
This article was published as a part of the Data Science Blogathon.
Introduction
Ever wondered how to query and analyze raw data? Also, have you ever tried doing this with Athena and QuickSight? This blog post will walk you through the necessary steps to achieve this using Amazon services and tools. Amazon’s perfect combination of storage, transformation, and visualization can help you achieve your data analysis and visualization goal.
.png)
The required AWS services and tools are as follows:
- Simple Storage Service (S3) is an online store where you can store and retrieve any type of data on the web, regardless of time and place.
- With the help of simple SQL, we can analyze and query raw data by using AWS Athena‘s interactive service.
- QuickSight is an AWS-based Business Intelligence and visualization tool used to visualize data, perform ad hoc analysis, and derive business insights from our data.
Let’s start by checking the flow of data from left to right. We will first upload our source file to S3, then connect Athena to S3 to query the data, and finally, use QuickSight to visualize the information.
Upload data to S3
- Create a new bucket.
- Create a new folder in this bucket because Athena needs the folders inside it to access the data.
- Upload the source file to the previously created folder.
Create a Table in Athena and Query the Data
There are three ways to access Athena: the AWS Management Console, the Amazon Athena API, or the AWS CLI. For this blog, we will be using the AWS Management Console. Before working with Athena, ensure the Athena region is the same as the S3 bucket region created earlier. Otherwise, you won’t be able to connect and query the data.
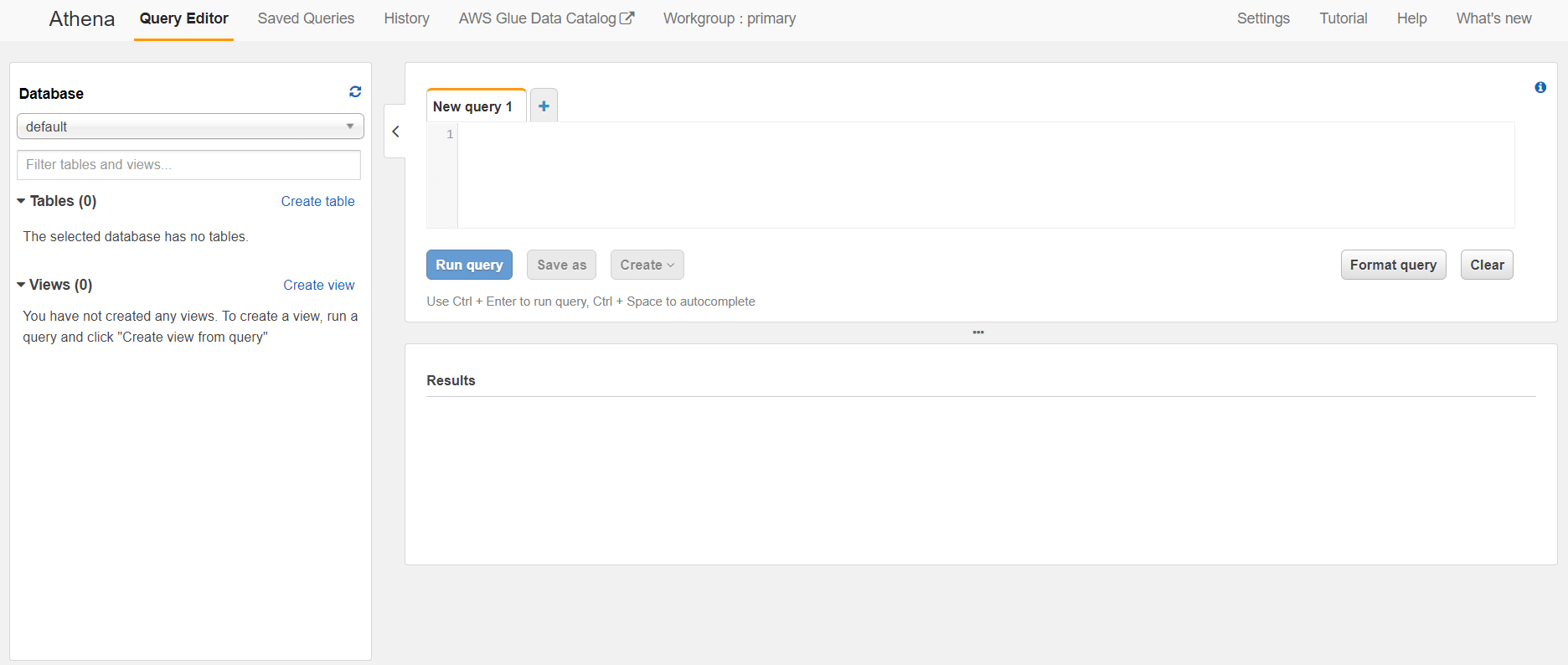
AWS Athena has a simple and easy-to-understand interface.
https://aws.amazon.com
In the left part, you can see the databases along with the tables and views that are part of the selected database. The right section is for writing SQL queries, and the result of the query we ran is displayed in the results section. In addition, Athena allows us to save or format our query.
