This article was published as a part of the Data Science Blogathon.

Source: Canva
Introduction
Conventionally, an automatic speech recognition (ASR) system leverages a single statistical language model to rectify ambiguities, regardless of context. However, we can improve the system’s accuracy by leveraging contextual information. Any type of contextual information, like device context, conversational context, and metadata, such as the time the request was issued, etc., could be utilized to customize the underlying ASR model of the conversational agent (Alexa in our case).
In this article, we will understand the need for contextual ASR and will also go over how the context vector is created in Alexa and the issues this process presents.
Highlights
-
Contextual information like the text of a user’s request, the history of the user’s recent interactions with a virtual assistant, and metadata like the time the request was issued can be used to customize the underlying ASR model to make a context-aware VA.
-
Alexa temporarily stores relevant context information on AWS’s DynamoDB server, and a two-table system is employed for storing that information. Only Alexa’s utterances that trigger follow-up questions pass to the context embedding model.
-
The event of re-opening the microphone to listen for a response triggers the creation of the context vector.
-
The context model has access to the texts of Alexa’s responses before Alexa speaks them, and the instruction to reopen the microphone follows immediately upon the instruction to begin the reply, giving Alexa a brief window to create the context vector.
What’s the Need for Contextual ASR?
Automatic speech recognition (ASR) is a technique that allows the conversion of acoustic speech to text, and Alexa uses the same core ASR model across users for any given language. However, the accuracy of speech recognition can be enhanced by adapting the ASR models to the user context on the fly.
Let’s examine the following examples to comprehend better the significance of context inclusion in improving speech recognition:
Example 1: Acoustic features of the speaker’s voice during the utterance of the wake word “Alexa” could be used as a context for filtering out the background voices/noise when processing a user’s request.
Example 2: Accuracy of speech recognition could be further enhanced by leveraging the “device context”. For instance, a screen-equipped device might present a list of potential responses to a query, and Alexa can bias the ASR model toward the list entries when subsequent instructions are processed. Moreover, this can also aid in offering accurate/relevant services and solutions.
Example 3: Let’s say the underlying language model needs to determine the likelihood that the next word in the utterance “Alexa, get me a…”. The chances of the next word being “cake” or “cab” would be very different depending on whether the user had recently requested Alexa about the nutrient value of foods or the state of the local traffic. So, the user’s current request and the history of the user’s interaction with Alexa could be used as context to prompt relevant output/service.
Example 4: Even the conversational context could be leveraged to boost the accuracy of the ASR when Alexa asks follow-up questions to verify its understanding of commands. For instance:
User: “Alexa, call Divyansh.”
Alexa: “Do you mean Divyansh Sharma or Divyansh Gupta?”
User: “Sharma.”
When Alexa hears the word “Sharma” in the second dialogue turn, it tends to favor the interpretation “Sharma” over the more specific word “derma” based on the previous turn’s context. Notably, conversational-context awareness reduces the ASR error rate by almost 26% during such interactions.
The underlying ML model considers the current user utterance, the text of the previous dialogue turn (both Alexa’s response and the user’s turn), and pertinent context information from the Alexa services invoked by the utterance. This could include entries from an address book, a list of Alexa-connected smart home devices, or the local-search function’s classification of names mentioned by the user — names of movie theaters, gas stations, restaurants, and so on. This inclusion of contextual information improves speech recognition.
Now that we have explored enough examples to understand the significance of the inclusion of context in ASR systems, let’s take a look at the challenges and solutions encountered while implementing a context-aware ASR system in Alexa.
Challenges and Solutions
The fact that Alexa uses a large neural network trained on different tasks to produce a running sequence of vector representations or embeddings of utterances of the user and Alexa’s responses presents the following challenges:
Challenges: The key engineering problem is we can not predict which interactions with Alexa will necessitate follow-up questions and responses. Furthermore, embedding context information is a computationally demanding process. It would be a waste of resources to subject all user utterances to that process when only a small percentage of them could result in multi-turn interactions.
To navigate the aforementioned challenges, the following solutions are proposed and utilized in Alexa:
Solutions: Alexa temporarily stores relevant context information on AWS’s DynamoDB server; utterances are time stamped and are automatically deleted after a set time. Only Alexa’s utterances that prompt follow-up questions pass to the context embedding model.
Like all other storage options provided by AWS, DynamoDB encrypts the data it stores, so updating an entry in a DynamoDB table necessitates decrypting it first. Additionally, a two-table system is employed for storing contextual information. One table records the system-level events associated with a particular Alexa interaction, like the request to transcribe the user’s utterance and the request to synthesize Alexa’s response.
Each event is represented by a single short text string in a table entry. The entry also contains references to a second table, which stores the encrypted texts of the user utterance, Alexa’s reply, and any other contextual data. Each data item is listed separately, so once it is written, it does not need to be decrypted until Alexa has created a context vector for the associated transaction.
When’s the Context Vector Created?
As we discussed in the previous section, we can not predict which interactions with Alexa will necessitate follow-up questions and responses. Given that only a small percentage of user utterances might result in multiturn interactions, it would be computationally expensive to subject all user utterances to the context embedding generation process. And suppose the context vector is not created until the requirement arises. In that case, this presents a challenge because it necessitates the execution of a complex computation in the middle of a user’s interaction with Alexa. The workaround is to conceal the computation time beneath Alexa’s response to the user’s query.
