Introduction
The purpose of a data warehouse concepts is to combine multiple sources to generate different insights that help companies make better decisions and forecasting. It consists of historical and commutative data from single or multiple sources. Most data scientists, big data analysts, and business analysts use a data warehouse to get their data. This data warehouse can store data from multiple sources, including internal devices. Data is checked and cleaned before each upload. Now let us jump into the world of the data warehouse.
This article was published as a part of the Data Science Blogathon.
Table of contents
- What is Data Warehousing?
- Characteristics of the Data Warehouse
- The Architecture of the Data Warehouse
- Data Warehouse Components
- Data Marts
- Life Cycle of a Data Warehousing
- What is a Cloud Data Warehouse?
- OLAP and OLTP in Data Warehouses
- Schemas in Data Warehouses
- Latest Tools and Technologies in Data Warehousing
What is Data Warehousing?
Data Warehouses are a place to store our data. To make better decisions, the data used in the past and the data that will be useful in the future are stored in a data warehouse concepts. A Data Warehouse would consist of all raw data used or related to the organization/company. It was constructed by integrating multiple heterogeneous sources of data. Every company’s most valuable asset is information. This information is used for operational record keeping and analytical decision-making.
Operational Databases might change over time. If a company/organization wants to analyze previous actions or profits on data, it may not find data as previous data would have been updated. In this scenario, Warehouse comes into the picture. A warehouse would consist of all the data related to an organization from which we can get our data. It helps in the integration of a diversity of application systems.
A data warehouse concepts is a data management system that facilitates and supports business intelligence (BI) activities and analysis. These are primarily designed to contain large amounts of historical data and to analyze the searches. Unlike operational databases, warehouses are not updated frequently.
Importance of Data Warehouse
- They extract data from several sources and process it through ETL (Extract, Transform and Load) to load data into the warehouse.
- Data Warehouses improves the speed and efficiency of accessing different datasets and helps decision-makers to derive insights that will guide them to be apart from their competitors.
- Data Warehouse is highly scalable and efficient, enhancing data conformity and quality.
- Data Warehouse is a single source for all the data in the organization/company.
- A data warehouse platform allows business leaders to access their organization’s past activities and assess past initiatives’ successes or failures. This helps executives to see where they can reduce costs, maximize efficiency, and increase sales to boost profit.
The Goals of Data Warehouse / BI systems would be:
- Data Warehouse / BI systems must make systems easily accessible.
- Data Warehouse / BI systems must present information consistently.
- These systems must adapt to change.
- Warehouse / BI systems must present information promptly.
- Systems must be secure bastion that protects the information assets.
- They should work as authoritative and trustworthy for improved decision-making.
For better understanding, we can divide any warehouse into 4 stages of the process.
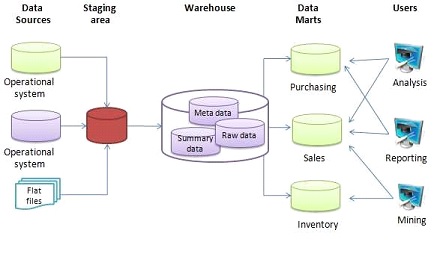
- Collect – At the collect stage, we fetch the raw data from the source systems and store the data in a layer named the staging layer. This process is called ETL (Extract, Transform and Load data). There are various tools to enable ETL for the warehouse.
- Store – We are preparing to store data for our present or future information analysis in operational databases or in some other source.
- Analyze – Structuring the raw data into an understandable format helps business analysts or decision-makers to get insights from various analyses and visualizations of the data.
- Consume – At this stage, various tools like Power BI and Hadoop are available to help explore data in detail.
All these stages tell us the structure or process of the data warehouse.
Characteristics of the Data Warehouse
- Integrated: data warehouse concepts are built by integrating data from disparate sources such as relational databases and flat files. This integration enhances effective data analysis. Data must be stored consistently and universally acceptable in a warehouse.
- Nonvolatile: No matter what data it is, it does not change once it enters the warehouse or is not removed from it. Operational and data warehouses are kept separate. So, the frequent changes in the operational database are not reflected in the data warehouse.
- Subject Oriented: Data Warehouses are subject-oriented because they provide information about topics rather than ongoing operations in an organization. Topics may be products, suppliers, customers, etc. A data warehouse concentrates on modeling and analyzing data for decision-making rather than performing day-to-day operations
- Time Variant: Information acquired from the data warehouse is identified by a specific period. The data warehouse would contain information on historical trends.
The Architecture of the Data Warehouse
Data Warehouse architecture comprises a three-tier architectural structure.