The menu structure is easy to navigate and includes five primary tabs: Query Editor, Saved Queries, History, AWS Glue Data Catalog, and Workgroup: Primary.
So let’s start working with Athena. First, we need to create a table, and there are several options to do this. We will create a table from the S3 bucket. Once we select this option, we will be redirected to the four-step process of creating the table.
Step 1: Name and Location
This step defines the database, table name, and input data set location.
You can select a database from the drop-down list if you already have a database. If not, you can create a new database by selecting Create a new database, and then you need to define its name. Next, we need to enter the name of the table. This name should be unique worldwide. After naming the table, we need to define the source file’s location. This is where the S3 comes into play. We need to define the path to the folder, so we need to specify the bucket’s name and the folder’s name. Note that we cannot provide a file path; we can only provide a folder path.
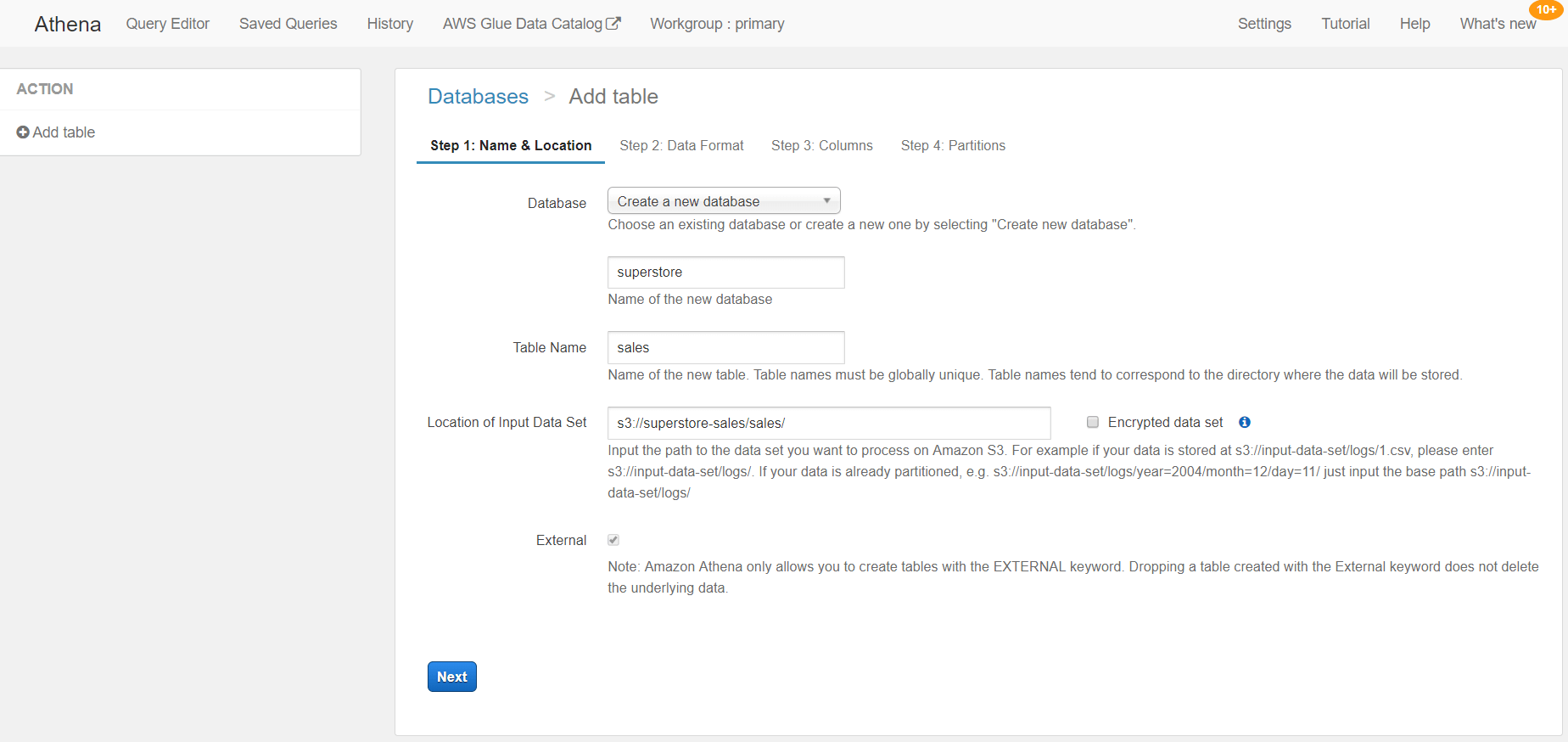
Step 2: Format the data
There are several data formats that we can access using Athena. In this example, we will use a CSV file to select CSV as the data format.
