Introduction
Building a good resume has always motivated every student out there to get hired by their dream company. Thousands of people from various platforms like Linkedin, naukri.com, etc., start applying as the company starts its recruitment process. It’s highly impossible to, of course, interview everyone who applies. Here comes artificial intelligence’s resume screener (Word2Vec) for identifying good resumes and shortlisting those for interviews.
After cleaning the data with NLP methods such as tokenization and stopword removal, I used Word2Vec from gensim for word embeddings. Using these word embeddings, the K-Means Algorithm is used to generate K Clusters. Some of the clusters in this list contain skills (Tech, Non-tech & soft skills).

Learning Objectives
In this article, you will-
- Identify the layout of the resume and determine the flow of content.
- Learn about Word2vec
- How does Word2Vec help in extracting skills from resumes?
Table of Contents
- Dictionary Approach for Resume Screening
- What is Word2Vec?
- How is Word2Vec Effective for Skill Matching?
3.1 Training the word2vec model
3.2 Reading the resume and performing tokenization
3.3 Finding the similarities between JD skills and resume tokens. - Drawbacks of Word2Vec Skill Matching
- Script
- Conclusion
Dictionary Approach for Resume Screening
A resume screener usually includes the following steps:
- Reading resume
- Layout Classification
- Identifying the resume’s layout is essential since it determines the flow of content within the resume
- Section Segmentation
- Identifying the section headers and segmenting the resume using these headers like Educational Qualification, Work Experience, Skill Set sections, etc.
- Information extraction Includes
- Candidate’s Primary Details
- Skill Set
- Academic Details
- Work Experience
- Company and job designation
- Job Location
Skill set extraction includes identifying the technical skills present in the resume and matching them with JD’s mandatory skills. The easiest way of extraction is by checking its presence in the technical skills dictionary in the backend. Usually, JD has domains specified in it as skills, and hence the skills in the dictionary need to be mapped to its domain.
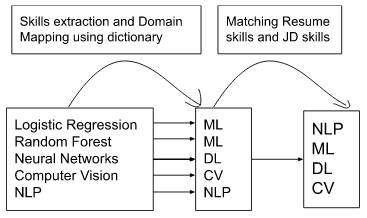
What if the skills mentioned in the resume are missing in the dictionary? What if a resume skill is not mapped to its domain? Simple, the resume will be rejected!
To solve this problem, instead of checking for the presence of a skill in the dictionary, checking for the presence of a skill or its relevant skills will be more efficient. A deep learning architecture has been introduced in this article to match resume skills with JD skills efficiently.
What is Word2Vec?
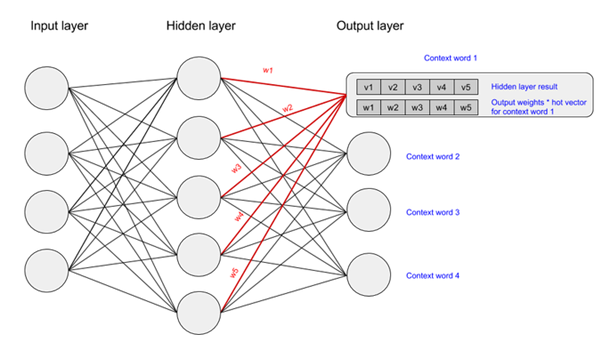
Word2Vec is one of the word embedding architectures for transforming text into numerics, i.e., a vector. Word2Vec is different from other representation techniques like BOW, One-Hot encoding, TF-IDF, etc., as it captures semantic and syntactic relationships between words using a simple neural network with one hidden layer. In short, the words that are related will be placed close to each other in the vector space. The weights obtained in the hidden layer after the convergence of the model are the embeddings. So, using word2vec, we can perform tasks like next word/words prediction based on the two different Word2Vec architectures
- Continuous Bag of Words
Given a sequence of words, i.e., context words, it predicts a word that is highly probable to occur next. - Skip Gram
It works exactly opposite to CBOW, which is given the word, it predicts the next t context words.
Click on this link to know more about Word2Vec
How is Word2Vec Effective for Skill Matching?
How’s word2vec useful in matching resume skills with JD? The solution is just three simple steps:
- Training the word2vec model
- Reading the resume and performing tokenization
- Finding the similarities between JD skills and resume tokens.
