This article was published as a part of the Data Science Blogathon.
Introduction
With the growth of the data industry, there is an increasing need to store and process such a vast amount of data. At present, businesses can collect more data than ever before. These data contain valuable insights into business and customers if unlocked. Nowadays, data comes in different formats: video, audio, and text. Data lakes can store these formats at a low cost, and in addition, data lakes do not lock businesses into a particular vendor, unlike data warehouses. However, data lakes have limitations like difficulty maintaining reliable data, inaccurate query results, increased data volume causing poor performance, and difficulty in properly securing and governing. 73% of the company data might go unused if these limitations are not addressed. Delta lake is a solution to all these limitations. Let us see what exactly is a delta lake. Cloud object stores can hold and process exabytes of data belonging to tons of customers.

Source: https://towardsdatascience.com/delta-lake-enables-effective-caching-mechanism-and-query-optimization-in-addition-to-acid-96c216b95134
What is Delta Lake?
Delta lake is an open-source storage format and management layer that is based on files. It uses a transaction log that is compacted into Apache Parquet format. This enables ACID (Atomicity-Consistency-Isolation-Durability), time travel, and quick metadata operations (Armbrust et al., 2020). It runs over existing data lakes and is consistent with Apache Spark and other processing engines (Lee, Das, & Jaiswal, 2022).
Features Associated with Delta Lake
Lee, Das, & Jaiswal(2022) put forth the following features associated with delta lake
1. Guarantee of ACID – There is durability regarding all data changes written to storage. These changes are visible to readers atomically.
2. Scalable data and metadata handling – Delta lake is built on a data lake. This allows all reads and writes using Spark or other processing engines to be scalable to a petabyte scale. Delta lake uses Spark for metadata handling, which efficiently handles metadata of billions of files.
3. Audit history and time travel – The Delta Lake transaction log records details about all the changes in data giving a full audit of the changes that took place over the period. It also gives developers access and reverts to earlier versions of data.
4. Schema enforcement and schema evolution – Delta lake does not allow the insertion of data with a wrong schema; additionally, it allows explicit evolution of table schema to accommodate dynamic data.
5. Support for deletes, updates, and merge – Deletes, updates, and merge operations are supported by delta lake to enable complex application cases.
6. Streaming and batch unification – A delta lake table can work both in batch and as a streaming source.
Delta Lake Terminologies
Some key terms must be discussed before delving deep into delta lake’s an architecture/working pattern.
Pipeline
A pipeline is a line of pipes and other accessories like pumps, valves, etc., to carry liquids or gases from source to destination. Similarly, concerning Delta Lake, a pipeline efficiently query the processed data and gets insights from it.
Parquet
Parquet or Apache parquet is an open-source, column-oriented data file format. It is the most common way to store relational datasets in cloud object
stores where each table is stored as a set of objects.
stores where each table is stored as a set of objects.
ETL
ETL stands for Extract-Transform-Load. Here, process data engineers extract data from different sources, transform them into a usable form, and load the data into the system for end-users. The image below depicts the process of ETL.
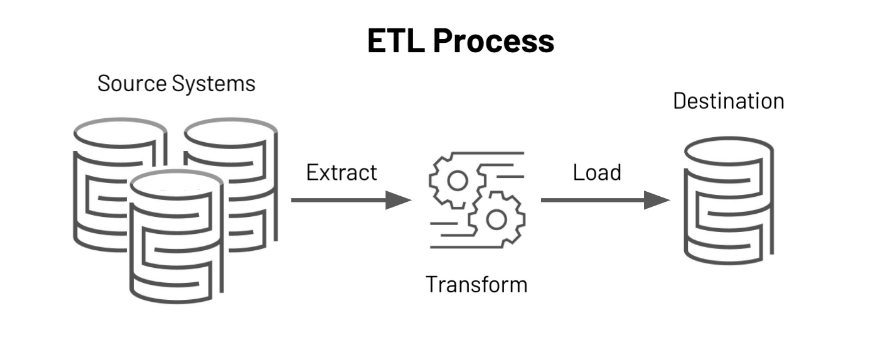
Source: https://www.databricks.com/glossary/extract-transform-load
Working Mechanism of Delta Lake
The following images depict how delta lake is advantageous compared to traditional platforms.
