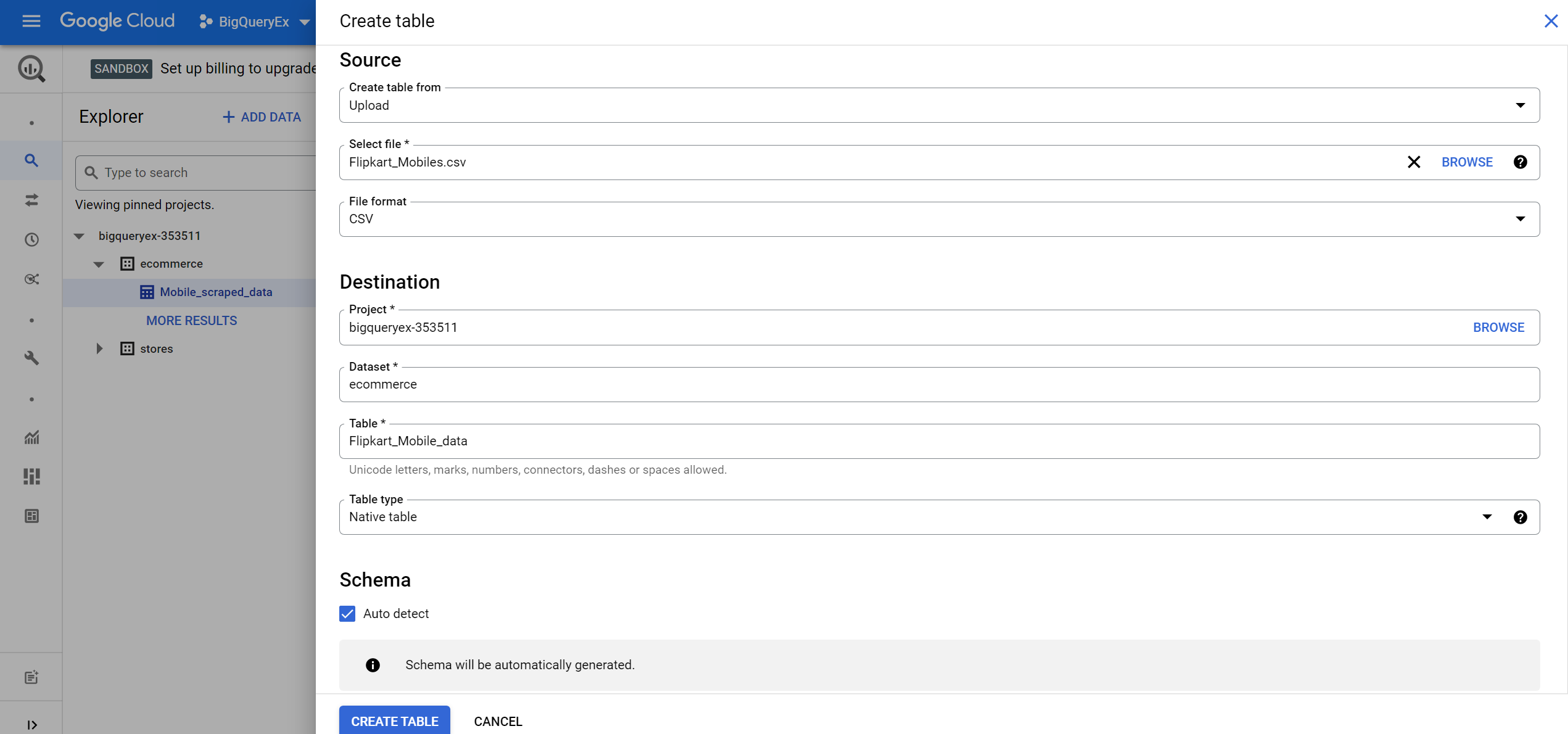
5. Select create table from upload, then choose the Flipkart_Mobiles.csv file downloaded from Kaggle, select CSV as File Format, keep the project and dataset name as the default, provide table name as Flipkart_Mobile_data, table type as Native table, schema as auto-detect and keep default partition and cluster settings, then click CREATE TABLE button.
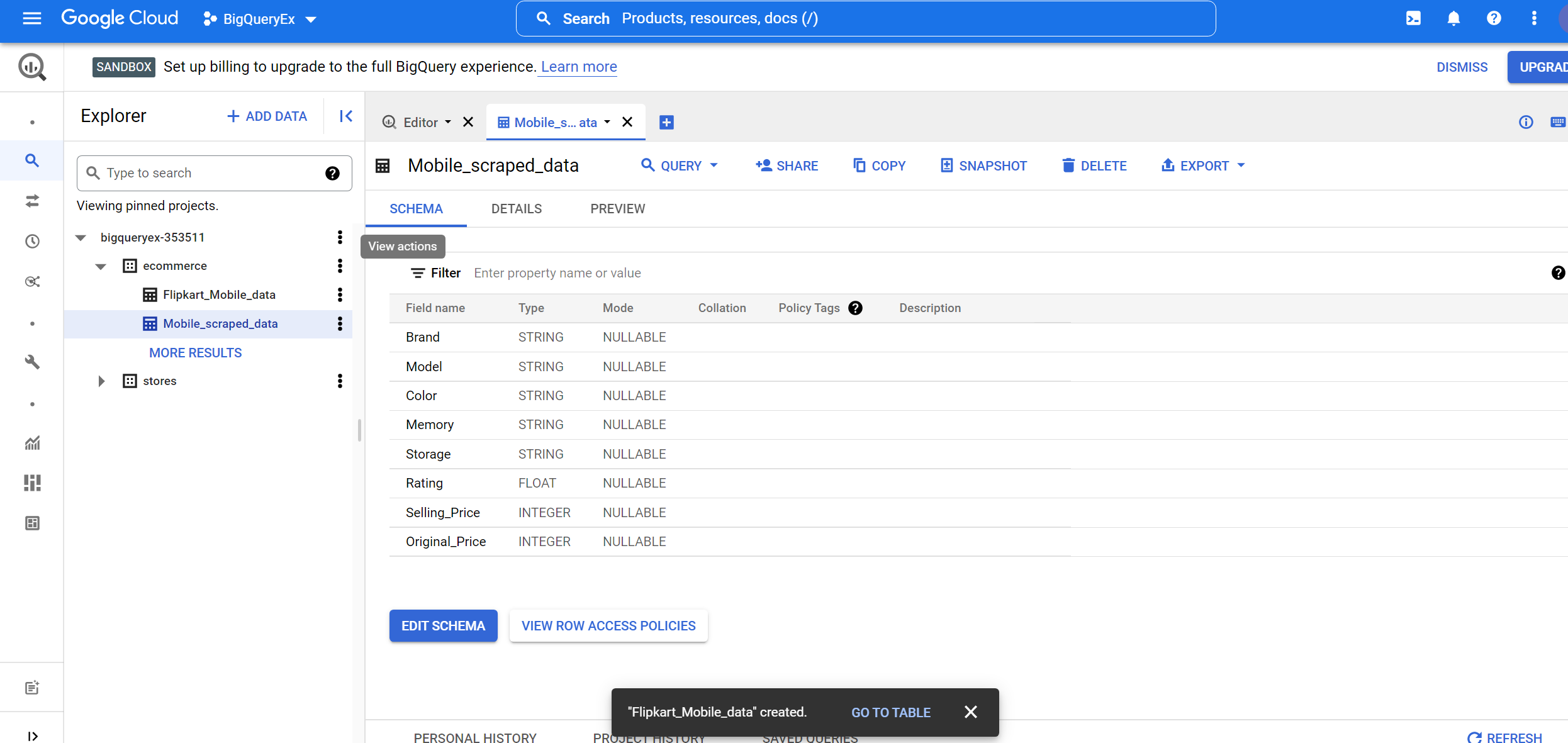
6. Go to the created table by clicking the GO TO TABLE button. We can see details about row access policies, schema, and edit schema if you want to change the schema format.