Training the word2vec model
- Note – Our implementation is limited only to data science resumes. It can further be generalized by improving the data.
Importing all the necessary libraries
import gensim from gensim.models.phrases import Phrases, Phraser from gensim.models import Word2Vec import pandas as pd import joblib
Data Collection:
-
- Web scraping
- Data is collected by scraping data from various data science-related websites, e-books, etc., using python’s beautiful soup.
- Data Preprocessing
- Lower case conversion
- Removal of numerics
- Removal of stop words
- Web scraping
Stemming and lemmatization are not performed to avoid the loss of vocabulary. For example, when “Machine Learning” is stemmed or lemmatized, the words “machine” and “learning” will be stemmed or lemmatized separately. Thus, it results in “machine learning” and, thus, loss of skill.
Here’s our sample data
Creating n-gram words using gensim’s phrases class. The data is passed to the phrases class and returns an object. The object returned can be saved locally and used whenever required.
df=pd.read_csv('/content/data_100.csv')
sent = [row.split() for row in df['data']]
phrases = Phrases(sent, min_count=30, progress_per=10000)
sentences=phrases[sent]
Vocabulary Building using Gensim library:
Word2Vec requires us to build the vocabulary table (simply digesting all the words, filtering out the unique/ words, and doing some basic counts on them).
Training the model:
The word2vec model is trained using the gensim library and is saved locally to use whenever required.
w2v_model = Word2Vec(min_count=20,
window=3,
size=300,
sample=6e-5,
alpha=0.03,
min_alpha=0.0007,
negative=20
)
#Building Vocabulary
w2v_model.build_vocab(sentences)
#Saving the built vocabulary locally
w2v_model.wv.vocab.keys().to_csv(‘vocabulary.csv’)
#Training the model
w2v_model.train(sentences, total_examples = w2v_model.corpus_count, epochs = 30, report_delay = 1)
#saving the model
path = "/content/drive/MyDrive"
model = joblib.load(path)
print(w2v_model.wv.similarity('neural_network', 'machine_learning'))
Output:
0.65735245
Reading the resume and performing tokenization
Reading a resume
A resume can be of different forms like pdf, docx, image, etc. Different tools are used for extracting information from different forms of resumes.
PDF – using pdfplumber
Image – using OCR
Data preparation
After extracting the data, the next step is preprocessing, creating n-grams, and tokenization.
Finding the similarities between JD skills and resume tokens
Here comes the final step. After performing the first two steps, we obtain the following things
- Word2vec model/Word Embeddings
- Phrases object
- Data vocabulary
- Resume tokens
JD’s skills are entered manually. Now, we need to find the similarity between JD skills and resume tokens; if a JD skill has at least one relevant skill in the resume tokens, then it will be considered as “present” in the resume else, “absent” in the resume.
How to check relevant skills? The answer is cosine similarity. The skill is considered relevant if the cosine similarity between the two embeddings is less than a certain threshold.
We create two arrays of JD skill embeddings and resume token embeddings for finding the numerator of cosine similarity of all the embeddings simultaneously, i.e., A.B
Drawbacks of Word2Vec for Skill Matching
What if a JD skill is not present in the vocabulary which was used for building the model? The model will not have its embedding; such words are called out of vocabulary words. This is a major drawback of word2vec. Character-level embeddings could be done to solve this issue. FastText works at character-level embeddings.
The major difference between Word2Vec and FastText is that Word2Vec feeds individual words into Neural Network to find the embeddings, whereas, FastText breaks words into several n-grams (sub-words). The word embedding vector for a word will be the sum of all the n-grams.
Script
Installing Necessary Packages
!pip install pdfplumber !pip install pytesseract !sudo apt install tesseract-ocr !pip install pdf2image !sudo apt-get update !sudo apt-get install python-poppler !pip install PyMuPDF !pip install Aspose.Email-for-Python-via-NET !pip install aspose-words
Importing Necessary Libraries
import pandas as pd import os import warnings warnings.filterwarnings(action = 'ignore') import gensim from gensim.models import Word2Vec import string import numpy as np from itertools import groupby, count import re import subprocess import os.path import sys import logging import joblib from gensim.models.phrases import Phrases, Phraser import pytesseract import cv2 from pdf2image import convert_from_path from PIL import Image Image.MAX_IMAGE_PIXELS = 1000000000 import aspose.words as aw import fitz logger_watchtower = logging.getLogger(__name__) from pandas.core.common import SettingWithCopyWarning warnings.simplefilter(action="ignore", category=SettingWithCopyWarning)
Function for reading resume
def _skills_in_box(image_gray,threshold=60):
'''
Function for identifying boxes and identifying skills in it: Given an imge path,
returns string with text in it.
