This article was published as a part of the Data Science Blogathon.
Introduction
Numerous music players have been created with capabilities like fast forward, backward, variable playback speed (seek and time compression), local playback, and streaming playback with multicast broadcasts in the modern world due to the rapid improvements in multimedia and technology. Although these capabilities serve the user’s fundamental needs, the user is still required to actively browse through the music playlist and choose songs depending on his present state of mind and behavior.
In this article, we will create a recommender that recommends music according to the user’s current mood using CNN Model.
Importance of Emotion Recognition:
1. Human face detection plays a vital role in applications such as video surveillance, human-computer interface, face recognition, and face image database management.
2. Facial expressions are important cues for nonverbal communication among human beings. It is only possible because humans can recognize emotions quite accurately and efficiently. Automatic facial emotion recognition has many commercial uses and can be used as a biological model for cognitive processing and analysis of the human brain.
3. Collectively, they can enhance their applications like monitoring and surveillance analysis, biomedical image, bright rooms, intelligent robots, human-computer interfaces, and driver’s alertness systems and play a vital role in security and crime investigations.

Methodology Used
The proposed system is a music controller based on automatic emotion detection. A webcam is used to capture the images that will be used as input to the proposed method. It goes to the expression detector to classify it into one of eight classes Happy, Natural, Sad, Angry, Contempt, Fear, Surprise, and Disgust.
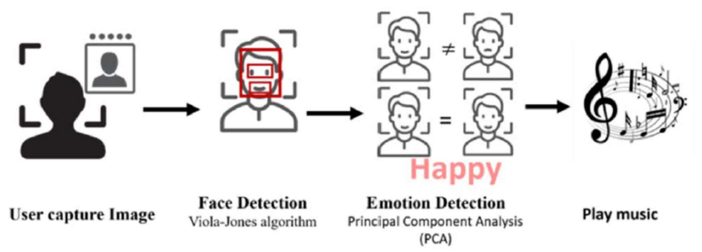
Image Acquisition:
As a first step in the proposed system, we begin by acquiring the image of the user’s face using a built-in laptop webcam (or any external camera that can be employed). To be correctly processed in the proposed system, the face image must contain one face in the frontal position in a uniformly illuminated background. Also, it should not be on the user’s face, anything that could impede the detection process, such as glasses.
Face Detection:
After acquiring the image, the system will start to detect the face by applying the Viola-Jones algorithm. This algorithm is considered one of the first frameworks that recognize objects in real-time. Viola-Jones scan the images using a sub-window to detect the features of the face in the picture. When the face is determined, the image is cropped to contain the face only to enhance the proposed system’s performance. Also, the Viola-Jones is reused to identify and crop the left and right eyes and mouth separately. The outcome of this step is four images, face, right eye, left eye, and mouth.
Emotion Detection:
Next, we must detect user sentiment. We use the Fisher Face method. A well-known approach is often used to detect facial emotions. It will construct the face space, and the eigenvectors with the highest eigenvalues will be selected. Also, we will project the acquired image over the face space. After that, the emotion is detected by computing for the user image the scores for each emotion. The feeling of the image is determined by getting the maximum score of the calculated emotion scores.
Enabling the correspondent Emotion playlist:
The proposed system will present the correspondent music playlist depending on the detected emotion. Since we have four emotions, we also have four playlists that offer music clips that are carefully chosen. The classical music playlist will be activated for happy emotions, while the new age music playlist is dedicated to the natural emotion. For the negative and sad feelings, we will enable the designer music playlist to enhance the user’s mood to a better mood.
Dataset Used
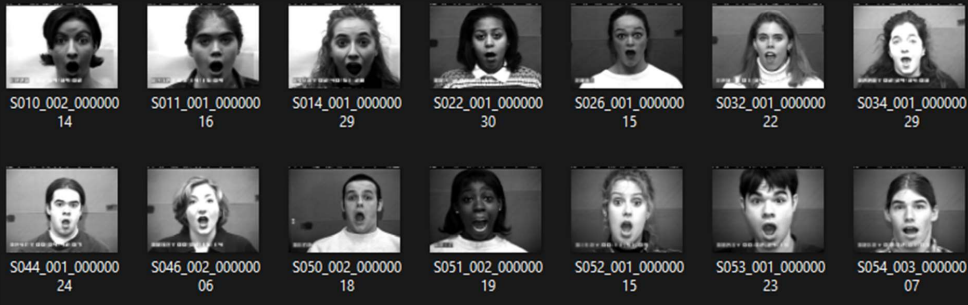
We test the proposed system on datasets comprising a wide range of face images with different expressions, poses, illumination conditions, and genders. We used CK and CK+ databases to train the emotion detection system. We test the algorithm on the IMM database and our test images. Both databases are open source, and our algorithm performed well on both datasets. For face recognition, we have used a webcam to capture faces. The implemented algorithm is capable of recognizing different persons in a single window. The recognition rate will be high if the recognition environment is under proper lighting conditions and has fewer background noises.
They release the Cohn-Kanade (CK) database to automatically promote research into detecting individual facial expressions. CK database has become the most widely used test bed for algorithm development and evaluation.
As a result, comparison with benchmark algorithms is absent, meta-analyses are challenging, and the CK database has been used for AU and emotion recognition. Cohn-Kanade Extended (CK+) database. Sequence counts rose by 22%, while subject counts rose by 27%. Each sequence’s target expression has a complete FACS code, and emotion labels have been updated and verified.
You can download the dataset here.
1. Anger
2. Contempt