Step 4: Analyzing data format and schema of imported tables
We can analyze the data format and schema of imported tables with the help of schema format and by seeing the data already in the tables. Follow the below steps to do so:
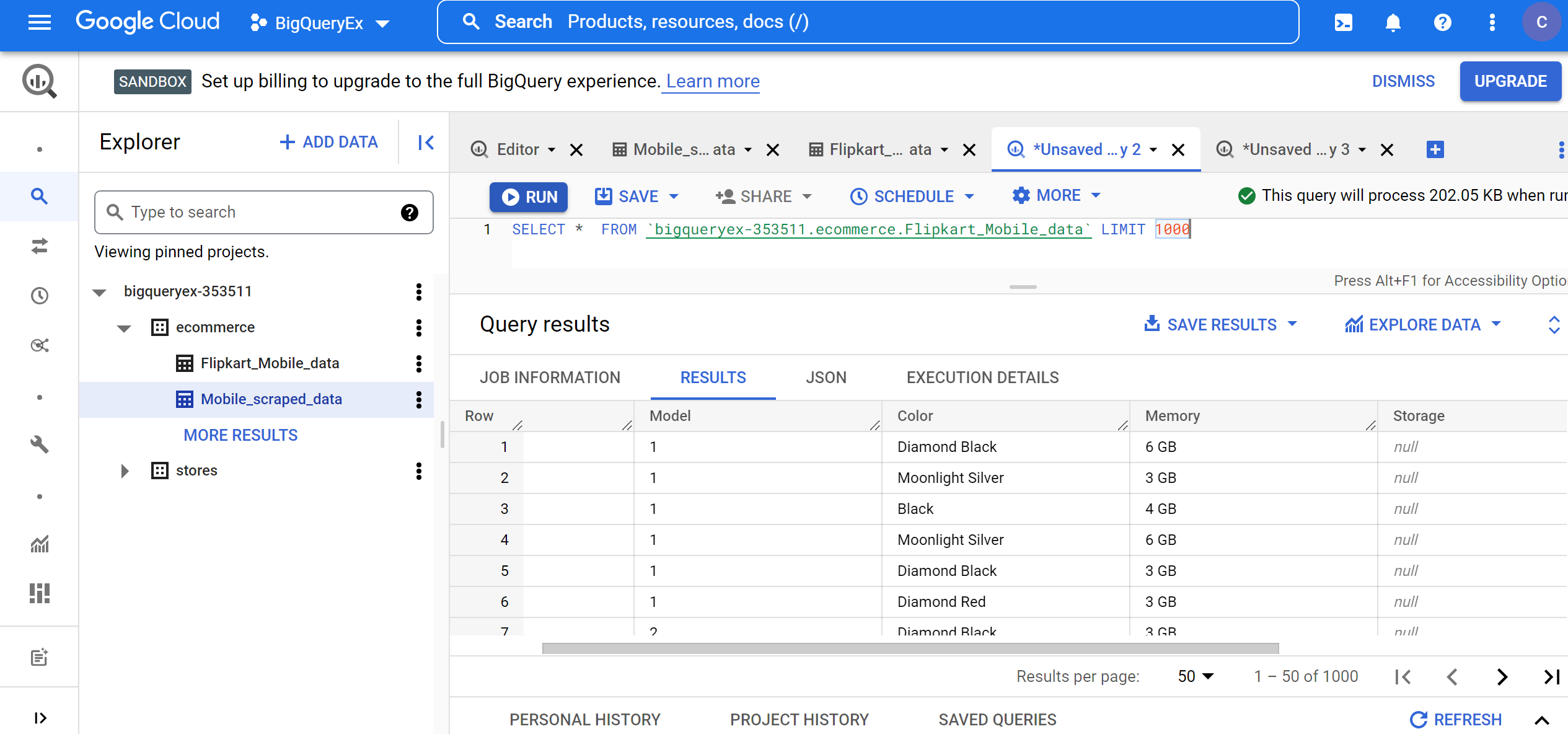
1. To see 1000 records from the Flipkart_Mobile_data table, run the below query:
SELECT * FROM `bigqueryex-353511.ecommerce.Flipkart_Mobile_data` LIMIT 1000
2. To see 1000 records from the Mobile_scraped_data table run the below query:
SELECT * FROM `bigqueryex-353511.ecommerce.Mobile_scraped_data` LIMIT 1000
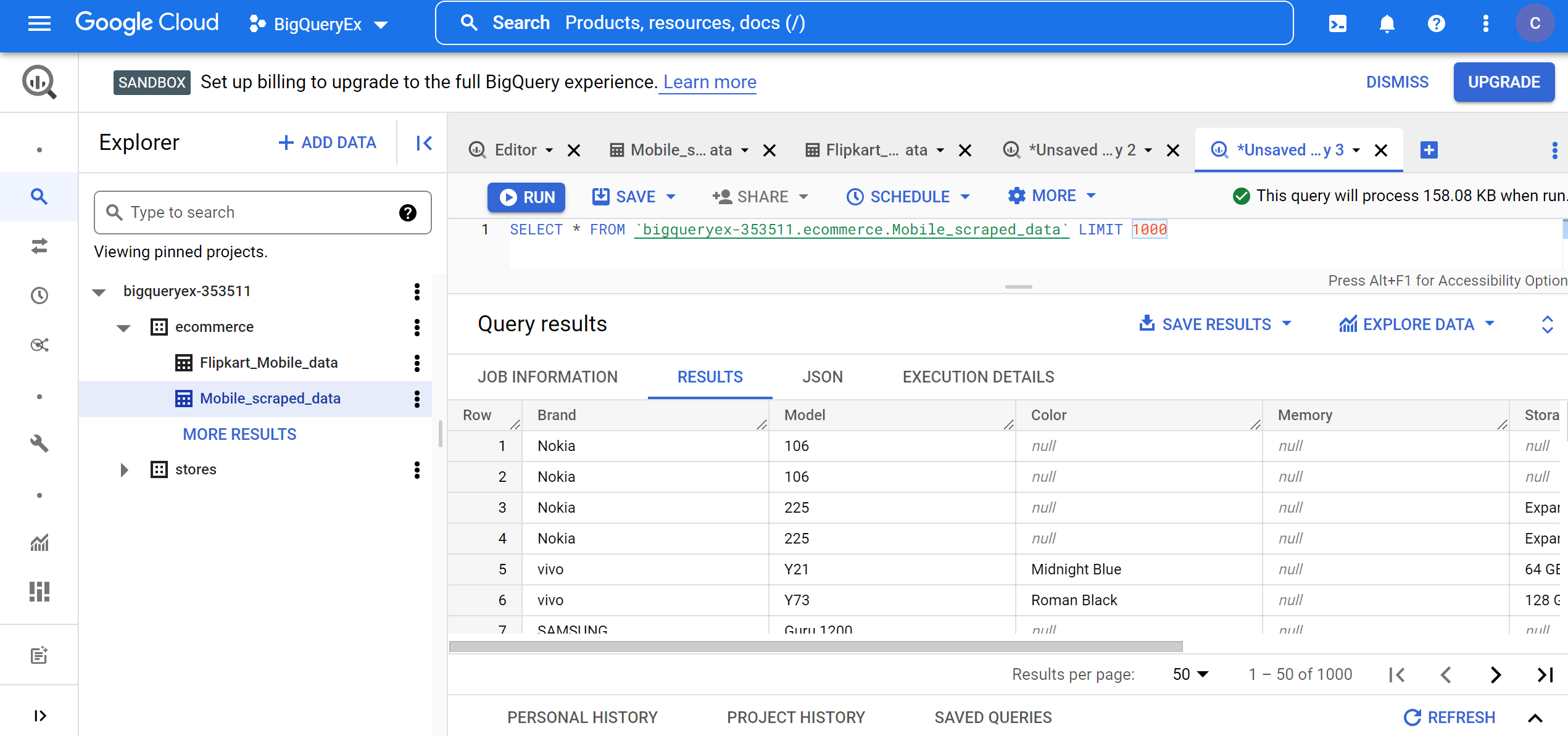