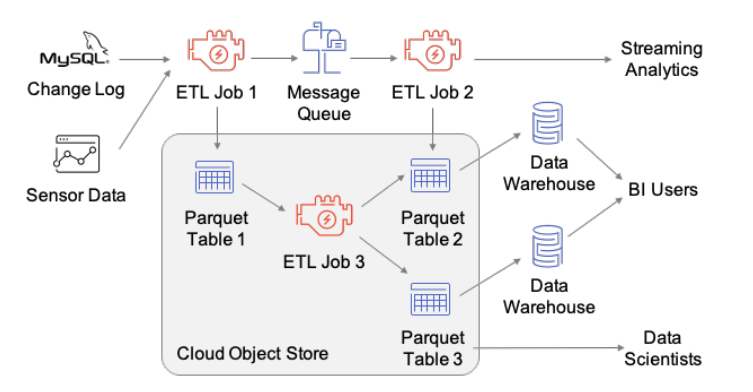
(1) Pipeline using a separate storage system.
Source: Armbrust et al., 2020
Figure (1) exhibits an example of a data pipeline involving individual business intelligence teams with separate object storage, a message queue, and two data warehouses.
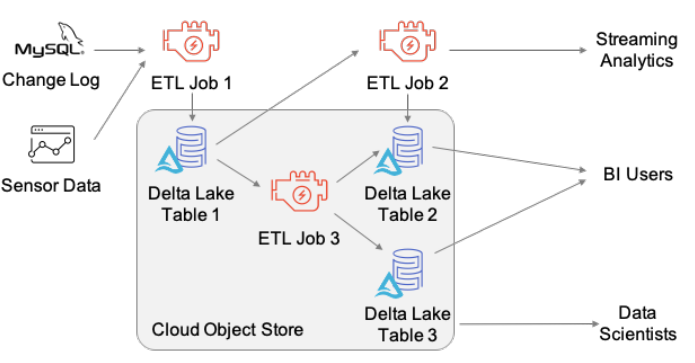
(2) Delta Lake.
Source: Armbrust et al., 2020
Figure (2) depicts delta tables replacing separate storage systems through Delta’s
streaming I/O and performance features to run ETL and BI. Low-cost object storage creates fewer data copies, reducing storage costs and maintenance overheads.
Steps to Use Delta Lake
Integrating Delta Lake within the Apache Spark ecosystem is the simplest way to start with delta lake. There are three mechanisms: leveraging local spark shells to use delta lake, using Github or Maven, and utilizing Databricks community edition (Lee, Das, & Jaiswal, 2022). We shall be looking into each of these mechanisms below
Leveraging local spark shells to use delta lake
In Apache Spark shells, the Delta Lake package is available with the –packages option. This option is suitable when working with a
the local version of Spark.
# Using Spark Packages with PySpark shell
./bin/pyspark –packages io.delta:delta-core_2.12:1.0
# Using Spark Packages with spark-shell
./bin/spark-shell –packages io.delta:delta-core_2.12:1.0
# Using Spark Packages with spark-submit
./bin/spark-submit –packages io.delta:delta-core_2.12:1.0
# Using Spark Packages with spark-shell
./bin/spark-sql –packages io.delta:delta-core_2.12:1.0
Using Github or Maven
Github is an online hosting service for developing software. It offers each project the benefits of access control, bug tracking, software feature requests, task management, and continuous integration. Maven is a build automation tool and is widely utilized for Java projects. Building and managing projects in C#, Ruby, Scala, and other languages are also possible with Maven. The Apache Software Foundation is the project’s host.
Utilizing Databricks community edition
Databricks is a web-based open platform that acts as a collaborative environment to perform interactive and scheduled data analysis. To create an account, one needs to visit https://databricks.com/try and adhere to the instructions to use
the Community Edition for free. The Community Edition comprises many tutorials and examples. One can write own note‐
books in Python, R, Scala, or SQL; one can also import other notebooks. The following image represents the page of databricks.