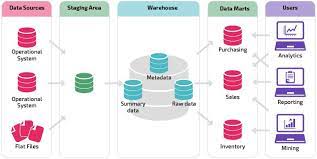
There are 3 approaches for constructing a Data Warehouse architecture
Single Tier Architecture
The main reason for this architecture is to minimize storage levels. The main goal of this architecture is to remove data redundancy.
Two Tier Architecture
It is also one of the Data Warehouse layers that separate physically available sources and the data warehouse. This architecture doesn’t support a large number of end-users, and it is also not expandable.
Three Tier Architecture
The most widely used architecture of the data warehouse concepts consists of a top, middle, and bottom tier.
Bottom Tier
The bottom tier or data warehouse server usually represents a relational database system. To cleanse, transform and feed data into the layer, back-end tools are used.
Middle Tier
It represents an OLAP server that can be implemented in two ways
ROLAP 2. MOLAP
ROLAP (Relational Online Analytical Processing) servers are usually placed between the relational backend server and the client front-end server. It performs dynamic multidimensional data analysis and maps it to a standard relational process.
MOLAP (Multidimensional Online Analytical Processing) deals directly with multidimensional data and operations.
Top Tier
Top Tier is a client-side interface that gets data from the data warehouse. It consists of tools like query tools, analysis tools, reporting tools, and data mining tools.
Data Warehouse Components
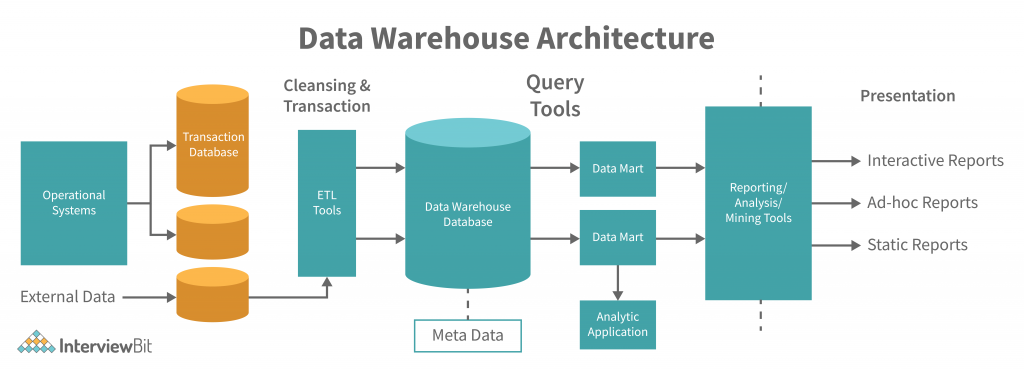
Data Warehouse Database
The most significant component of the Data Warehouse is the database. It was implemented with RDBMS technology. However, this type of implementation is limited because traditional RDBMS systems are optimized for processing transactional databases and not for data warehouses. There are a few alternatives, like deploying RDBMS in parallel, which allows shared memory on various multiprocessor configurations, using new index structures to bypass relational table scans, etc. These are approaches to databases.
ETL (Extract, Transformation, and Loading Tools)
These tools are responsible for extracting data from various sources, transforming it into a digestible format, and loading it into the data warehouse concepts. There are many functionalities like anonymizing data, eliminating unwanted data loading into the Data Warehouse, getting a summary, populating missing data with defaults, etc. In ETL tools. These tools can also generate background jobs, shell scripts, etc., that update data. These tools help maintain the metadata.
Metadata
Metadata is data that defines the data warehouse, which is used in building, maintaining, and managing data warehouses. It provides various frameworks enabling the above usages. These are the essential and critical ingredients in transforming data into knowledge.
Metadata can be classified into two categories.
Technical Meta Data: This contains information about the warehouse which is used by data warehouse designers and administrators.
Business Meta Data: This contains information that is easily understood by end users.
Data Warehouse Access / Query Tools
Access tools allow users to interact with the data warehouse concepts system. These warehouse tools include query and reporting tools, data mining, OLAP, and application development tools.
These tools are divided into four different categories:
- Query and reporting tools
- Application Development tools
- Data mining tools
- OLAP tools
Data Warehouse Bus architecture
This architecture defines the data flow in a data warehousing system and includes a data mart in it. The data flow can be categorized as Up flow, Down flow, Outflow, and Meta flow.
Data Warehouse Reporting Layer
The reporting layer in the data warehouse allows the end user to access the business intelligence (BI) interface or BI database architecture. It acts as a dashboard for visualizing and creating reports and pulling out all the required information.
Data Marts
This is an access level that allows users to access or transfer data. It takes less time and money to build, so it is the most cost-effective option for large-size data warehouses. It is used as a partition of data that is created for a specific group of users.
Life Cycle of a Data Warehousing
Several steps must be followed in order to build a successful data warehouse with implementation.
