In today’s digital age, businesses rely heavily on efficiently organizing and retrieving vast amounts of data. At the heart of this data-driven world lies the database—an indispensable tool for storing, managing, and accessing information. But what exactly is a database? This comprehensive article delves into the intricate world of data bases, exploring their inner workings and unveiling their best features. We will uncover how databases empower businesses to streamline operations, enhance decision-making, and foster seamless collaboration with other entities.
This article was published as a part of the Data Science Blogathon.
Table of contents
What is Database?
A data base is a structured collection of data organized and stored systematically, typically in a digital format. It is a repository for storing and managing large amounts of information, such as text, numbers, images, and multimedia files. They provide a means to store, retrieve, update, and analyze data efficiently. They maintain data integrity, ensure consistency, and facilitate efficient data processing. A data base consists of tables composed of rows (records) and columns (fields) representing different entities and attributes. With the help of a data base management system (DBMS), users can interact with the data, perform queries, and manipulate information for various applications and business needs.
Also Read: Beginners Guide to Database
History of Data Base Management System
| Year | Milestone |
| 1960 | Introduction of the concept of the hierarchical database model |
| 1968 | Publication of the “CODASYL Approach” for database management |
| 1970 | Introduction of the relational database model by Edgar Codd |
| 1970 | IBM develops the first commercially available relational DBMS |
| 1976 | Introduction of the Entity-Relationship (ER) model |
| 1976 | Oracle Corporation is founded and releases its first DBMS |
| 1979 | Introduction of SQL as a standard query language |
| 1985 | IBM introduces the first relational database management system |
| 1986 | Microsoft releases its first version of SQL Server |
| 1989 | Introduction of the object-oriented database model |
| 1990 | Emergence of the multidimensional OLAP databases |
| 2000 | Introduction of NoSQL databases, diverging from the relational model |
| 2010s | Rise of cloud-based databases and database-as-a-service (DBaaS) |
| Present | Continued advancements in distributed databases and Big Data technologies |
Data Base Components
Database components work together to provide a robust and efficient data base system, allowing for effective storage, management, and retrieval of data for various applications and users. Here are some of the most common ones:
Tables
Tables are the fundamental building blocks of a data base. They represent the structured format for organizing and storing data. Tables consist of rows (records) and columns (fields) defining the data structure and attributes of the stored entities.
Schema
The schema defines the logical structure and organization of the data base. It specifies the tables, their relationships, and the constraints that govern the data. The schema acts as a blueprint for data storage and defines the data types, primary keys, foreign keys, and other constraints.
Queries
Queries retrieve, manipulate, and analyze data stored in the data base. They allow users to extract specific information based on criteria, perform calculations, and aggregate data.
Indexes
Indexes are data structures that improve the speed of data retrieval operations. They provide a quick reference to the location of data within a table, allowing for faster search and retrieval based on specific columns or keys.
Database Management System (DBMS)
The DBMS is the software that manages the database. It provides an interface for users to interact with the database, handles data storage, retrieval, and manipulation, enforces security and access controls, and ensures data integrity and consistency.
Data Manipulation Language (DML)
DML is a language that enables users to insert, update, delete, and modify data in the database. Common DML languages include SQL (Structured Query Language).
Data Definition Language (DDL)
DDL is a language used to define the structure and properties of the data base. It includes commands for creating tables, defining relationships, setting constraints, and managing the schema.
Data Backup and Recovery
Data base systems often provide mechanisms for backing up data and restoring it in case of data loss or system failures. Backup strategies include full backups, incremental backups, and point-in-time recovery options.
Security and Access Controls
Data base systems implement security measures to control access to data and ensure data privacy. User authentication, authorization, and encryption techniques are commonly employed to protect the integrity and confidentiality of the data.
Data Integrity and Constraints
Databases enforce data integrity by applying constraints such as primary keys, foreign keys, unique constraints, and check constraints. These constraints ensure the consistency and validity of data stored in the data base.
What is File System for Data Storage?
In File System, data is stored on a computer’s hard disk. The file system is a way of organizing files and directories on a computer. It is responsible for keeping track of where files are on the hard disk and how they are organized.