Source: Lee, Das, & Jaiswal, 2022
Basic Operations
We shall discuss the basic operations for constructing Delta tables. Delta includes complete APIs for three languages often used in the big data ecosystem: Python, Scala, and SQL. It can store data in HDFS and cloud object stores, including S3 and ADLS gen2. It is designed in a way that it can be written primarily by Spark applications and can be read by many open-source data engines like Spark SQL, Hive, Presto (or Trino), and many enterprise products like AWS Athena, Azure Synapse, and BigQuery (Lee, Das, & Jaiswal, 2022). In the basic operations, we shall focus on writing and reading the delta table with the help of python. There exists a difference between parquet and delta tables. The difference is the _delta_log folder which is the Delta transaction log. Being the underlying infrastructure for features like ACID transactions, scalable metadata handling, and time travel, the Delta transaction log is critical in understanding Delta Lake (Lee, Das, & Jaiswal, 2022).
Writing Delta Table
When a Delta table is created, files like the file system or cloud object stores are written to some storage. A table is made after storing all the files together in a directory of a particular structure. Creating a Delta table means writing files to some storage location. For example, the following Spark code snippet through Spark DataFrame API takes an existing Spark DataFrame and writes it in the Apache Parquet
storage format in the folder location /data
dataframe.write.format("parquet").save("/data")
A simple change in the above code snippet by using Apache Spark can create a
Delta table. Initially, Spark DataFrame
data will be created, and then the write method will be used to save the table to storage.
# Create data DataFrame
data = spark.range(0, 5)
# Write the data DataFrame to /delta location
data.write.format("delta").save("/delta")
The data partition is important when there is a humongous amount of data. The following code snippets do exactly this
# Write the Spark DataFrame to Delta table partitioned by date
data.write.partitionBy("date").format("delta").save("/delta")
If there is an existing Delta Table and a need to append or overwrite data to the table, the mode method is used as shown in the code snippets.
# Append new data to your Delta table
data.write.format("delta").mode("append").save("/delta")
# Overwrite your Delta table
data.write.format("delta").mode("overwrite").save("/delta")
Reading Delta Table
To read the files from the delta table, Dataframe API will be applied. The code snippets are as follows
# Read the data DataFrame from the /delta location
spark.read.format("delta").load("/delta").show()
In the above, we read delta tables directly from the file system. But how to read a metastore-defined Delta table? To do this, the table within the metastore needs to be defined using the saveAsTable method in python.
# Write the data DataFrame to the metastore defined as myTable
data.write.format("delta").saveAsTable("myTable")
It is noteworthy that saveAsTable method saves the Delta table files into a
location managed by the metastore. So, in the basic tenets, we have covered two important operational aspects: writing and reading delta table.
Conclusion
Delta Lake is an open-source storage format and management layer. It enables Data Lake to overcome challenges like difficulty maintaining reliable data, inaccurate query results, increased data volume causing poor performance, and difficulty in properly securing and governing. Delta lake brings to the fore many advantages in terms of storing and managing data
- Delta Lake is implemented as a storage format and has a set of access protocols, making operation simple and highly available.
- Clients can access the object store directly because of the access protocols.
- Data processing is humongous, with exabytes of data being processed per day.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
I am a biotechnology graduate with experience in Administration, Research and Development, Information Technology & management, and Academics of more than 12 years. I have experience of working in organizations like Ranbaxy, Abbott India Limited, Drivz India, LIC, Chegg, Expertsmind, and Coronawhy.
Recognition:
1. Played major role in making a brand “Duphaston” worth “Rs 100 crores INR” in Abbott India Limited as Therapy Business Manager of Women’s health and gastro intestine team.
2. Won “best marketing skills” award in Abbott India Limited.
3. Came on the merit list of National IT aptitude test, 2010.
4. Represented my school in regional social science exhibition.
Courses and Trainings:
1. Took 54 hours training on vb.net in Niit, Guwahati.
2. Underwent training of 7 days on targeting and segmentation in Abbott India ltd, Lonavala.
3. Earned “Elite Certificate” from IIT-Madras on “Python for Data Science”.