A user utterance initiates all Alexa interactions, and almost all user utterances elicit replies from Alexa. The event that triggers the creation of the context vector is re-opening the microphone to listen for a response. The context model has access to the texts of Alexa’s responses before Alexa speaks them, and the instruction to reopen the microphone follows immediately upon the instruction to begin the reply, giving Alexa a brief window to create the context vector.
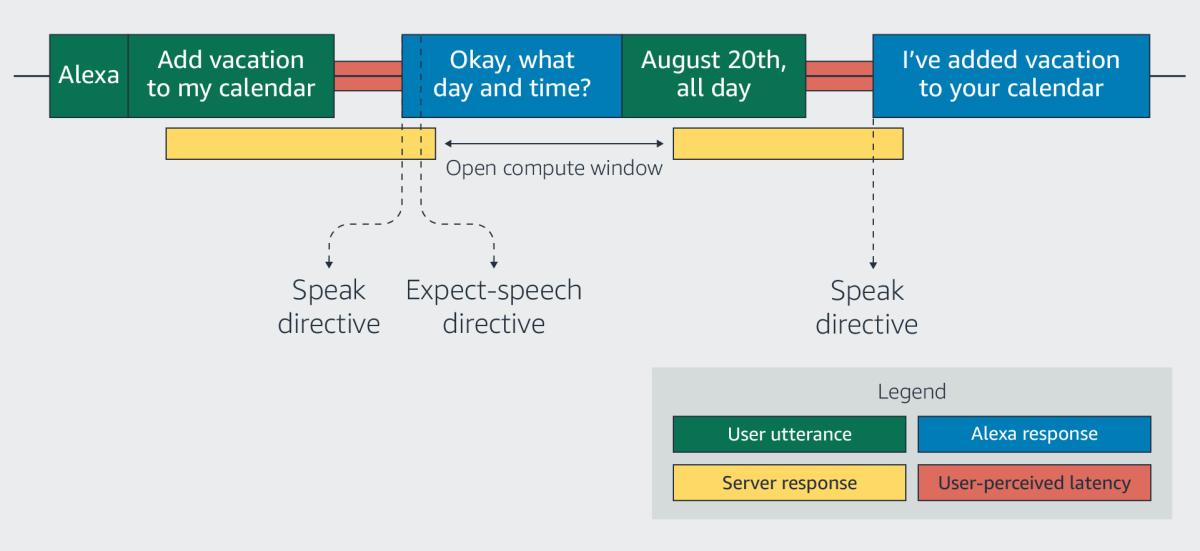
Figure 1: Diagram illustrating the computation window of the context vector in Alexa
Because the instruction to re-open the microphone (expect-speech directive) comes right after the instruction to begin executing Alexa’s reply (speak directive), the reply itself buys the context model enough time to produce a context vector, see figure 1 for reference. If the context model fails to generate a context vector in the set time, the ASR model functions as it normally does, without any contextual information.
To enable contextual ASR in real-time, DynamoDB is leveraged, which uses redundancy to ensure data availability; any data written to a DynamoDB server is copied multiple times. However, if there is a high load for the database, updating the copies of newly written data may take longer. As a result, a read request forwarded to one of the copies may sometimes retrieve outdated information.
To prevent this, Alexa adds new information to the contextual-ASR data table each time. She simultaneously requests the most recent version of the entry recording the interaction’s status, ensuring that it never receives stale information. If the entry contains a record of the crucial instruction to re-open the microphone, Alexa initiates creating the contextual vector; otherwise, Alexa simply discards the data.
Advantages of Contextual ASR
Some of the benefits of leveraging contextual information in an ASR system are as follows:
1. Inclusion of conversational-context awareness reduced the ASR error rate by almost 26% during interactions.
2. It improves the recognition of named entities such as people, businesses, locations, etc. This is particularly critical for virtual assistants considering that the meaning of a sentence may get lost if its named entities are incorrectly identified, which can further aid in offering accurate search results/solutions.
Conclusion
To sum it up, we learned the following in this article:
1. The accuracy of speech recognition can be enhanced by adapting the ASR models to the user context on the fly.
2. Any type of contextual information, such as the text of a user’s request, the history of the user’s recent Alexa interactions, and metadata, such as the time the request was issued, can be used to build context-aware virtual assistants.
3. Alexa temporarily stores relevant context information on AWS’s DynamoDB server, and a two-table system is employed for storing that information. Only Alexa’s utterances that prompt follow-up questions pass to the context embedding model.
4. The event that triggers the creation of the context vector is re-opening the microphone to listen for a response. The context model has access to the texts of Alexa’s responses before Alexa speaks them, and the instruction to re-open the microphone follows immediately upon the instruction to begin the reply, giving Alexa a brief window to create the context vector.
That concludes this article. Thanks for reading. If you have any questions or concerns, please post them in the comments section below. Happy learning!
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
I'm a Researcher who works primarily on various Acoustic DL, NLP, and RL tasks. Here, my writing predominantly revolves around topics related to Acoustic DL, NLP, and RL, as well as new emerging technologies. In addition to all of this, I also contribute to open-source projects @Hugging Face.
For work-related queries please contact: [email protected]