The file system is divided into the directory structure and the file data. The directory structure is a hierarchy of directories containing information about the files in each. The file data is the actual data that is stored in the files.
Each file in the file system has a unique name and a path that specifies the file’s location in the directory structure. The path of a file is the sequence of directories that leads from the root directory to the file. For example, the path of a file named “myfile.txt” in the “Documents” directory would be “Documents/myfile.txt.” The file system also contains metadata about each file, such as the file’s size, owner, and permissions.
There are many different file systems, but they all essentially perform the same primary function: they allow you to store and organize your files. Some file systems are designed for specific operating systems, while others are cross-platform.
One of the most popular file systems is the FAT32 file system. It was initially developed for MS-DOS but is now also used by Windows and Linux. FAT32 has several advantages, including the fact that it is straightforward to use and very efficient. However, it has some disadvantages as well, such as the fact that it is not very secure and is not very reliable. NTFS is another popular file system. It was developed by Microsoft and is used by Windows. NTFS is a very safe and reliable file system but is also very complex and challenging to use.
Difference Between Data Base & File System
There are many differences between databases and file systems. Still, the most fundamental difference is that databases are designed to store data in a structured way, while file systems are designed to store data in an unstructured way.
Databases are typically organized around data models, which define the structure of the data and the relationships between different pieces of data. This structure makes it easy to query the data and find the information you need.
On the other hand, file systems are designed to store data in a flat, unstructured way. It makes it difficult to query the data and find the needed information. Another difference between databases and file systems is that databases are typically designed to be accessed by multiple users simultaneously. In contrast, file systems are designed to be accessed by a single user simultaneously. Databases usually have locking and concurrency control to prevent data corruption, while file systems typically do not.
Types of Databases
1. Relational Databases
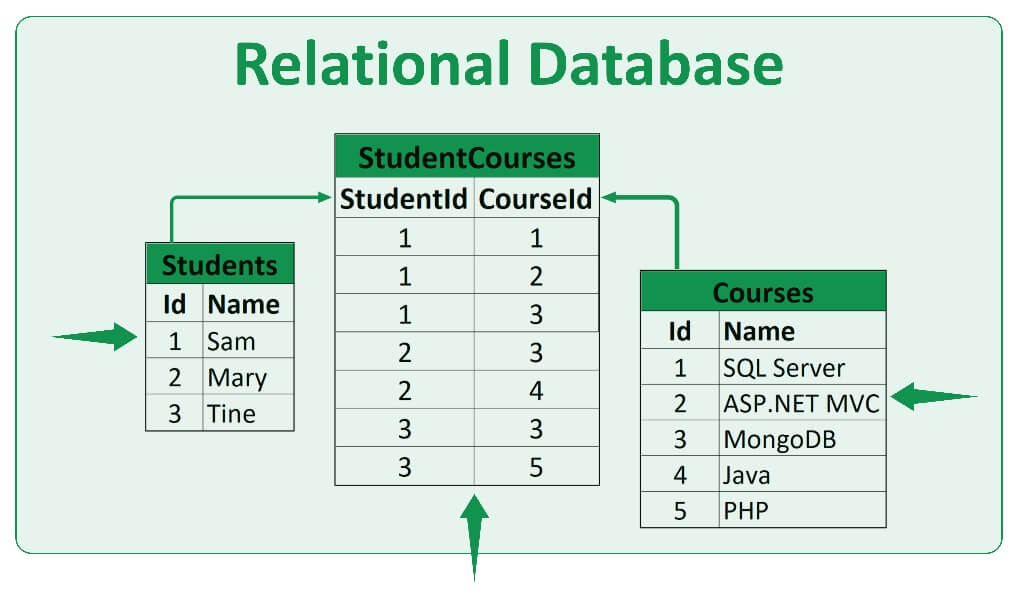
Relational databases store data in tables. Tables are a type of data structure that store data in rows and columns. Rows represent records, and columns represent fields. It often store data that SQL can query. SQL is a language that is used to query data in relational databases. They are a powerful way to store data. They are easy to query, and we can use them to keep a large amount of data.
Where can we use Relational Databases?