From the schema, we can see that the tables Mobile_scraped_data and Flipkart_Mobile_data have the same data schema, i.e., both have the fields Brand, Model, Color, Memory, Storage, Rating, Selling_Price, and Original_Price.
Step 5: Aggregating data from the imported tables to create a new table in Big Query
Now, we will perform data aggregation by creating a new table by performing the UNION operation on the above two imported tables while keeping a single record in case of duplicate records. To perform the above operation, use the below query:
CREATE TABLE ecommerce.Mobiles AS SELECT * FROM `bigqueryex-353511.ecommerce.Flipkart_Mobile_data` UNION ALL SELECT * FROM `bigqueryex-353511.ecommerce.Mobile_scraped_data`
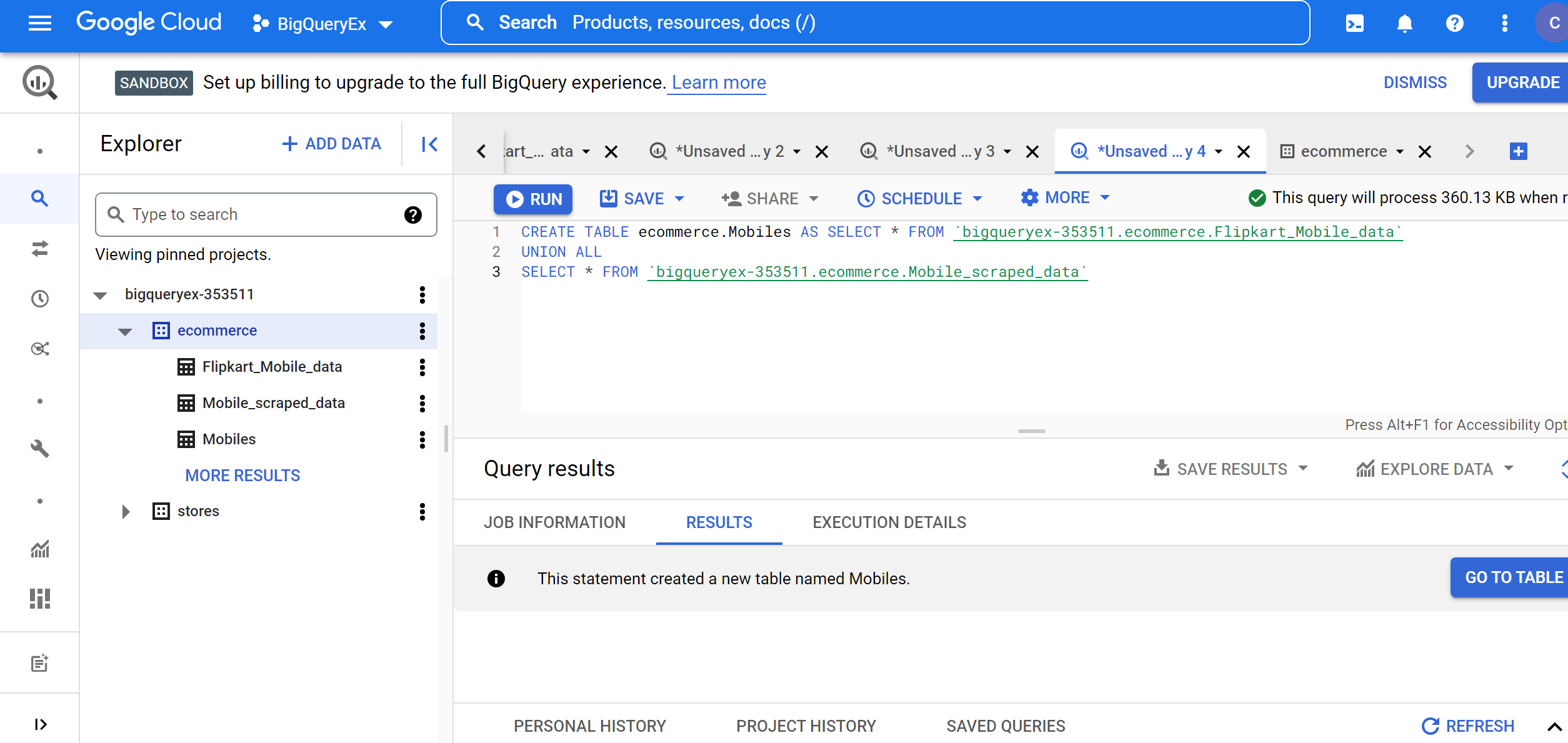
Now, delete the Flipkart_Mobile_data and Mobile_scraped_data tables to avoid data redundancy using the below queries:
DROP TABLE `bigqueryex-353511.ecommerce.Mobile_scraped_data` DROP TABLE `bigqueryex-353511.ecommerce.Flipkart_Mobile_data`
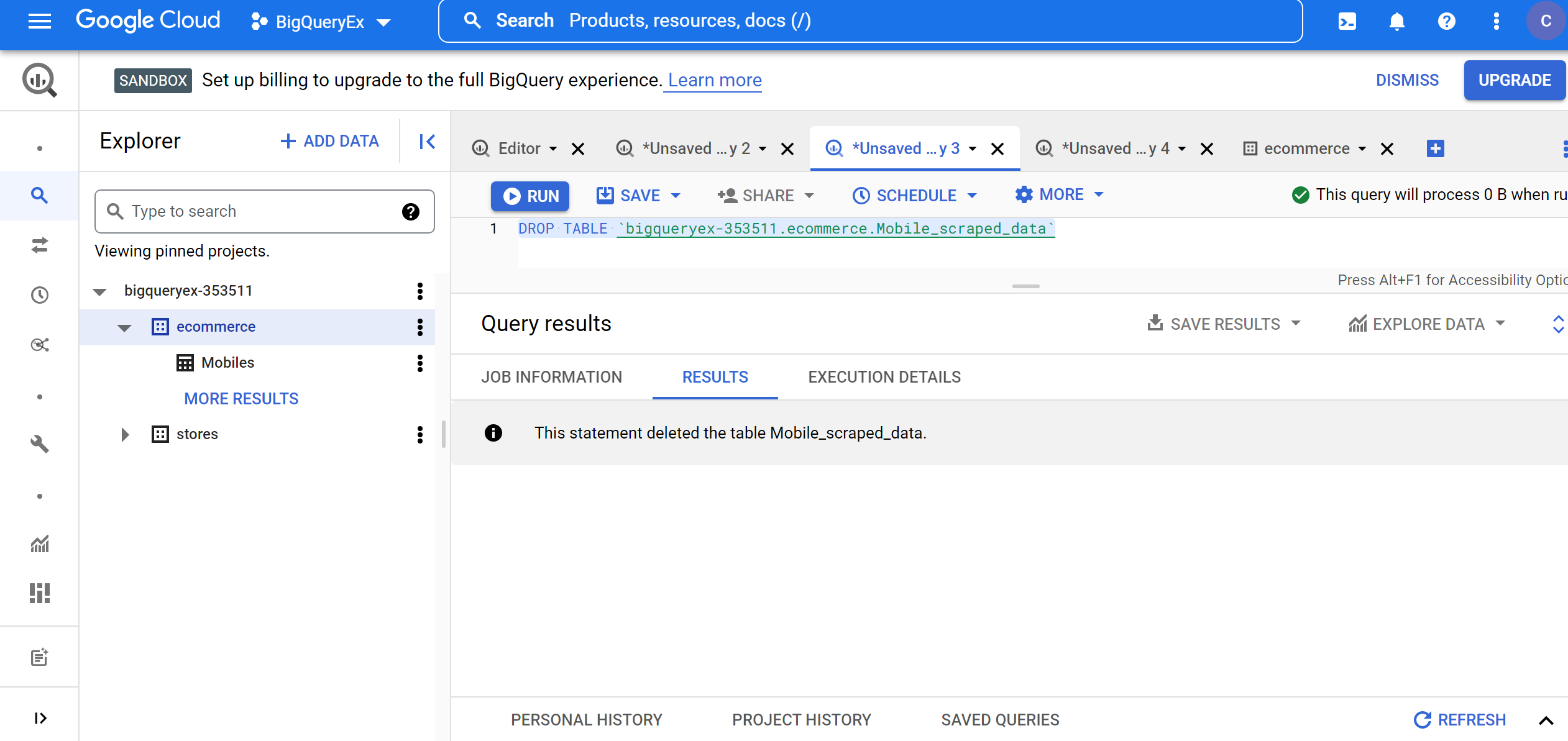
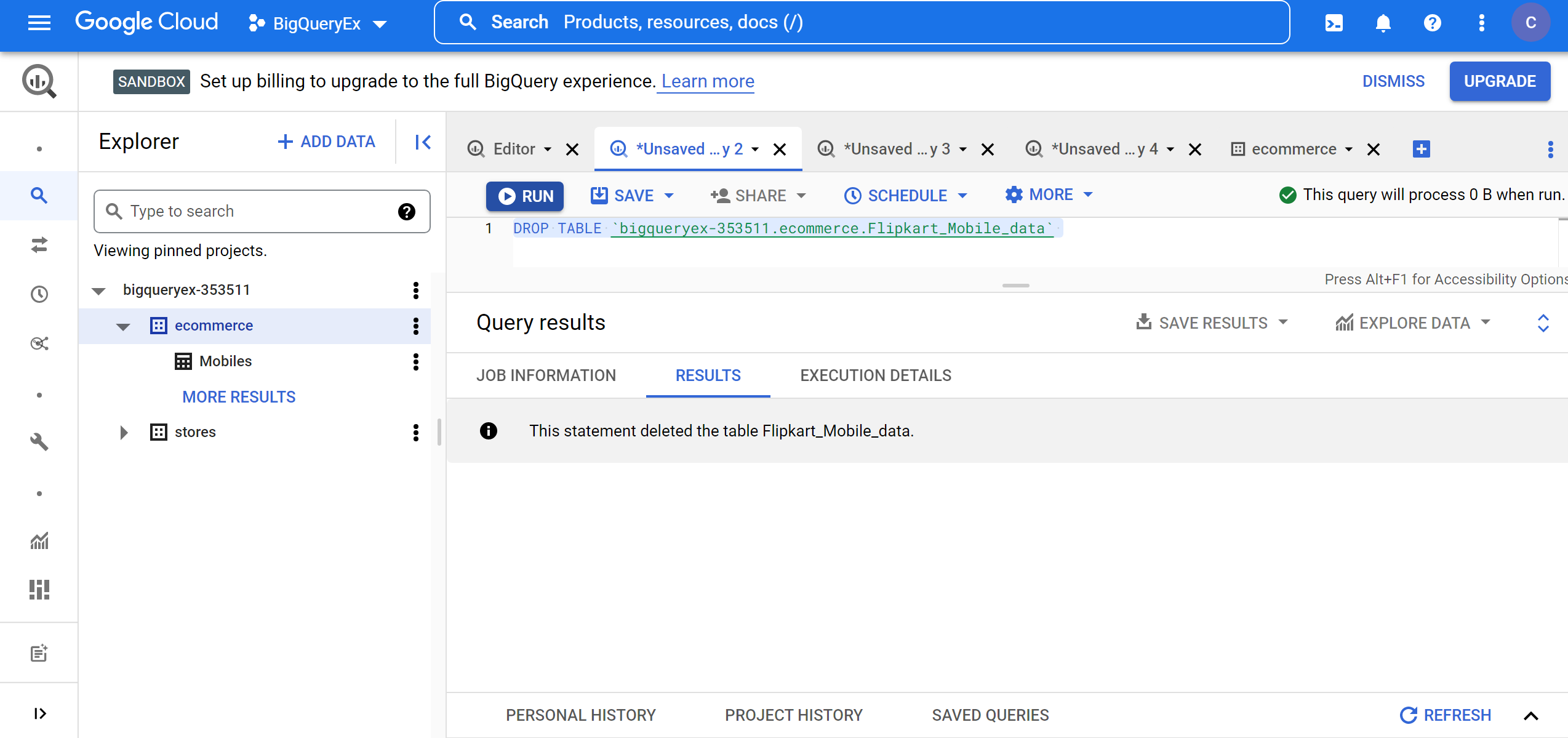
Now, we have aggregated data from two sources. Let’s analyze the aggregated data to get some useful insights.