3. Disgust
4. Fear

5. Happy

6. Neutral

7. Sad
8. Surprise
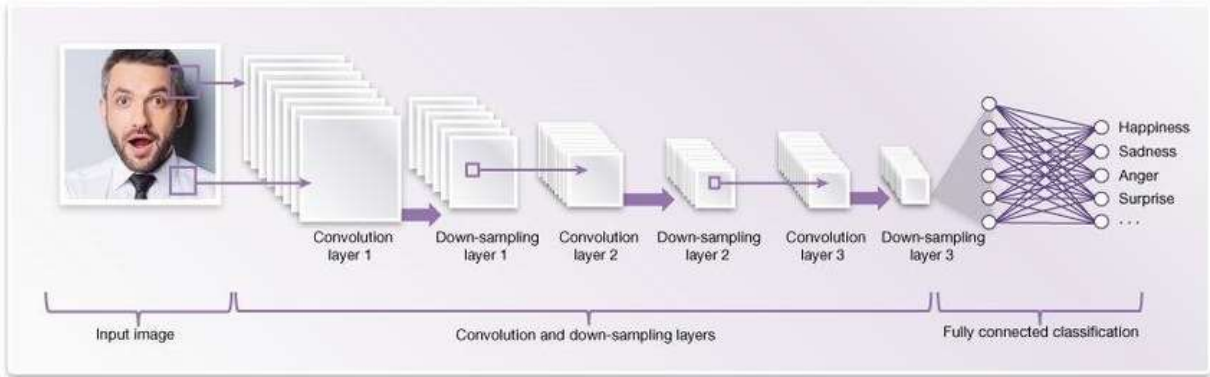
CNN Model Implementation
We will input our image and feed it into our CNN model. After passing the image through several layers like Convolutional 2D, Max Pooling, Dense Layers, etc., we will output the expression of the face expressed in it.
Then we will use that expression to select the songs which satisfy the user’s mood.
We will classify the expressions into these many classes: Happiness, Sadness, Anger, Surprise, etc. Below is our complete machine learning pipeline used in this project with our CNN model.
Step-1:
Below are all the necessary libraries used in this article
import libraries cv2, argparse, time , os , update_Model , glob , random , eel , light.
Step-2:
Below are all the classes of different facial expressions.
Take emotions "angry", "happy", "sad", "neutral" , "contempt", "disgust" , “fear" and “surprise” from the directory.
Step-3:
The below function crops the images and resizes them into a fixed shape.
Function crop{
for( all the dimensions ) in face :
faceslice = clahe_image[increase X axis and Y axis]
faceslice = resize(faceslice(to needed dimensions))
arrayfacedict[ ] = faceslice
RETURNS faceslice
}
Step-4:
This function will read the face from the directory folder and sends it for further processing.
Function grab_face{
SETS frame = nolight() ;
SETS imwrite(image file , frame)
SETS imwrite(send to directory)
clahe_image = apply(gray) //for the grey scaling
RETURNS clahe_image
}
Step-5:
It will detect the face coordinates from the image. We will require only their coordinates to crop them and discard the remaining part.
Function detect_face{
CALLS grab_face()
IF(length of face ) >= 1 :
crop the image :
