This article was published as a part of the Data Science Blogathon.
Introduction
In today’s world, we know that we interact greatly with our smart devices. Have you ever wondered how your Smartphones and your personal computers interact? That is where NLP comes into the picture. In simple terms, NLP helps to teach computers to communicate with humans in their language.
For instance, Grammarly. Grammarly will use NLP to check for errors in grammar and spelling and make suggestions. Another interesting example would be our virtual assistants like Alexa or Siri. They will perform speech recognition to interact back with us. It can also be used to analyse a particular sentence’s sentiment or mood.
How does NLP Work?
In Natural language processing, before implementing any kind of business case, there are a few steps or preprocessing steps that we have to attend to. It is not like machine learning preprocessing.
1. Cleaning data
2. Tokenization
3. Stemming
4. POS Tagging (Part of Speech Tagging)
5. Lemmatization
6. NER (Named Entity Recognition)
If we want to implement a sentiment analysis, we need words. For words in the data provided to be understood, they must be clean, without any punctuation or special characters. And then convert it to lowercase.
Unlike machine learning, we work on textual rather than numerical data in NLP. We perform encoding if we want to apply machine learning algorithms to this textual data. But we will have a large number of words to be converted. So we create a bad of words model. In the end, depending on the problem statement, we decide what algorithm to implement.
Popular NLP Libraries
- NLTK (Natural Language Toolkit)
- SpaCy
- Stanford NLP
- Open NLP
Sentiment Analysis
Sentiment analysis is a natural language processing (NLP) technique used to determine whether data is positive, negative, or neutral. Sentiment analysis is often performed on textual data to help businesses monitor brand and product sentiment in
customer feedback, and understanding customer needs.
Example of an NLP sentiment analysis:
Sentiment Analysis of Most talked-about series “Shark Tank”
Code: https://colab.research.google.com/drive/1qJmNM6U09aI_eQ_bUDgzpzqWTo-Lh2YM?usp=sharing
Sentiment Analysis on Twitter data on business reality television series “Shark Tank”. How is it the trending reality show on TV? Is it popular with positive reactions/ Negative reactions?
For this study, 500 tweets from Twitter is collected. Access to a Twitter Developer Account will be used in this study to allow for more efficient Twitter data acquisition. The Tweepy python package will be used to obtain 500 Tweets via the Twitter API. When tweets are collected for this reality show with a location filter of “India” the drawback is there are not enough tweets collected that can be used for analysis. To collect appropriate threads, I have used the keyword “Shark Tank” and “shark tank Memes” to collect the tweets across the globe. These keywords are not case-sensitive. The tweets gathered from these keywords are merged into a single data frame.
Another important concept used in the collection of data is snscrape.
Snscrape
Snscrape is a scraper for social media platforms (SNS). It scrapes information such as user profiles, hashtags, and searches and provides the results.
The data frame formed is used to analyse and get each tweet’s sentiment. The data frame is converted into a CSV file using the CSV library to form the dataset for this research question.
- The number of tweets collected for “Shark Tank” is 380.
- The number of tweets collected for “shark tank Memes” is 428.
- The total data collected for this study is 818 rows.
Interface and Packages Used to do Sentiment Analysis
The purpose of sentiment analysis, regardless of the terminology, is to determine a user’s or audience’s opinion on a target item by evaluating a large volume of text from numerous sources. Depending on your objectives, you may examine text at varying degrees of depth.
Jupyter notebook
The original web application for producing and sharing computational documents is Jupyter Notebook. It provides a straightforward, simplified, and document-focused environment.
1.Textblob
TextBlob is a text processing library for Python 2 and 3. It offers a basic API for doing standard natural language processing (NLP) activities including part-of-speech tagging, noun phrase extraction, sentiment analysis, classification, and translation, among others.
TextBlob is an emotion analyzer based on a lexicon. It contains certain predetermined rules, or a word and weight dictionary, with some scores that assist compute the polarity of a statement. Lexicon-based sentiment analyzers are sometimes known as “Rule-based sentiment analyzers” for this reason.
2.matplotlib.pyplot
This library is used for visualization and plotting.
3. re
Regular Expression is a search pattern made up of a series of characters.