Parameters:
img_path: Path of the image
thresh : Threshold of the box to convert it to 0
'''
img = image_gray.copy()
thresh_inv = cv2.threshold(img, 0, 255, cv2.THRESH_BINARY_INV+cv2.THRESH_OTSU)[1]
# Blur the image
blur = cv2.GaussianBlur(thresh_inv,(1,1),0)
thresh = cv2.threshold(blur, 0, 255, cv2.THRESH_BINARY+cv2.THRESH_OTSU)[1]
# find contours
contours = cv2.findContours(thresh, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)[0]
mask = np.ones(img.shape[:2], dtype="uint8") * 255
available = 0
for c in contours:
# get the bounding rect
x, y, w, h = cv2.boundingRect(c)
if w*h>1000:
cv2.rectangle(mask, (x+5, y+5), (x+w-5, y+h-5), (0, 0, 255), -1)
available = 1
res = ''
if available == 1:
res_final = cv2.bitwise_and(img, img, mask=cv2.bitwise_not(mask))
res_final[res_final<=threshold]=0 kernel = np.array([[0, -1, 0], [-1, 5,-1], [0, -1, 0]]) res_fin = cv2.filter2D(src=res_final, ddepth=-1, kernel=kernel) vt = pytesseract.image_to_data(255-res_final,output_type='data.frame') vt = vt[vt.conf != -1] res = '' for i in vt[vt['conf']>=43]['text']:
res = res + str(i) + ' '
print(res)
return res
def _image_to_string(img):
'''
Function for converting images to grayscale and converting to text: Given an image path,
returns text in it.
Parameters:
img_path: Path of the image
'''
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
res = ''
string1 = pytesseract.image_to_data(img,output_type='data.frame')
string1 = string1[string1['conf'] != -1]
for i in string1[string1['conf']>=43]['text']:
res = res + str(i) + ' '
string3 = _skills_in_box(img)
return res+string3
def _pdf_to_png(pdf_path):
'''
Function for converting pdf to image and saves it in a folder and
convert the image into string
Parameter:
pdf_path: Path of the pdf
'''
string = ''
images = convert_from_path(pdf_path)
for j in tqdm(range(len(images))):
# Save pages as images in the pdf
image = np.array(images[j])
string += _image_to_string(image)
string += '\n'
return string
def ocr(paths):
'''
Function for checking the pdf is image or not. If the file is in .doc it converts it into .pdf
if the pdf is in image format the function converts .pdf to .png
Parameter:
paths: list containg paths of all pdf files
'''
text = ""
res = ""
try:
doc = fitz.open(paths)
for page in doc:
text += page.get_text()
if len(text) <=10 :
res = _pdf_to_png(paths)
else:
res = text
except:
doc = aw.Document(paths)
doc.save("Document.pdf")
doc = fitz.open("Document.pdf")
for page in doc:
text += page.get_text()
if len(text) <=10 :
res = _pdf_to_png("Document.pdf")
else:
res = text
os.remove("Document.pdf")
return res
Function for finding Cosine Similarity
def to_la(L): k=list(L) l=np.array(k) return l.reshape(-1, 1) def cos(A, B): dot_prod=np.matmul(A,B.T) norm_a=np.reciprocal(np.sum(np.abs(A)**2,axis=-1)**(1./2)) norm_b=np.reciprocal(np.sum(np.abs(B)**2,axis=-1)**(1./2)) norm_a=to_la(norm_a) norm_b=to_la(norm_b) k=np.matmul(norm_a,norm_b.T) return list(np.multiply(dot_prod,k))
Function for finding the similarities and returning the final matched skills
def check(path,skills,l2,w2v_model1,phrases,pattern):
text = ocr(path)
text = re.sub(r'[^\x00-\x7f]',r' ',text)
text = text.lower()
text = re.sub("\\\|,|/|:|\)|\("," ",text)
t2 = text.split()
l_2=l2.copy()
match=list(set(re.findall(pattern,text)))