ELSE PRINT— “Multiple faces detected!!, passing over the frame, try to stay still")
}
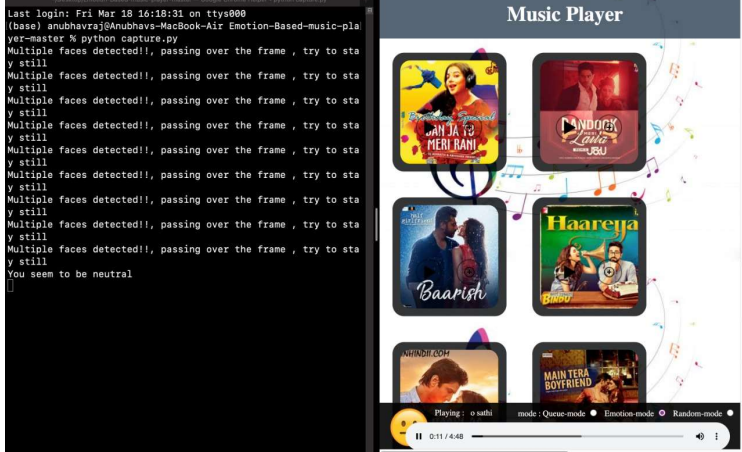
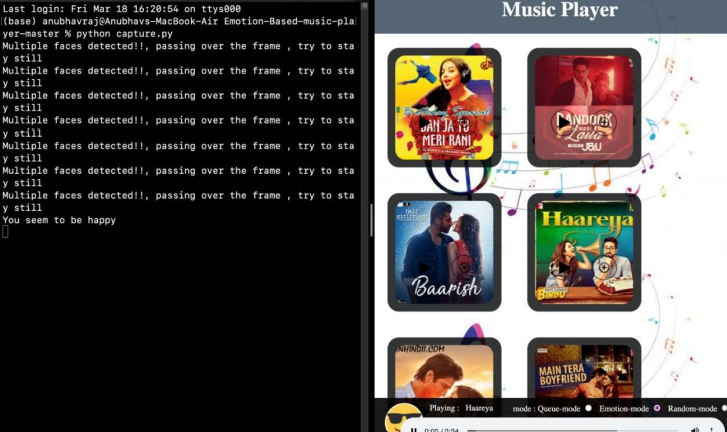
Results of CNN Model
1. When a Neutral face is detected
2. When a Happy face is detected
3. When an Angry face is detected
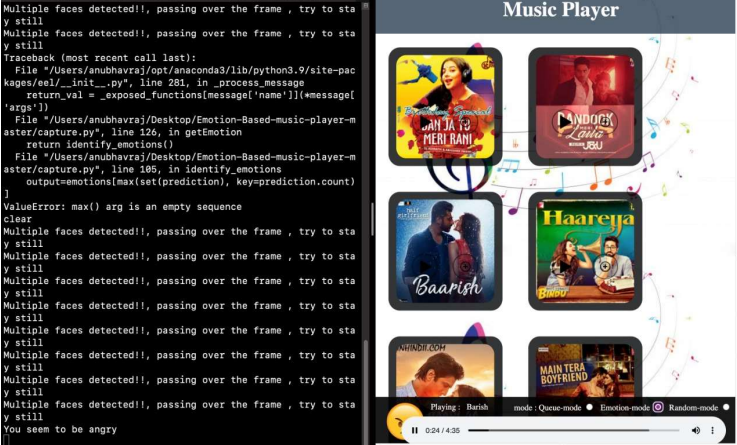
Conclusion
We have discussed how we can make a music recommender system that can detect the user’s facial expression and then recommend songs according to the user’s mood using CNN model.
In the current era, there is a huge need for a recommendation system. It helps users to get personalized recommendations. It also improves sales, browsing experience, retention of customers, and many more. Famous online streaming websites like gana.com and spotify.com uses very complex recommendation algorithms to recommend users’ favorite songs so that they can spend more time on their platform.
Key takeaways:
1. Firstly, we have discussed the complete methodology recommendation systems. In this, we have talked about image acquisition (how the image is taken from the dataset), face detection (how can we detect a face from the image), and emotion detection (how can we identify the emotion from the detected face).
2. Then, we discussed the Cohn-Kanade dataset, the total number of samples present, and the number of different facial expressions. It consists of seven types of expressions: anger, sadness, happiness, etc.
3. Discussed the complete deep learning pipeline, the CNN Architecture, OpenCV functions, Face Detection functions, etc. We have used Conv2D, max-pooling, and dense layers to train our CNN model. I also discussed the results of CNN model at last.
End of the article, thank you.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.






Great article for a beginner!