Step 3: Columns
The source file does not contain the column names, so we need to specify them in this step. This is something that is required for Athena to know the schema of the data we are working with. This can be achieved in two ways. One way is to simply enter the column name and column type for each column individually, and the other way is to add the columns in bulk as shown in the image below.

The second method is more suitable when our dataset has too many columns, and it is tedious to configure each one individually. The format is pretty simple. We need to enter the column name, followed by a space, and followed by the data type in that column. A comma separates column definitions.
Step 4: Partitions
In this step, we can configure partitions. Amazon suggests splitting the data to reduce the amount of data a query needs to scan. This can increase performance and reduce query costs. This is preferable if we have a large data set, but in our example, we have a small data set so it is not required.
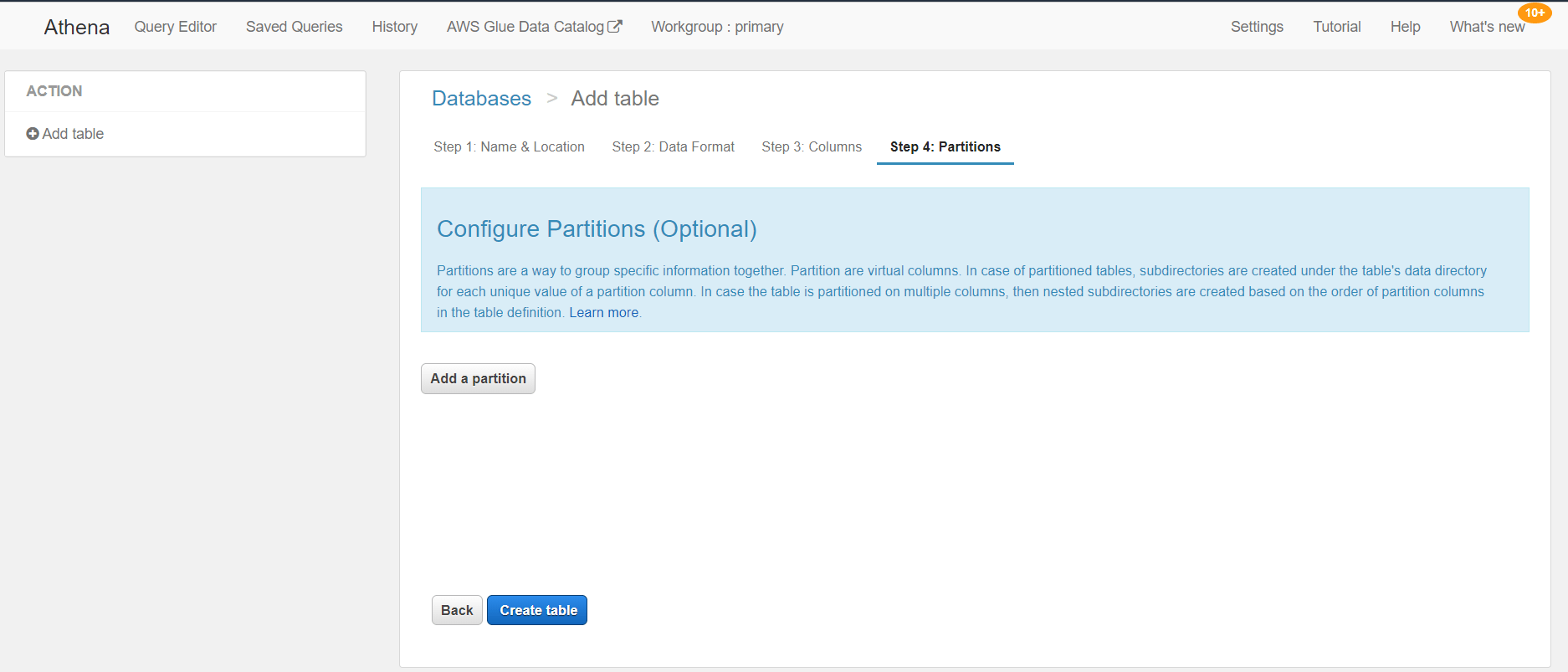
With this last step, we have completed the table creation process. We created it using the Create Table Wizard, but that’s not the only way to do it. Athena also allows us to create tables using DDL statements, as shown in the figure below.