Step 6: Getting useful insights by querying aggregated data in Big Query
We will perform querying on aggregated data to get below discussed useful insights:
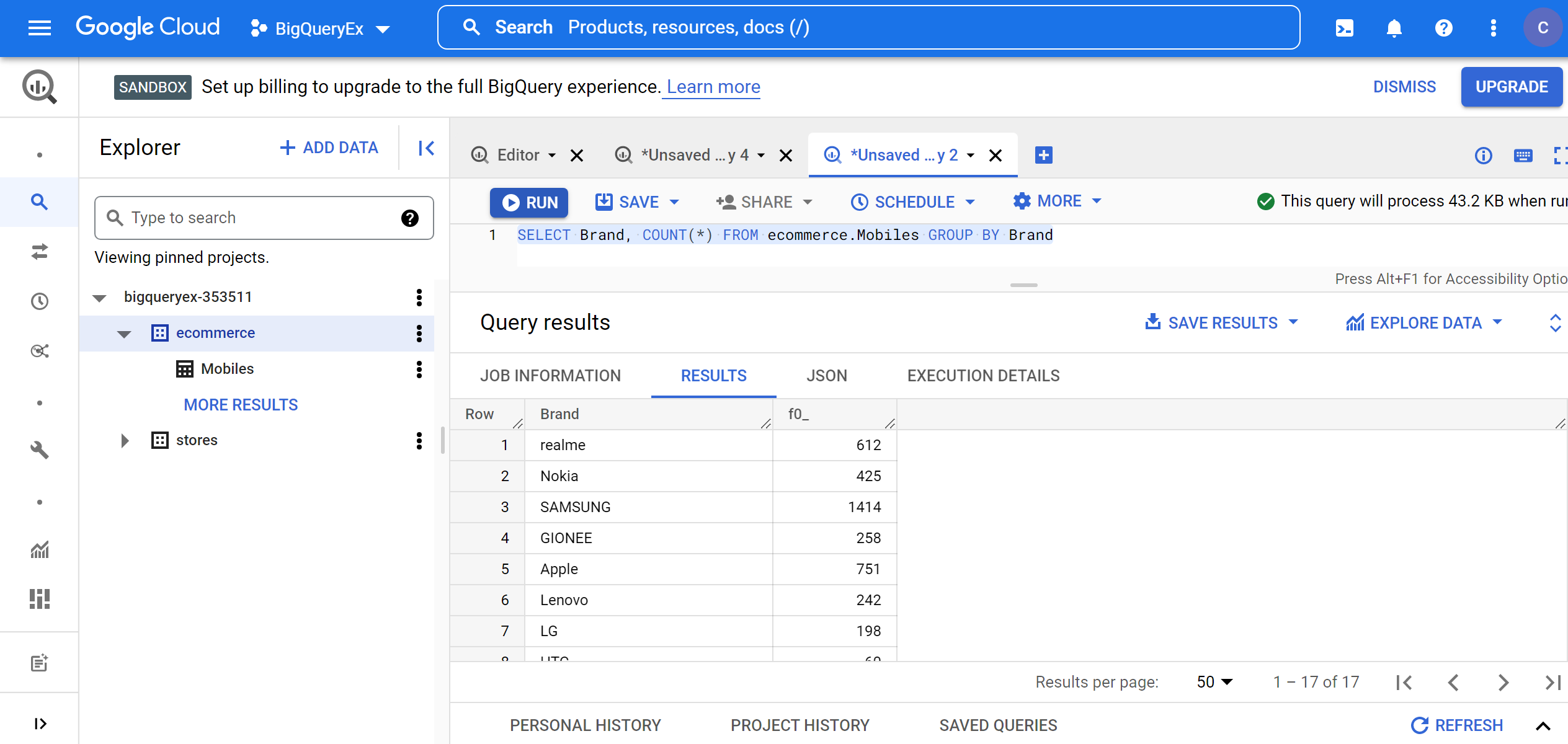
1. Filtering out mobile phones based on Brand:
SELECT Brand, COUNT(*) FROM ecommerce.Mobiles GROUP BY Brand
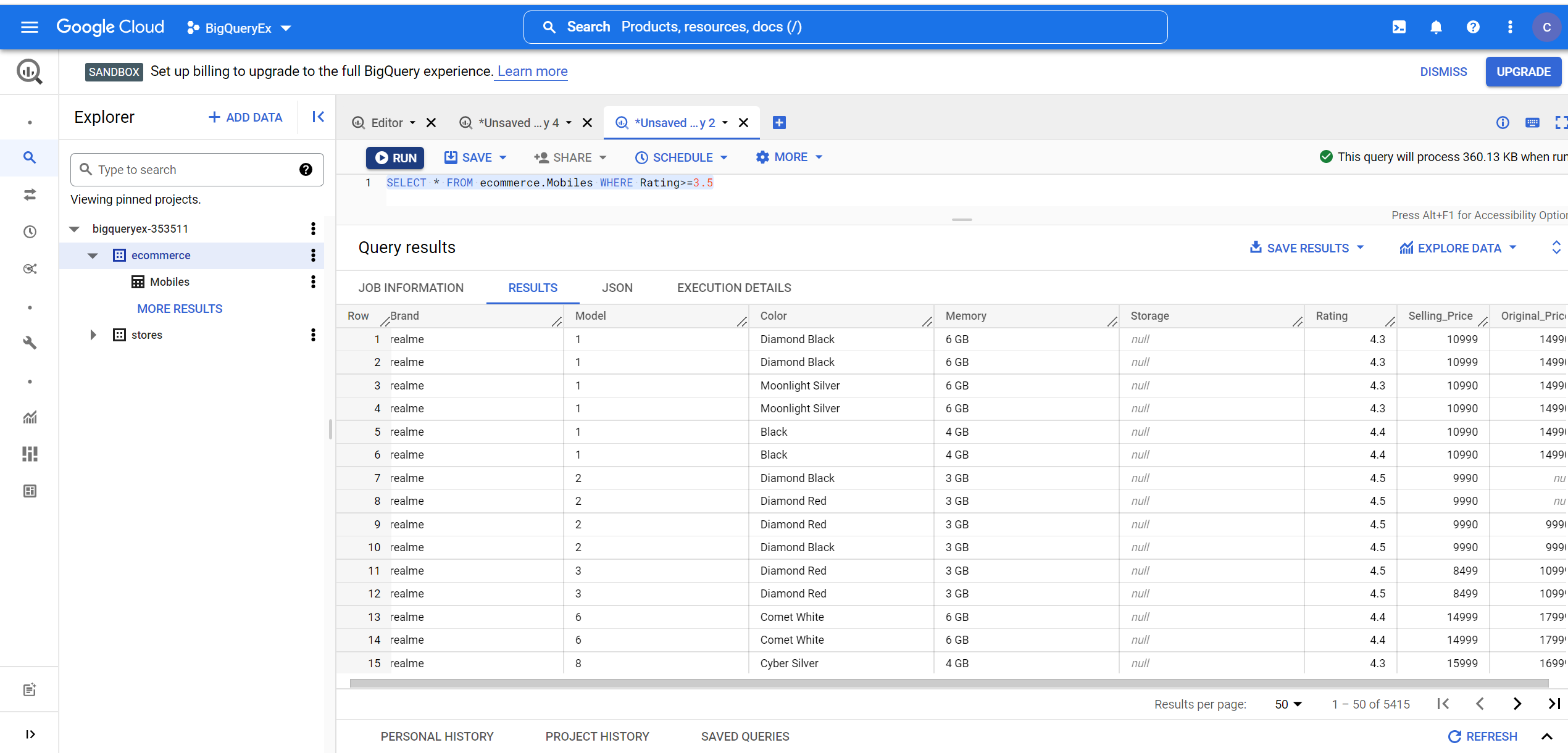
2. Finding the details of the mobile phones having a Rating greater than or equal to 3.5:
SELECT * FROM ecommerce.Mobiles WHERE Rating>=3.5
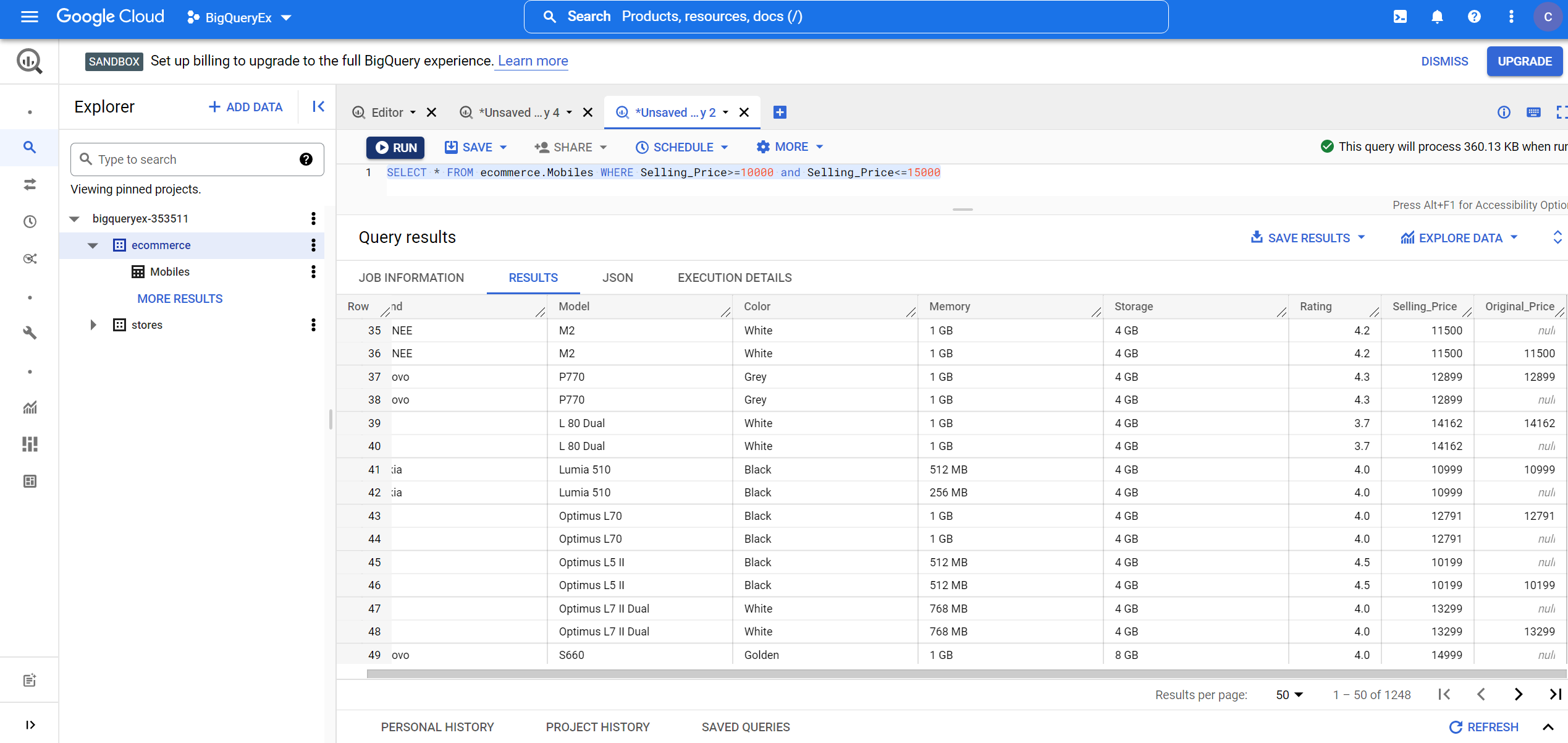
3. Finding the details of mobile phones having selling prices between 10,000 and 15,000:
SELECT * FROM ecommerce.Mobiles WHERE Selling_Price>=10000 and Selling_Price<=15000
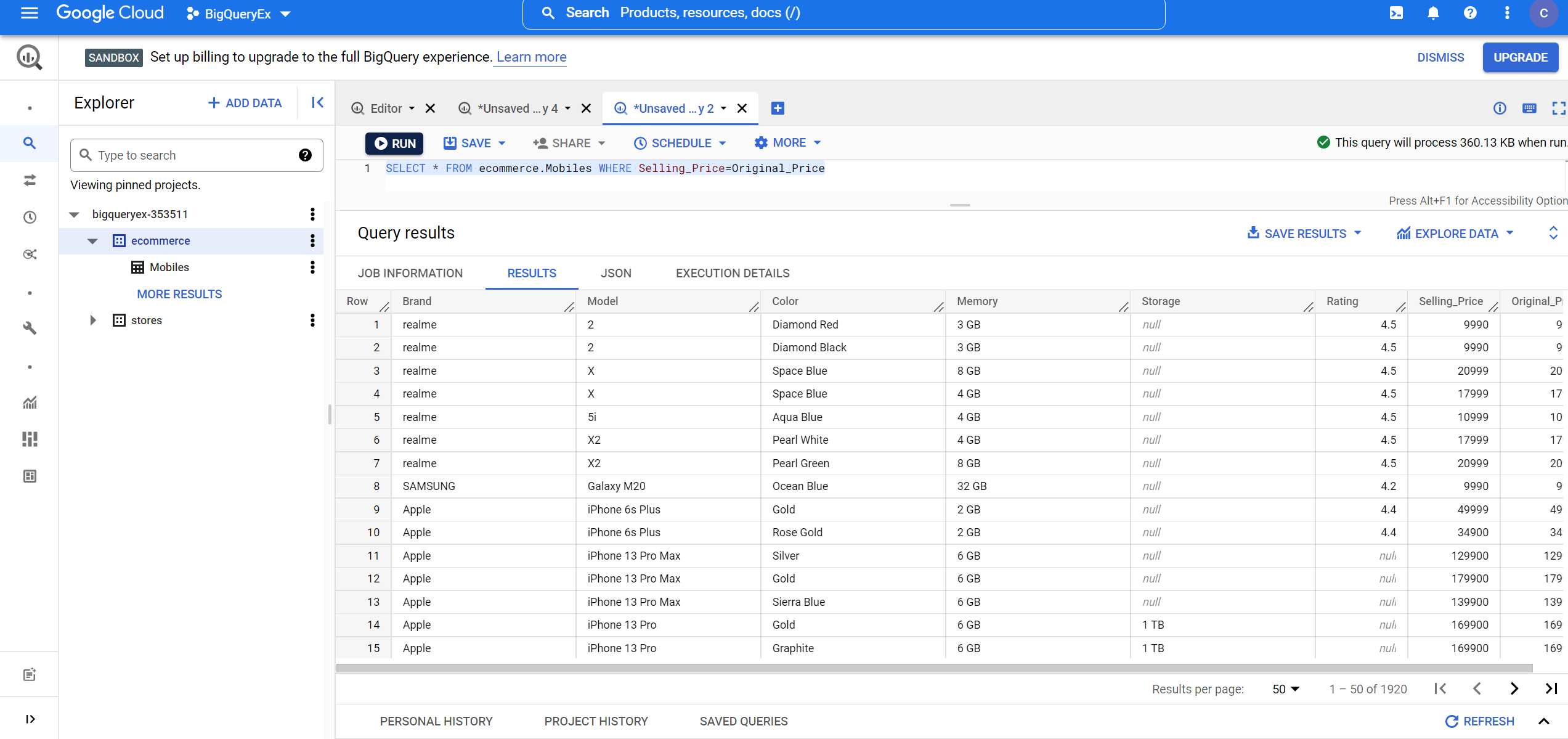
