This article was published as a part of the Data Science Blogathon.
Introduction
Apache Iceberg is an open-source spreadsheet format for storing large data sets. It is an optimization technique where attributes are used to divide a table into different sections. Learn more about partitioning in Apache Iceberg and follow along to see how easy partitioning becomes with Iceberg.
.jpg)
What is Apache Iceberg?
Apache Iceberg is a relatively new open-source spreadsheet format for storing petabyte-sized datasets. Iceberg easily fits into the existing big data ecosystem and integrates with Spark and Presto execution engines. Using a large amount of metadata stored in each spreadsheet, Iceberg provides functionality not traditionally available in other spreadsheet formats. This includes schema development, partition development, and table version rollback—without needing costly table rewrites or table migrations.
What is a Split?
Partitioning in databases is no different – large tables are divided into several smaller tables by grouping similar rows. The benefit is faster reading and loading for queries that only access part of the data. For example, a log table that tracks log events, messages, and event time may contain millions of records across months. Splitting these entries by day makes querying approximately 100 log events that occurred from December 11-19, 2019, much faster.
Iceberg tries to improve on conventional partitioning like that in Apache Hive. In Hive, partitions are explicit and appear as a separate column in the table that must be specified each time the table is written to. Queries in the sub-registry must also explicitly provide a filter for the partition column because the subregistry does not track the relationship between the partition column and its source column. Subregister tables also do not support in-place partitioning; to change a partition, the entire table must be completely overwritten with the new partition column. This is expensive for large tables and can cause data accuracy issues. In addition, queries dependent on table partitions must now be rewritten for the new table. On the flip side, Iceberg implements partitioning in a way that does not lead to these problems.
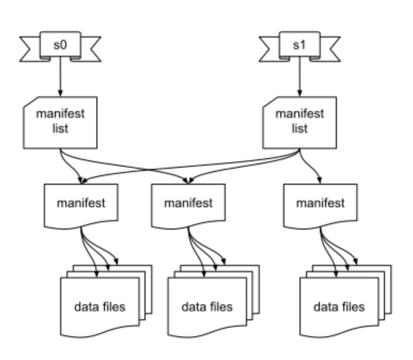
A Split in the Apache Iceberg
Iceberg makes partitioning easy for users by implementing hidden partitioning. Rather than forcing the user to supply a separate partition filter at query time, Iceberg handles all partitioning and querying details under the hood. Users don’t need to maintain partition columns or even understand the physical layout of the table to get accurate query results.
Source: Medium
Iceberg has several split options; users can split timestamps by year, month, day, and hour. Iceberg tracks the relationship between a column value and its partition without requiring additional columns. Queries for timestamp data in the format “YYYY-MM-DD hh:mm:ss” split by day, for example, do not need to include the “hh:mm:ss” part in the query statement. Iceberg can also split categorical column values by identity, hash buckets, or truncation.
Another benefit of hidden partitioning is that users do not need to enter partition layout information when querying Iceberg tables. Not only does this make Iceberg partitioning extremely user-friendly, but it also allows you to change partition layouts over time without disrupting pre-written queries. When developing a partition specification, the data in the table before the change is not affected, as well as its metadata.
Only the data written to the table after evolution is partitioned according to the new specification, and the metadata for this new data set is kept separately. When queried, the relevant metadata of each partition layout is used to identify the files it needs to access, called split planning. Split-planning is one of Iceberg’s many features made possible by table metadata, which creates a separation between physical and logical. This concept is what makes icebergs so versatile.
Partition Development in Apache Iceberg
In this section, we’ll walk through an example of partitioning and see how seamless it is to query data with multiple partition layouts. But first, explaining how the Iceberg tables are structured on disk can help clarify the big picture. Each Iceberg table folder has a metadata folder and a data folder. The metadata folder contains information about partition specifications, their unique IDs, and manifests associating individual data files with their respective partition specification IDs. The data folder contains all the table data files that make up the complete Iceberg table. Iceberg creates multiple folders within the data folder when writing data to a partitioned table.
Each is named with a partition description and value. For example, a column named time and partitioned by month will have folders time_month=2008-11, time_month=2008-12, and so on. Data partitioned across multiple columns creates multiple layers of folders, with each top-level folder containing one folder for each second-level partition value.