CREATE EXTERNAL TABLE IF NOT EXISTS superstore.sales
orderpriority' string, discount decimal, "unitprice' decimal, shippingcost decimal, customerid'int, customername' string, shipmode string,
customersegment string, 10 productcategory' string,
productsubcategory' string, productcontainer string, productname' string, productbasemargin' decimal,
region' string, 16 state'string, 17 city' string,
postal code int, orderdate' date, shipdate' date,
profit' decimas, 22 quantityorderedednew' decimal,
sales' decimal, 24 orderid'int 25 ) 26 ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe' 27 WITH SERDE PROPERTIES 28 'serialization. format' =
'field.delim' = ',' 30 ) LOCATION 'S://superstore-sales/ sales/ 31 TBLPROPERTIES ('has_encrypted_data'='false');
Now all that remains is to query the table and see if the configuration is correct. To test this, let’s run this simple SQL query:
SELECT DISTINCT region, product Category, COUNT (productCategory) AS Quantity FROM sales WHERE region IN ('Central', 'East', 'West') GROUP BY region, product Category ORDER BY region
After running this query in the results section, we can see the output shown in the image below. Output files are saved automatically for each query run, regardless of whether the query itself has been saved or not.
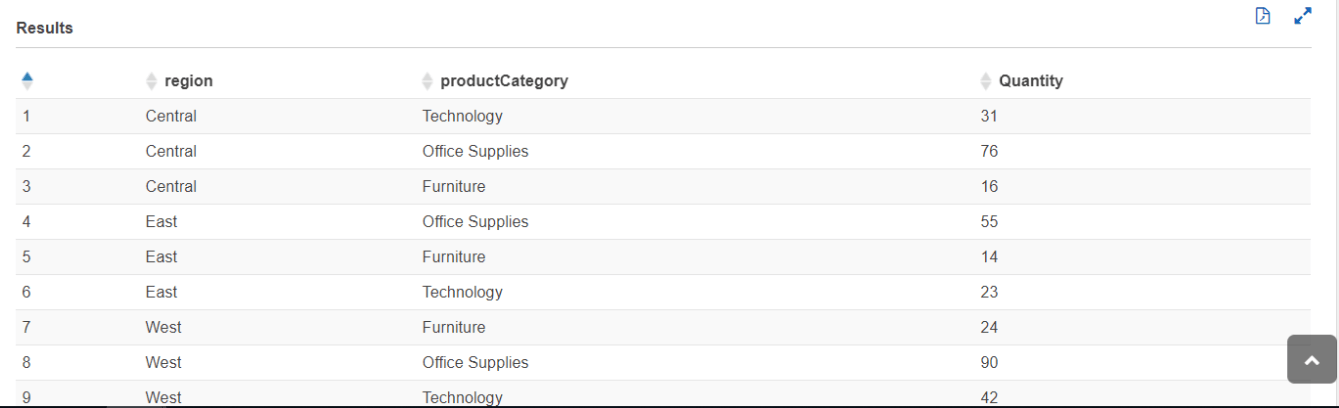
In addition, by selecting the file icon in the Results section, we can download a file with the query results in CSV format. We can also download it from the Query History tab.
Visualize Data with Amazon QuickSight
We use AWS Quicksight for data visualization purposes. But in addition to AWS Quicksight, you can also use Tableau, Looker, Mode Analytics, and more for advanced reports and visualizations. In our case, we will use QuickSight. It is an AWS-based Business Intelligence and visualization tool used to visualize data, perform ad hoc analysis, and derive business insights from our data. Data is entered as a dataset. AWS uses Superfast Parallel In-Memory Computing (SPICE) to perform data calculations and create graphs quickly. Amazon QuickSight retrieves data from Athena, S3, RDS, RedShift, MySQL, Snowflake, and many more.