- Websites: SQL data bases can be used to store data for a website. This data can include user information, such as name and contact information, and website content, such as articles or blog posts.
- Mobile apps: SQL data bases can power mobile apps. This data can include user information, such as name and contact information, and app content, such as articles or blog posts.
- Businesses: SQL data bases can be used to run a business. This data can include customer information, such as name and contact information, as well as product information, such as inventory levels and pricing.
Limitations
SQL data bases are limited in their ability to scale horizontally. It means they cannot distribute data efficiently across multiple servers. It can be a problem when dealing with large amounts of data or when trying to provide high availability. Another limitation of SQL data bases is that they are not as flexible as NoSQL data bases regarding schema changes. Changing your data model without taking your data base offline can make it challenging.
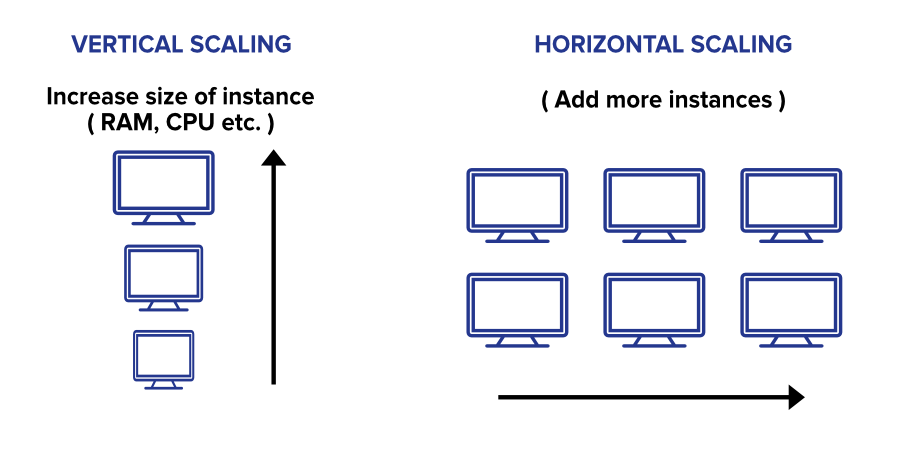
You have heard the term “Scaling database horizontally” in the above paragraph. It means distributing the load to multiple servers. Let’s dive deep into it and learn more about Database Scaling.
Database Scaling
Most people are familiar with the concept of scaling a database vertically. It means adding more resources to an existing data base server to increase performance, which might involve adding more RAM, a faster CPU, or storage.
Horizontal scaling is different. Rather than adding more resources to a single server, horizontal scaling involves adding more servers to a database cluster. We can do it by adding read-only replicas of the data base to different servers. Or, it can include sharding the data base, which means splitting the data into smaller pieces and storing it on other servers.
Which approach is best depends on the situation? Vertical scaling can be easier to implement and can be less expensive. But, it eventually reaches a point where adding more resources to a single server is no longer feasible. At that point, horizontal scaling becomes a necessary solution.
2. NoSQL Databases
NoSQL databases does not use the traditional table-based relational database model. Instead, NoSQL databases are designed to be scalable and flexible, and they use a variety of data models, including key-value stores, document, column-oriented and graph data bases.
Where can we use NoSQL Databases?
- Storing large amounts of data: NoSQL databases are ideal for storing large amounts of data. They are designed to scale horizontally, meaning they can easily add more nodes to the system as needed.
- Handling high traffic: They are also suitable for handling high traffic. It is because they are designed to be highly available, meaning they can keep running even if one or more nodes go down.
- Processing real-time data: They are also suitable for real-time processing data. It is because they are highly scalable, meaning they can easily add more nodes to the system as needed.
Limitations
NoSQL databases have many benefits, but they also have some limitations. One significant rule is that they are not well-suited for transactions that span multiple records. It do not support joins, which are necessary for transactions that update multiple records. Another limitation is that NoSQL data bases can be less consistent than traditional relational databases. It often do not enforce data integrity rules, such as foreign key constraints. Finally, it can be more difficult to query than relational databases. They often do not support standard query languages, such as SQL.