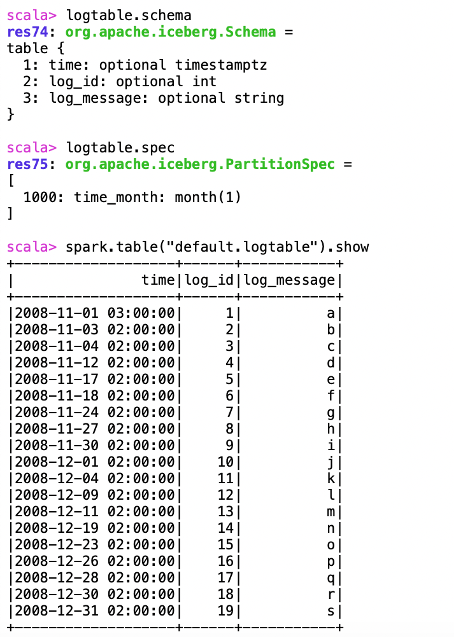
Now, our example uses Iceberg’s HiveCatalog API to create and load Iceberg tables from the Hive metastore. For brevity, we use a trivial dataset mimics a log table for some software product developed by X, with columns for time, log_id, and log_message. If you are following this example on your computer, copy the following data and save it to a CSV file. Note that the timestamps in the data appear as long datatypes corresponding to their UNIX timestamp in seconds:
1225526400,1,a 1225699200,2,b 1225785600,3,c 1226476800,4,d 1226908800,5,e 1226995200,6,f 1227513600.7 g 1227772800.8 h 1228032000,9,i 1228118400,10,j 1228377600.11 k 1228809600,12,l 1228982400.13 m 1229673600,14,n 1230019200.15, o 1230278400.16, p 1230451200,17,q 1230624000, 18, r 1230710400,19,p 1230796800,20,t 1230969600,21,u 1231747200,22,v 1232352000,23,w 1232784000.24.x 1233216000.25,y 1233302400.26, z Show more
Company X has acquired several customers and now expects log events to occur more frequently. They find that starting in 2009; it would be more beneficial to split log events by day. We will walk through this scenario and manually add the necessary data.
First, run spark-shell with the following command. In this example, we use Spark 3.0.0, Hive meta store 2.3.0, and Iceberg package release 0.9.0. We recommend using the same. If you are using Spark 2.4.x, the table display mechanism is different, but instructions are provided as needed.
> $SPARK_HOME/bin/spark-shell --packages org.apache.iceberg:iceberg-spark3-runtime:0.9.0 --conf spark.SQL.catalog.my_catalog=org.apache.iceberg.spark.SparkCatalog --conf spark.SQL.catalog.my_catalog.type=store Show more
After starting the Spark shell, import the required Iceberg packages for this example:
import org.apache.iceberg.{PartitionSpec, Schema, Table}
import org.apache.iceberg.catalog.TableIdentifier
import org.apache.iceberg.hive.HiveCatalog
import org.apache.iceberg.types.Types
Show more
Now we will create our table (log table) in the namespace called default, originally divided according to the month of the event. We create a Hive Catalog object and a Table Identifier object to do this. We also need to define the table schema and initial partition specification to provide this information to the create Table function:
Val namespace = "default"
Val table_name = "log table"
val catalog = new HiveCatalog(spark.sparkContext.hadoopConfiguration)
Val name = TableIdentifier.of(namespace, tableName)
Val table schema = new Schema(
Types.NestedField.optional(1, "time", Types.TimestampType.with one()),
Types.NestedField.optional(2, "id", Types.IntegerType.get()),
Types.NestedField.optional(3, "data", Types.StringType.get())
)
Val spec = PartitionSpec.builder(table schema).month("time").build()
Val log table = Catalog.createTable(name, table schema, spec)
Show more
Then add the data to the table. If you are using the dataset provided here, set the file_location variable to the same path as the CSV dataset on your computer. In the following commands, we’re only adding data for timestamps before January 1, 2009, mimicking the scenario in our Company X example. If you’re using your dataset to follow this example loosely, make sure to sort the data on the partition column when writing to the table (as shown here):
val file_location = "/path/to/data.csv"
val schema = StructType(Array(
StructField("time", IntegerType, true),
StructField("id", IntegerType, true),
StructField("data", StringType, true)
))
Val data = spark.read.format("CSV")
.option("separator", ",")
.schema(schema)
.load(file_location)
data.select(
data.col("time").cast(DataTypes.TimestampType),
data.col("id"),
data.col("data")
).where(data.col("time").lt(1230768000))
.sort(data.col("time"))
.write
.format("glacier")
.mode("overwrite")
.save(s"$namespace.$tableName")
Show more
You can see the current version of the table and its schematic and specifications. Use spark. read.format(“iceberg”).load(“default.log table”) instead of displaying the table with spark.table(“default.log table”).show. show.