4.WordCloud, STOPWORDS
5. Image
6.nltk.sentiment.Vader -SentimentIntensityAnalyzer
7.langdetect import detect
8.nltk.stem import SnowballStemmer
Functions Defined for Analysis of the Dataset
Code implemented to perform the analysis is implemented in python.
Cleantweets
The next step in the analysis is to clean the tweet for punctuation and remove ‘@’,’#’,’:’,’_’, and hyperlinks. For this, the function “clean tweets” is defined using re package (Regular Expression).
getSubjectivity
It is used for calculating the subjectivity of the tweet. Subjective statements usually refer to personal feelings, emotions, or judgments, whereas objective phrases refer to facts. Subjectivity is also a float with a value between 0 and 1.
getPolarity
It is used for calculating the polarity of the tweet. Polarity is the perspective of the stated emotion determined by the element’s sentiment, which determines whether the text communicates the user’s positive, negative, or neutral feelings toward the entity in question. Two new columns of subjectivity and polarity are added to the data frame.
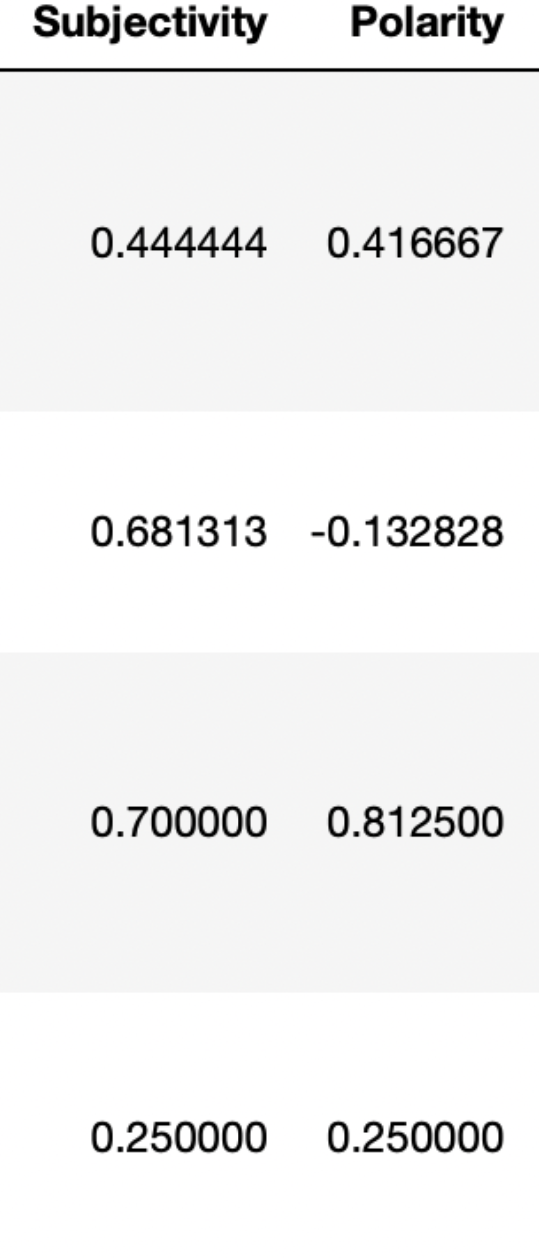
Figure 1: Subjectivity and Polarity
Word Cloud
Simple text analysis is represented by word clouds, and visual representations of text data. Word clouds show the most important or frequently used words in a passage of text. A Word Cloud will often exclude the most frequent terms in the language (“a,” “an,” “the,” and so on).

Figure 2: Word cloud
Results
The popularity of the show is calculated by performing an analysis. A function is defined to classify the tweet into three categories. The three categories
1. Positive
2. Neutral
3. Negative
getAnalysis
This is defined as splitting the tweets based on the polarity score into positive, neutral, or negative. If the score is less than zero, it is a negative tweet. If the score equals zero, it is considered a neutral tweet. Otherwise, it is considered a positive tweet. A new column, “Analysis”, is added to the data frame.
After performing this analysis, we can say what type of popularity this show got. Visualizing the type of popularity by tweet type.