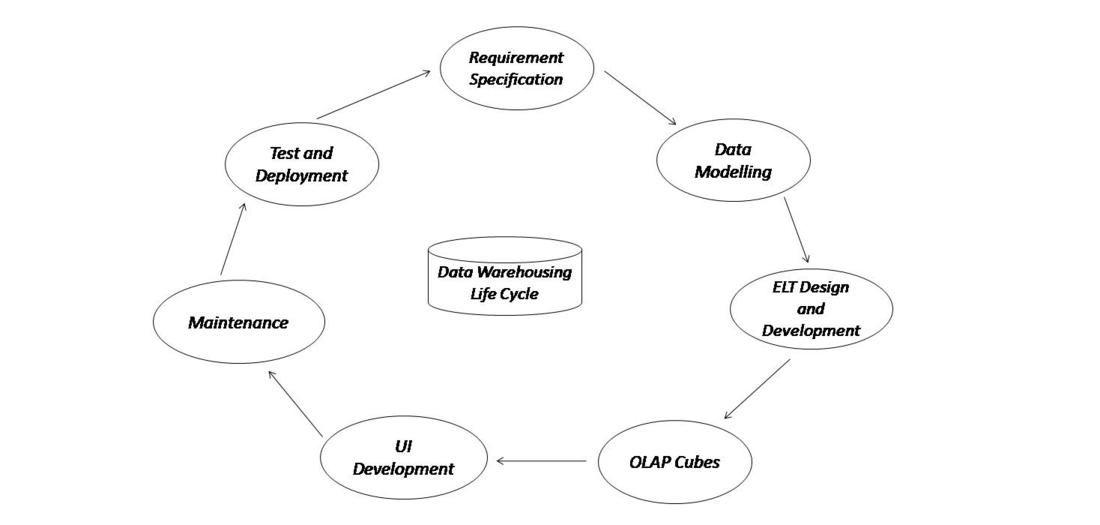
The above diagram indicates the life cycle of data warehousing involving steps for the successful completion of data warehousing.
What is a Cloud Data Warehouse?
A Cloud Data Warehouse is a modern, scalable solution for data storage and analysis that leverages the power of cloud computing. It provides businesses with the ability to store large volumes of structured and unstructured data from various sources, while offering the flexibility to scale up or down based on demand.
Unlike traditional data warehouses that require significant upfront investment in hardware and ongoing maintenance, a cloud data warehouse is hosted on a cloud platform. This eliminates the need for physical infrastructure, resulting in cost savings and increased efficiency.
One of the key advantages of a cloud data warehouse is its scalability. As data volumes grow, businesses can easily increase their storage capacity. Similarly, during periods of low demand, they can scale down to save costs. This flexibility allows businesses to pay only for the resources they use.
Furthermore, cloud data warehouses offer robust data security measures including encryption, access control, and regular backups, ensuring that sensitive business data is protected.
In addition, they provide powerful data processing capabilities. Businesses can run complex queries and data analytics tasks in real-time, gaining valuable insights to drive decision-making.
OLAP and OLTP in Data Warehouses
OLAP (Online Analytical Processing) and OLTP (Online Transaction Processing) are two fundamental types of data processing systems used in data warehouses. They serve different purposes and have distinct characteristics.
OLTP
OLTP is a category of systems that manage transaction-oriented applications. These systems are designed for real-time business operations, such as order entry, financial transactions, customer relationship management, and retail sales. OLTP systems prioritize fast query processing and maintain data integrity in multi-access environments. The main focus of OLTP systems is to capture, store, and process data from transactions in real-time.
Key characteristics of OLTP systems include:
- Operations are complex and involve multiple transactions.
- Transactions are often short and require fast response times.
- Data is often normalized, reducing redundancy and improving data integrity.
- They are optimized for write operations.
OLAP
OLAP is a category of software tools that provides analysis of data stored in a database. OLAP systems are used to perform complex calculations, trend analyses, and sophisticated data modeling. These systems are designed for data analysis and are optimized for read-heavy operations.
Key characteristics of OLAP systems include:
- Operations are less frequent but involve large amounts of data.
- Queries are often complex and involve aggregations.
- Data is often denormalized with pre-calculated totals (aggregates) stored to improve query performance.
- They are optimized for read operations and provide quick responses to analytical queries.
In the context of a data warehouse concept , OLTP systems are typically used as the source of data, as they capture real-time transactional data. This data is then transferred to an OLAP system, where it is used for analytical processing, reporting, and decision-making purposes. The process of transferring and transforming data from an OLTP system to an OLAP system is often performed through a process known as ETL (Extract, Transform, Load).