Next, we define a new Partition Spec object, specifying the schema to build on (defined earlier) and the desired partition and source column:
Source: Apache
Val new spec = PartitionSpec.builder(log table.schema()).day("time").build()
Show more
We then update the partition specification for the table by defining a Table Operations object. From this object, we can define a basic and new metadata version with the evolved partition specifications. To make the requested changes official, the Table Operations object must be committed:
Val metadata = catalog.new tabletops(name) Val base metadata = metadata.current() Val new metadata = base metadata.updatePartitionSpec(new spec) metadata.commit(base metadata, new meta) table.refresh() Show more
In our scenario, Company X, a few days have passed since they developed their table partition specification, and new protocols have been added. We mimic this by manually adding new logs to the table using the following code. In this write operation, we only add dates that occurred on or after January 1, 2009:
data.select(
data.col("time").cast(DataTypes.TimestampType),
data.col("id"),
data.col("data")
).where(data.col("time").gt(1230768000))
.sort(data.col("time"))
.write
.format("glacier")
.mode("overwrite")
.save(s"$namespace.$tableName")
Show more
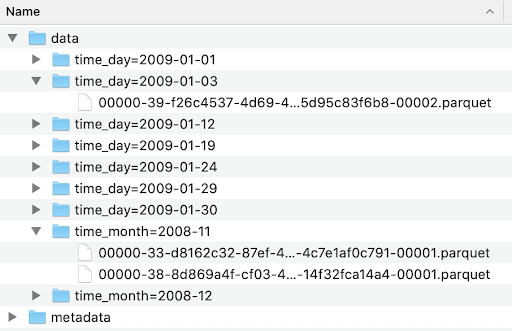
As you can see, after developing a partition in Iceberg, there is no need to rewrite the entire table. If you go to the data folder of your log table, you’ll see that Iceberg has organized the data files by their partition values - timestamps before January 1, 2009, are organized by month; timestamps on and after this date are sorted by day.
Source: Apache
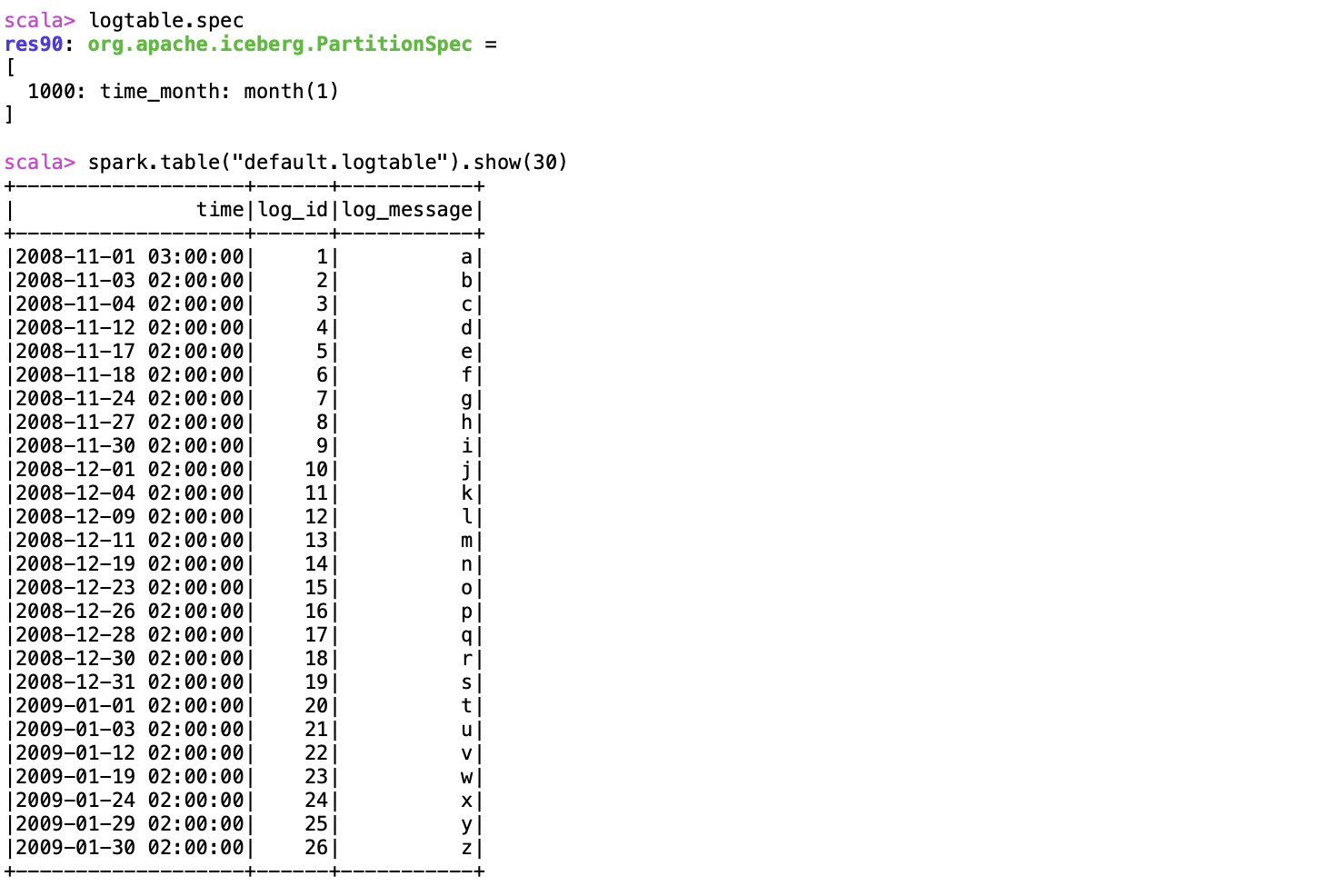
The new table specifications and data are listed below. Again, if you’re working in Spark 2.4.x, use spark. read.format(“iceberg”).load(“default.log table”).show to display the table.