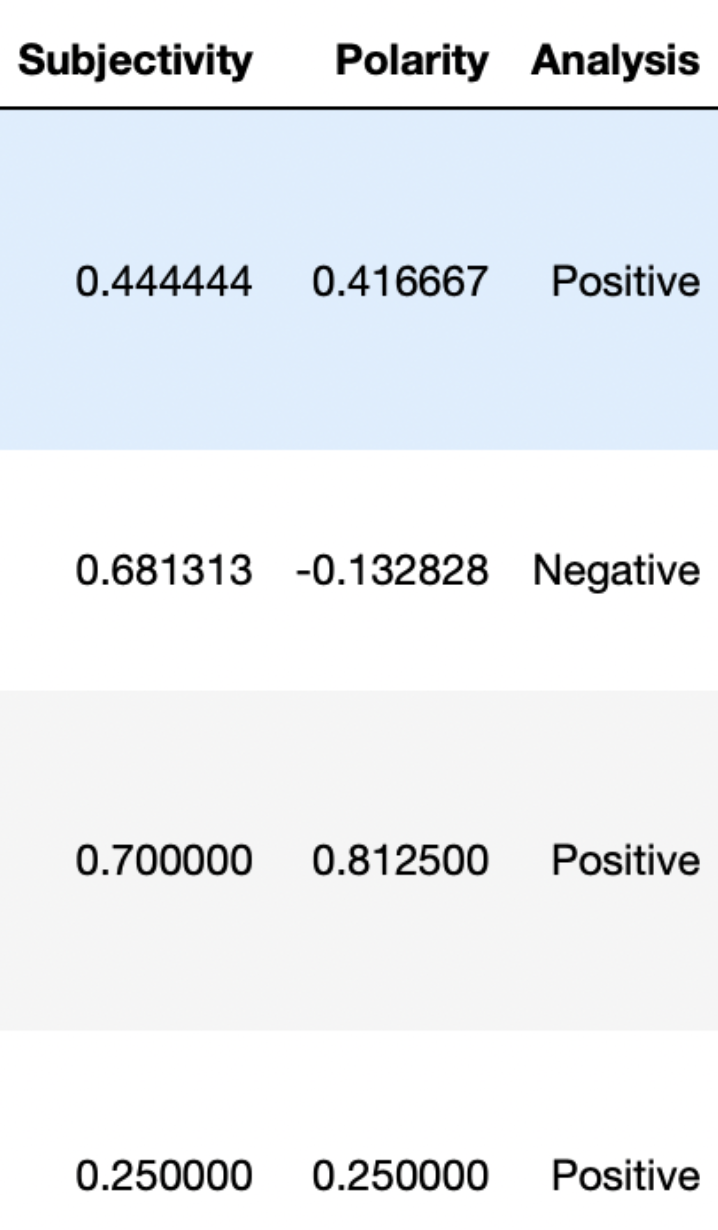
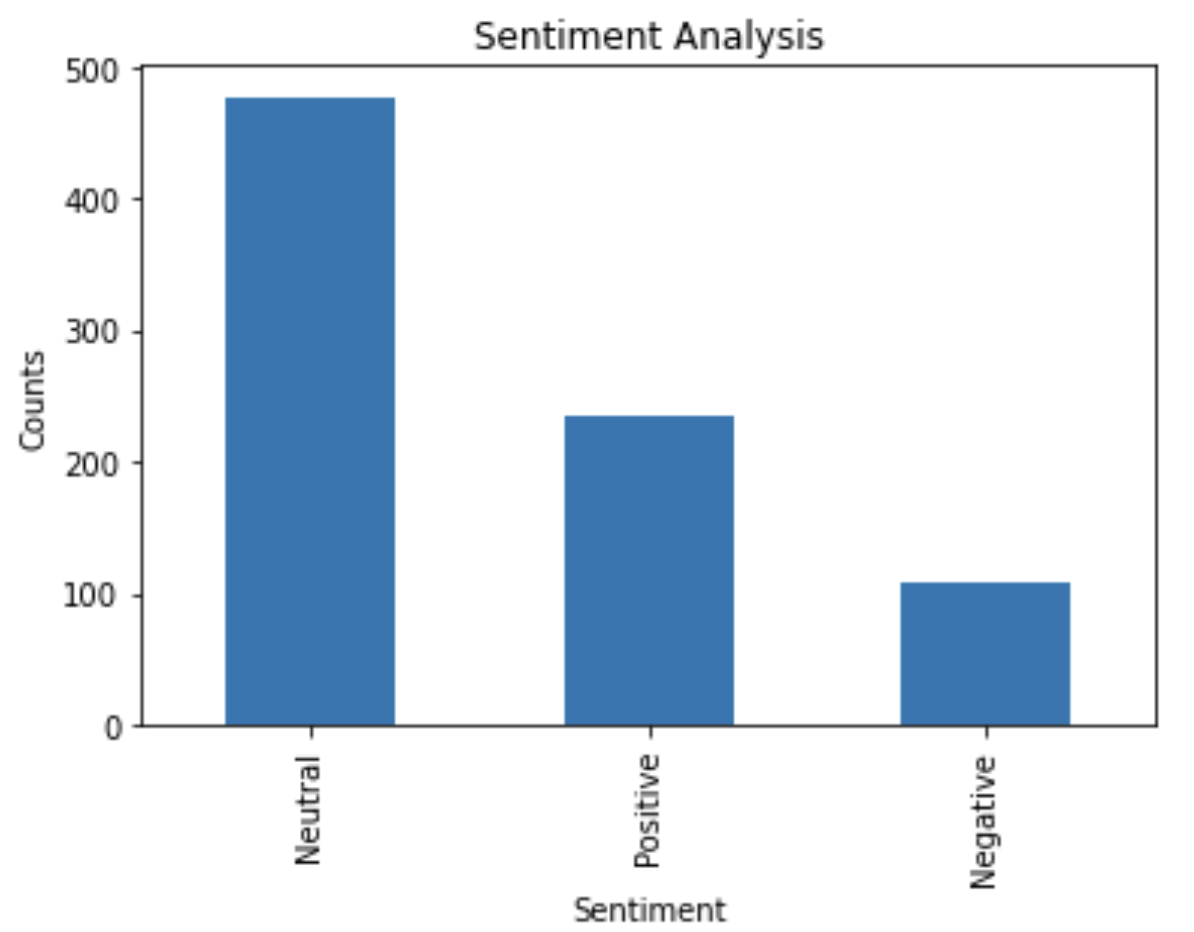
Figure 4: Visualization of sentiment analysis
Conclusion and Limitations
We can see that there are more neutral reactions to this show than positive or negative when compared. However, the visualizations clearly show that the most talked about reality show, “Shark Tank”, has a positive response more than a negative response.
Opinions may vary across different countries towards this show. This study aimed to study people’s sentiments in India, but this did not have enough tweets to filter. This is not because there are not so many tweets. Instead, this study could be achieved if the tweet had a location tagged.
References
- https://github.com/MartinBeckUT/TwitterScraper/blob/master/snscrape/cli-with-python/snscrape-python-cli.py
- https://towardsdatascience.com/step-by-step-twitter-sentiment-analysis-in-
- https://towardsdatascience.com/step-by-step-twitter-sentiment-analysis-in-%20python-d6f650ade58d
- https://link.springer.com/article/10.1007/s12065-019-00301-x
- https://monkeylearn.com/blog/sentiment-analysis-of-twitter/
- https://medium.com/dataseries/how-to-scrape-millions-of-tweets-using-snscrape-195ee3594721
- https://youtu.be/ujId4ipkBio
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Hi, I’m Usha!
As a Data Science professional with a Master's from Indiana University and a Bachelor's in Computer Science & Engineering, I excel in transforming complex data into actionable insights. I specialize in advanced data visualization, AI solutions, and regulatory reporting, using tools like Python, R, and SQL.
I have a proven track record of enhancing productivity and reducing errors through innovative AI solutions and data analysis. My strong analytical skills are complemented by my ability to communicate complex concepts clearly and work effectively in collaborative environments.
Passionate about driving innovation and making data-driven decisions, I am eager to leverage my expertise in digital media and other dynamic industries. If you're looking for a skilled data scientist who can turn data into strategic assets, let's connect!