You must create an account if you have never worked with QuickSight. Before connecting it to Athena, ensure that QuickSight has the right to access the information. You must enable QuickSight to access Amazon Athena and S3. If QuickSight does not have these rights, we will be unable to analyze and visualize the data we have queried in Athena. Another important thing is also the region. The region we selected for QuickSight must be the same as the region we selected for Athena. Otherwise, QuickSight will not be able to access the data we have in Athena.
Several visualizations or graphic formats are available. We can choose charts like bar charts, pie charts, ring charts, line charts, etc.
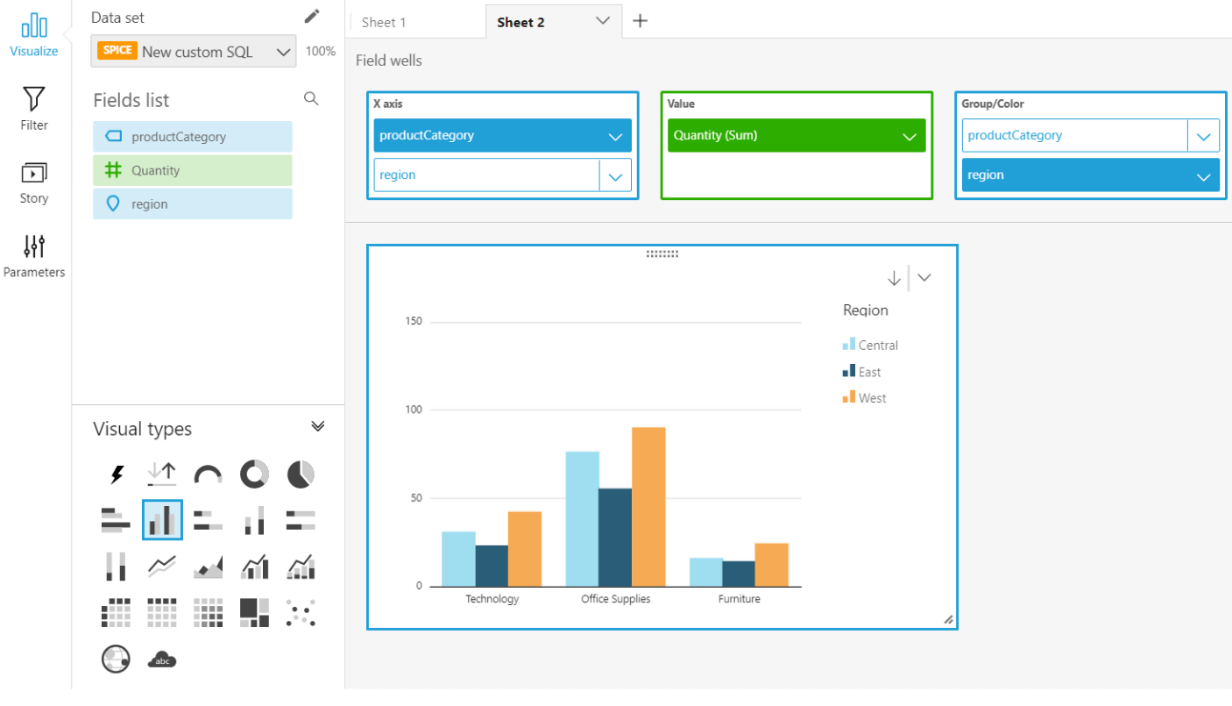
https://aws.amazon.com
In the image above, we used a vertical bar chart to visualize the data we previously queried in Athena effectively. The dashboard automatically updates as data is updated or scheduled.
Conclusion
AWS Athena is used to running queries quickly and easily without having to set up and manage any servers or data warehouses. This service is the right choice if you need to analyze large data sets. In this blog, we used S3 to store data, connected Athena to S3 to query the data, and finally, used QuickSight to visualize the information.
- AWS-based Business Intelligence and visualization tool used to visualize data, perform ad hoc analysis, and derive business insights from our data.
- There are three ways to access Athena: the AWS Management Console, the Amazon Athena API, or the AWS CLI.
- The menu structure is easy to navigate and includes five primary tabs: Query Editor, Saved Queries, History, AWS Glue Data Catalog, and Workgroup: Primary.
- Amazon suggests splitting the data to reduce the amount of data a query needs to scan. This can increase performance and reduce query costs. This is preferable if we have a large data set, but in our example, we have a small data set, so it is not required.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Data Analyst who love to drive insights by visualizing the data and extracting the knowledge from it. Automating various tasks using python & builds Real time Dashboard's using tech like React and node.js. Capable of Creaking complex SQL queries to fetch the accurate data.
Free Courses