Source: Apache
Company X wants to query all log events while their employees are on vacation to ensure they don’t miss any critical errors. The query shown below goes through several partition layouts but still works smoothly without requiring the user to enter additional information or know anything about table partitions:
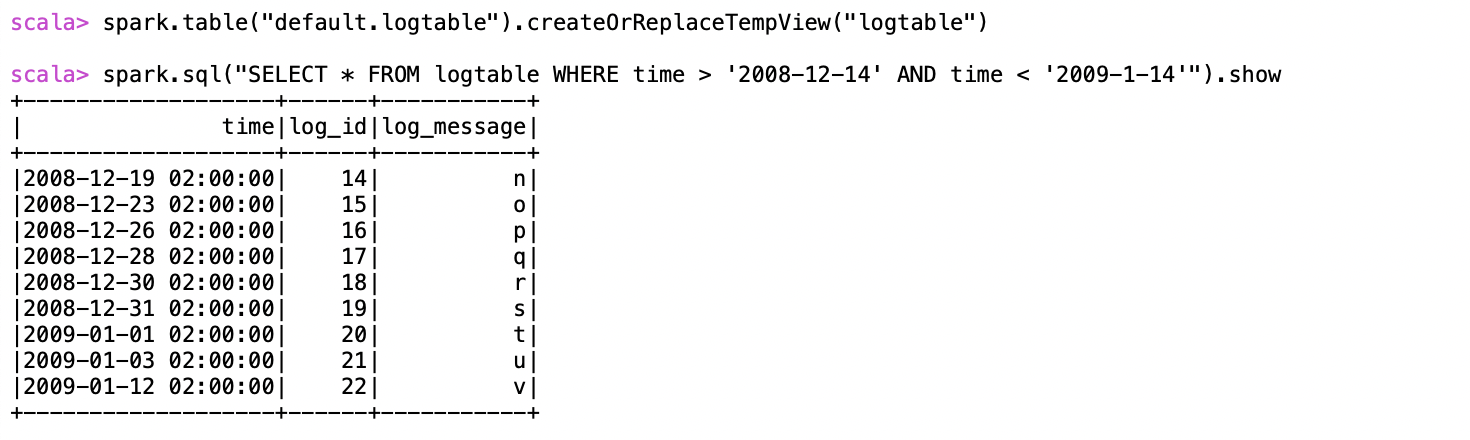
Source: Apache
Next steps for Splitting Apache Iceberg
Overall, Iceberg provides a large number of features for partitioning. Most partition tests are performed exactly as described in the Iceberg documentation. However, we ran into one problem while testing the development of the partition. Attempting to view or access the metadata table of the manifest file after the partition has been developed throws an Index Out Of Bounds Exception. Fortunately, other table operations work as intended despite this error, and additional changes to the manifest file table are properly logged. They do not cause additional errors other than the inability to display.
It should also be noted that Iceberg currently only supports the development of partitions through the Hive Catalog interface, and users of the Hadoop Table interface do not have access to the same functionality. The community is working on adding all partition development functionality directly to the table API so that they can be easily accessed from the Iceberg table object (the log table variable in our example). This ensures consistency of partition development operations for all users because the table object is used in Hadoop Tables and Hive Catalog implementations.
Conclusion
In short, abstracting the physical from the logical using Apache Iceberg’s extensive metadata enables hidden partitioning—and several other valuable features—in data lake implementations. I hope this article has helped you understand partitioning and partitioning in Apache Iceberg. Be sure to follow the Iceberg community for frequent updates.
- Iceberg tries to improve on conventional partitioning like that in Apache Hive. In Hive, partitions are explicit and appear as a separate column in the table that must be specified each time the table is written to.
- Iceberg provides a large number of features for partitioning and partitioning. Most partition tests are performed exactly as described in the Iceberg documentation. However, we ran into one problem while testing the development of the partition.
- Iceberg makes partitioning easy for users by implementing hidden partitioning. Rather than forcing the user to supply a separate partition filter at query time, Iceberg handles all partitioning and querying details under the hood. Users don’t need to maintain partition columns or even understand the physical layout of the table to get accurate query results.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.