sentences=phrases[t2]
resume_skills_dict={}
res_jdskill_intersect=list(set(sentences).intersection(set(l_2)))
if(len(match)!=0):
for k in match:
k=k.replace(' ','_')
resume_skills_dict[k]=1
try:
l_2.remove(k)
except:
continue
l6=list(set(l_2).intersection(skills['0']))
l6_minus_skills=list(set(l_2).difference(skills['0']))
for i in l6_minus_skills:
resume_skills_dict[i]=0
if(len(l6)==0):
return resume_skills_dict
l4=list(set(sentences).intersection(skills['0']))
arr1=np.array([w2v_model1[i] for i in l6])
arr2=np.array([w2v_model1[i] for i in l4])
similarity_values=cos(arr1,arr2)
count=0
for i in similarity_values:
k=list(filter(lambda x: x<0.38, list(i))) if(len(k)==len(i)): resume_skills_dict[l6[count]]=0 else: resume_skills=[s for s in range(len(i)) if(i[s])>0.38]
resume_skills_dict[l6[count]]=1
count+=1
return resume_skills_dict
Functions required for performing JD skills preprocessing
def Convert(string):
li = list(string.split())
return list(set(li))
def preprocess(string):
string = string.replace(",",' ')
string= string.replace("'",' ')
string = Convert(string)
return string
Main Function
if __name__ == "__main__":
#Arg 1 = vocabulary, Arg 2 = model, Arg 3 = phrases object, Arg 4 = JD's Mandatory Skills, Arg 5 = Resume Path
argv = sys.argv[1:]
w2v_model1 = joblib.load(argv[0])
skills=pd.read_csv(argv[1])
mapper = {}
underscore=[]
jd_skills=argv[3]
jd_skills=" ".join(jd_skills.strip().split())
jd_skills=jd_skills.replace(', ',',')
pattern=jd_skills.replace(',','|').lower()
for i in jd_skills.split(','):
if '_' in i:
underscore.append(i)
mapper[i.lower().replace('_',' ')] = i
jd_skills=jd_skills.replace(' ','_')
jd_skills=jd_skills.replace(',',', ')
for i in jd_skills.split(', '):
if i not in underscore:
if '_' in i:
mapper[i.lower().replace('_',' ')] = i.replace('_',' ')
elif '-' in i:
mapper[i.lower().replace('-',' ')] = i
else:
mapper[i.lower()] = i
jd_skills=jd_skills.replace('-','_')
phrases=Phrases.load(argv[2])
lines = [preprocess(jd_skills.lower().rstrip())]
phrases=Phrases.load(argv[2])
final_jd_skills=list(set(lines[0]).intersection(skills['0']))
path = argv[4]
res=check(path,skills,lines[0],w2v_model1,phrases,pattern)
for dict in res:
res_dict={}
for i in dict.keys():
j=i.replace('_',' ')
res_dict[mapper[j]] = dict[i]
print('skills_matched :',res_dict)
Command Line Argument
!python3 demo1.py '/content/drive/MyDrive/Skill_Matching_Files/Model(cbow).joblib' '/content/drive/MyDrive/Skill_Matching_Files/vocab_split.csv' '/content/drive/MyDrive/Skill_Matching_Files/phrases_split.pkl' 'julia, kaggle, ml, mysql, oracle, python, pytorch, r, scikit learn, snowflake, sql, tensorflow' '/content/drive/MyDrive/Skill_Matching_Files/TESTING RESUME/Copy of 0_A.a.aa.pdf'
Output
skills_matched : {'python': 1, 'r': 1, 'oracle': 0, 'snowflake': 1, 'pytorch': 1, 'tensorflow': 1, 'ml': 1, 'sql': 1, 'kaggle': 1, 'mysql': 1, 'julia': 1, 'scikit learn': 1}
Conclusion
I hope the article provided you the insights into extracting skills from resumes. You learned how the Word2Vec word embedding technique is used to vet the resumes by several companies in the recruitment industry and companies.
Please comment below or connect with me on LinkedIn to drop a query or feedback if you have any doubts.