3. Graph Databases
A graph database is a database that represents and stores data using graph topologies with nodes, edges, and characteristics, enabling semantic searches. A crucial system idea is that the graph directly links data elements in the storage. We may immediately link data in the store together thanks to the relationships, and in many situations, we can access it with only one action. Although they have a distinct data model, graph databases are comparable to relational databases.
There are many different types of graph databases, but they all have three standard features:
Nodes – the entities or objects in the graph. In a social network, nodes might represent people.
Edges – the relationships between the nodes. In a social network, edges might represent friendships.
Properties – information attached to the nodes and edges. A social network’s properties might represent names, ages, and locations.
Where can we use Graph Databases?
There are a few different graph databases, and each has its use cases. Here are some examples of where you might use a graph database:
- Social media networks use graph databases to map out relationships between users.
- Fraud detection systems use graph databases to identify behavior patterns that may indicate fraudulent activity.
- Recommendation engines use graph databases to find similar items and recommend them to users.
- Networking and IT systems use graph databases to map out and visualize complex relationships between data.
Limitations
There are a few potential limitations of graph databases to be aware of:
- They can be more complex to query than other databases. It is because you often have to traverse the graph to find the data you’re looking for, which can be time-consuming.
- It can be more challenging to scale than other databases. Because each node in the graph is connected to other nodes, adding more nodes can quickly become complicated.
- They can be less reliable than other types of databases. It is because the data in a graph database is often spread across many different nodes, making it challenging to keep track of everything.
Other Popular Databases
4. Object-Oriented Databases
These databases store objects, attributes, and methods, making them suitable for object-oriented programming. They enable complex data structures and support inheritance and encapsulation. Examples include db4o and Versant.
5. Hierarchical Databases
Hierarchical databases organize data in a tree-like structure, where each record has a parent-child relationship. They are suitable for storing data with one-to-many relationships. IBM’s Information Management System (IMS) is an example of a hierarchical database.
6. Network Databases
Network databases are similar to hierarchical databases but allow for more complex relationships, such as many-to-many. They use a network model to represent data and are useful for handling interconnected data. Integrated Data Store (IDS) is an example of a network database.
7. Columnar Databases
Columnar databases store data in columns rather than rows, allowing for efficient data compression and faster query performance, especially for analytical workloads. Examples include Apache Cassandra and Google Bigtable.
8. Spatial Databases
Spatial databases store and query spatial or geographical data, allowing for efficient storage and retrieval of location-based information. PostGIS and Oracle Spatial are examples of spatial databases.
Applications of Database
Databases find applications in a wide range of industries and domains where efficient data storage, management, and retrieval are crucial. Here are some common applications of databases:
Enterprise Systems
Databases are the backbone of enterprise systems such as customer relationship management (CRM), enterprise resource planning (ERP), and supply chain management (SCM) systems. They store and manage large volumes of data related to customers, sales, inventory, transactions, and more.
E-commerce
Databases power online shopping platforms, managing product catalogs, customer profiles, orders, payments, and inventory. They enable efficient search, personalized recommendations, and smooth transaction processing.
Financial Systems
Banks, financial institutions, and insurance companies rely on databases to store and manage customer accounts, transactions, loan information, claims data, and risk analysis.
Healthcare
Databases are integral to healthcare systems, maintaining patient records, medical histories, diagnostic reports, and treatment information. They support clinical decision-making, research, and data analysis for improved patient care.
Education Management
Educational institutions use databases to manage student information, course catalogs, schedules, grades, and academic records. They facilitate student enrollment, progress tracking, and administrative processes.
Human Resources
Databases store employee data, payroll information, performance records, and benefits details. They streamline HR processes, facilitate talent management, and support workforce analytics.
Social Media
Social media platforms utilize databases to handle vast amounts of user-generated content, profiles, connections, and activity logs. Databases enable real-time updates, content recommendations, and targeted advertising.
Logistics and Transportation
Databases are vital in logistics and transportation systems, managing inventory, tracking shipments, optimizing routes, and scheduling deliveries.
Research and Scientific Applications
Databases support scientific research by storing experimental data, genomic information, research publications, and collaboration records. They facilitate data sharing, analysis, and knowledge discovery.