Schemas in Data Warehouses
Star Schema
- Central fact table with multiple dimension tables
- Fact table contains measures (numeric values) and foreign keys to dimension tables
- Dimension tables contain attributes that describe the fact table
- Optimized for fast aggregation and reporting
Snowflake Schema
- Similar to star schema but with additional dimension tables
- Dimension tables are normalized and can have multiple levels of hierarchy
- Provides more flexibility and detail compared to star schema
- Can be more complex to query and maintain
Galaxy Schema
- Hybrid schema that combines elements of star and snowflake schemas
- Central fact table with multiple levels of dimension tables
- Dimension tables can be normalized or denormalized
- Offers a balance between performance and flexibility
Cube Schema
- Multidimensional data model that represents data as a cube
- Dimensions are organized along axes
- Measures are stored in cells within the cube
- Supports fast aggregation and complex calculations
Inmon Schema
- Top-down approach where data is first integrated into a central data warehouse
- Data is then distributed to subject-specific data marts
- Ensures data consistency and integrity
Kimball Schema
- Bottom-up approach where data is first stored in subject-specific data marts
- Data marts are then integrated into a central data warehouse
- Focuses on delivering data quickly and efficiently to business users
Other Schemas
- Constellation Schema: Similar to star schema but with multiple fact tables
- Bus Schema: A collection of interconnected data tables that represent business processes
- Vault Schema: A highly normalized schema designed for data archival and long-term storage
Latest Tools and Technologies in Data Warehousing
Data Warehousing helps businesses to get deep insights from even large amounts of data. It improved its access to information, reduced response time for queries, etc. Today, cloud technology has reduced the cost and effort to build infrastructure for data warehousing concept. There are various tools and technologies for data warehousing. Cloud-based data warehousing tools are fast, highly scalable, efficient, and available regularly. Some of the Data Warehousing tools are:
- Microsoft Azure
- Amazon Redshift
- Snowflake
- Google Big Query
- Micro Focus Vertica
- Amazon DynamoDB
- PostgreSQL
- Amazon s3
- Teradata
- Amazon RDS
- IBM Db2 Warehouse
- Oracle Autonomous Warehouse
- MariaDB
- MarkLogic
- Cloudera
These are some of the Data Warehousing tools.
Conclusion
Data warehousing transforms businesses by consolidating diverse data sources, facilitating insightful analysis, and enabling informed decision-making. Its integrated, non-volatile, subject-oriented, and time-variant characteristics ensure data integrity and relevance. The architecture, components, and lifecycle of data warehousing exemplify its systematic approach to data management. With the advent of cloud-based solutions, organizations benefit from scalable, efficient, and cost-effective data warehousing tools. Ultimately, data warehousing empowers businesses to harness the full potential of their data, driving strategic growth and competitive advantage in today’s data-centric landscape.
Key Takeaways
- Data Warehouse is a system that contains historical and commutative data from multiple sources. These sources can be Cloud Data Warehouse, Virtual Data Warehouse, or Traditional Data Warehouses.
- Data Warehouse is subject-oriented, non-volatile, and Time-variant.
- Data Warehouse metadata provides information regarding the data warehouse data’s source, usage, and features.
- Data Sourcing, transformation, and migration tools perform all conversions and summarizations.
Q1. What is data warehousing, and how does it differ from traditional databases?
A. Data warehousing is a process of collecting and managing data from various sources to provide meaningful insights for decision-making. Unlike traditional databases, data warehouses are designed for analytical queries rather than transactional processing.
Q2. What are the key characteristics of a data warehouse?
A. Key characteristics include being subject-oriented, integrated, non-volatile, and time-variant (often abbreviated as SNIT)
Q3. How does data warehousing contribute to business intelligence and decision-making?
A. Data warehousing facilitates data analysis and reporting, enabling organizations to gain insights into historical trends and patterns, which in turn supports informed decision-making
Q4. What are the main components of a data warehouse architecture?
A. Components include data sources, ETL (Extract, Transform, Load) tools, the data warehouse database, metadata, data access/query tools, and the reporting layer.
Q5. What is the ETL process, and why is it crucial in data warehousing?
A. ETL (Extract, Transform, Load) is the process of extracting data from various sources, transforming it into a consistent format, and loading it into the data warehouse concept. It’s crucial for ensuring data quality and consistency.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
I am a Pre-final Year B.Tech Student pursuing Computer Science and Engineering from Vellore Institute of Technology. A tech enthusiast with avid enthusiasm to learn and explore. I am kneeling interested in AI-ML, Data Science. I am interested in expanding my knowledge in various fields. I'm curious, passionate, and focused on learning new things and implementing the same in solving real-world problems. I truly believe in teamwork to maximize the benefits of various perspectives on an idea and increase effectiveness.