4. Finding the details of mobile phones which have selling price same as that of the original price:
SELECT * FROM ecommerce.Mobiles WHERE Selling_Price=Original_Price
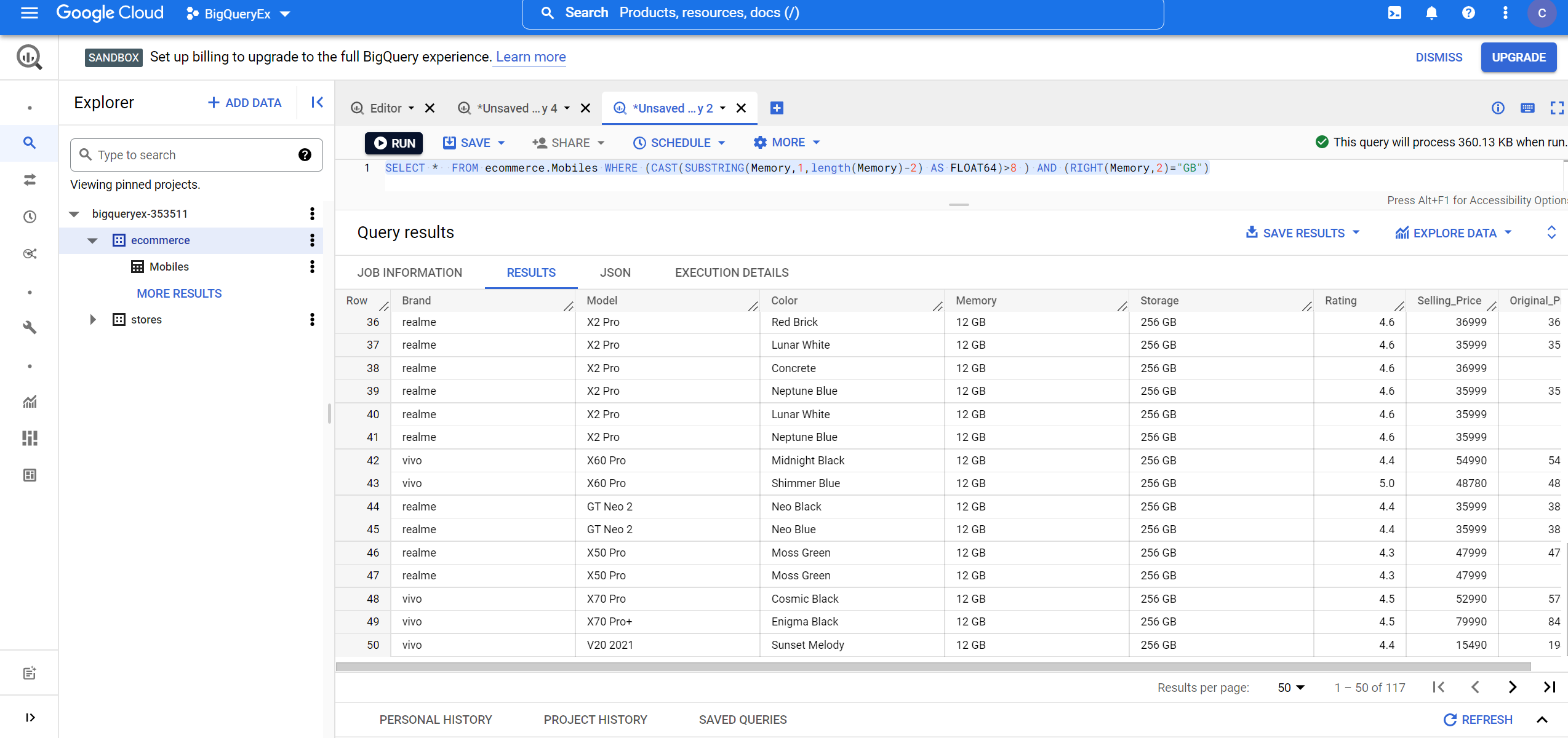
5. Finding the details of mobile phones which have Memory greater than 8 GB:
SELECT * FROM ecommerce.Mobiles WHERE (CAST(SUBSTRING(Memory,1,length(Memory)-2) AS FLOAT64)>8 ) AND (RIGHT(Memory,2)="GB")
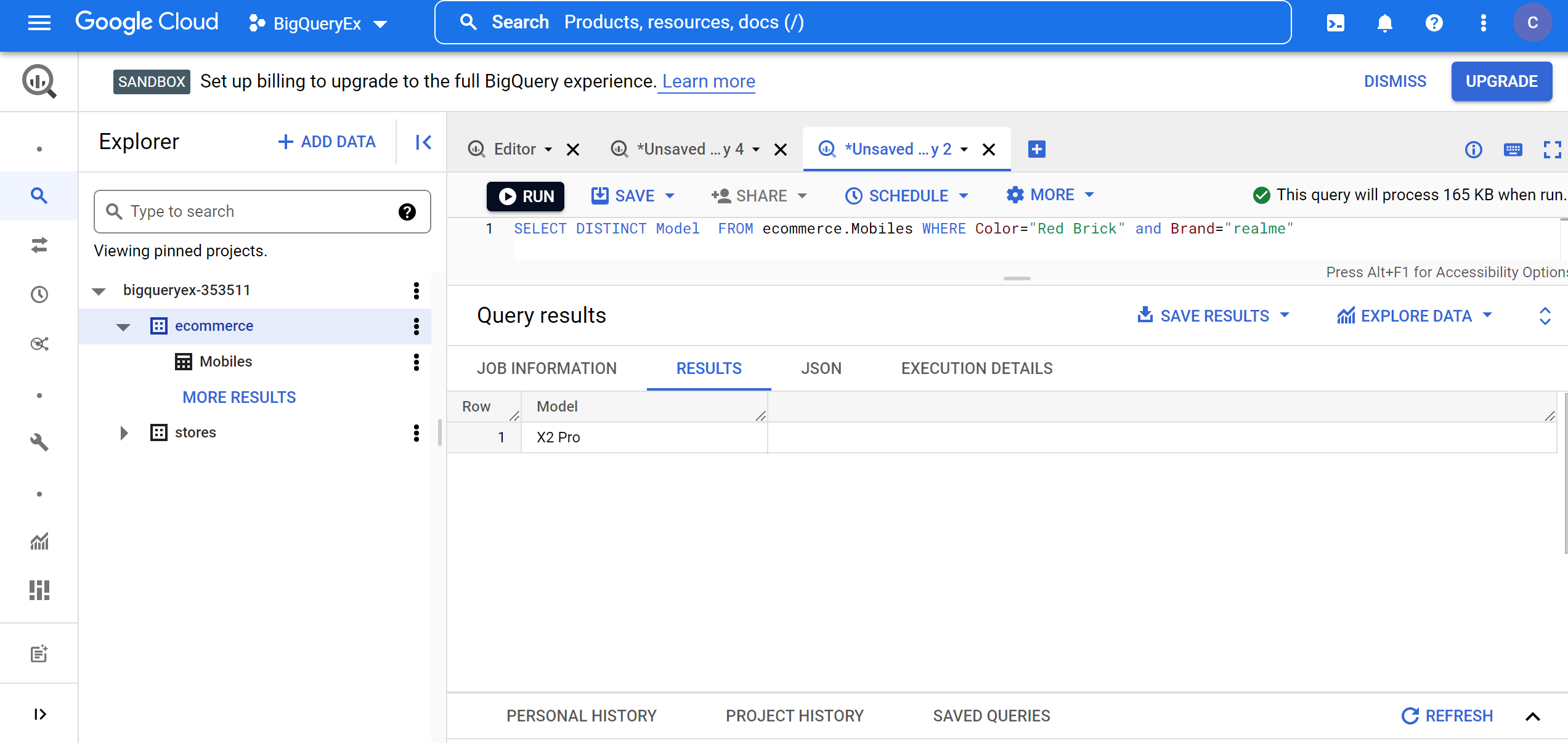
6. Finding the model details of realme mobile phones which has Red Brick color:
SELECT DISTINCT Model FROM ecommerce.Mobiles WHERE Color="Red Brick" and Brand="realme"
Conclusion
We have seen how to create a data warehouse for an e-commerce scenario using Google Big Query. We understood how data warehouses built using Big Query are cost-effective, secure, and easily scalable. We learned how we can build a data warehouse for a real-time scenario. Below are the major takeaways from the above guide :
- We got a good understanding of the data warehouse and the scenarios in which the data warehouse is needed.
- We have also seen how data types from different sources are collected and analyzed in the data warehouse.
- We understood how data is stored and maintained, ML algorithms are applied, and security is maintained in Big Query.
- We have also seen the functional, underlying architecture, use cases, and advantages of using Big Query.
- We learned how to create projects in GCP.
- We understand how to create datasets and tables and perform data aggregation in Big Query.
- We got a good understanding of how we can use UNION operations to aggregate data from multiple sources in Big Query.
- We have seen how we can query aggregated data to get discussed useful insights.
- Apart from this, we saw how we can create uploaded tables and analyze imported tables’ data format and schema in Big Query.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Full Stack developer with 2.6 years of experience in developing applications using
Azure, SQL Server & Power BI. I love to read and write blogs. I am always willing to learn new technologies, easily adaptable to changes, and have a good time
management, problem-solving, logical and communication skills






Good article for complete beginners! I was able to at least learn how to create a table and pass data from a csv file in Big Query. Thanks