Government and Public Sector
Databases assist government agencies in managing citizen information, public records, taxation data, land records, and administrative processes.
Examples of Databases
There are many examples of famous databases, but here are a few of the most popular:
| Database | Description |
| Oracle | Widely used relational database management system |
| MySQL | Open-source relational database management system |
| Microsoft SQL Server | Relational database management system by Microsoft |
| MongoDB | NoSQL database for handling unstructured data |
| PostgreSQL | Open-source relational database management system |
| Cassandra | Distributed NoSQL database for scalability |
| Redis | In-memory data structure store and cache |
| SQLite | Lightweight, embedded relational database system |
| Amazon Aurora | Cloud-native relational database service |
| Neo4j | Graph database for managing interconnected data |
1. MySQL
A free and open-source database management system is MySQL. Some of the biggest websites in the world, including Facebook, Twitter, and YouTube, use it as a standard option for online apps.
MySQL is a database management system developed in C and C++ on most operating systems. The most widely used database management system for PHP is MySQL.
A relational database management system is MySQL (RDBMS). Tables are used in relational databases to hold data. In a file system, tables function similarly to folders in that each table contains a collection of data.
We may utilize the robust MySQL database system for a variety of purposes. It has many functions and is simple to use.
2. PostgreSQL
With over 30 years of ongoing development, PostgreSQL is a powerful open-source object-relational database system built with a solid reputation for dependability, feature robustness, and speed.
PostgreSQL is an excellent choice for a database for several reasons:
- It is free and open source.
- It has a strong community of developers and users.
- It is very stable and has a track record of handling high-traffic websites.
- It supports a wide variety of data types, including geographic data.
- It has many advanced features, including full-text search and an advanced system for managing permissions.
3. Oracle Database
Oracle Database is a robust, reliable, and scalable relational database management system. It is the industry’s leading database, with over 400,000 customers worldwide. Oracle Database is used by some of the world’s largest organizations, including many Fortune 500 companies.
Oracle Database is available in various editions, each designed to meet your organization’s specific needs. Oracle Database Standard Edition is the entry-level edition of Oracle Database, providing a cost-effective way to deploy Oracle Database in small to medium-sized environments. Oracle Database Enterprise Edition is the most comprehensive edition of Oracle Database, providing all the features and options available, including high-end features such as Oracle Real Application Clusters and Oracle Active Data Guard.
We recommend starting with Oracle Database Standard Edition if you’re new to Oracle Database. Once you’re familiar with the features and capabilities of Oracle Database, you can upgrade to Oracle Database Enterprise Edition to take advantage of its additional features and options.
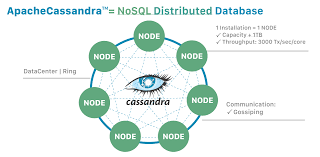
4. Cassandra Database
Cassandra is a NoSQL database that provides high availability and linear scalability. It is a distributed database designed to handle large amounts of data across many commodity servers while providing high availability with no single point of failure. Cassandra is an open-source project that is part of the Apache Foundation.
Cassandra features a ColumnFamily data model that allows for flexible data schema. Cassandra also has a built-in MapReduce framework that makes it easy to perform data analytics. Cassandra is written in Java and has been ported to other languages such as C++, Python, and Go.
Cassandra is used by some of the largest companies in the world, including Netflix, Facebook, and eBay. Cassandra has been proven to scale to handle massive data sets with very high availability.
5. MongoDB
MongoDB is a powerful document-oriented database system. It has an index-based search feature that makes data retrieval quick and easy. MongoDB also offers a scalability feature, allowing it to handle extensive scale data.
6. Microsoft SQL Server
Microsoft created the relational database management system known as Microsoft SQL Server. It is a software product known as a database server. Its main job is to store and retrieve data when other software programs, which may operate on the same computer or a different machine over a network, require it (including the Internet). A part of the Microsoft Windows Server operating system is Microsoft SQL Server.
SQL Server 2016 introduces a new deployment option: Stretch Database. Stretch Database dynamically stretches your on-premises SQL Server databases to Azure. By dynamically extending the warm and cold transactional data in your databases to Azure, Stretch Database enables your applications to continue to access their data, even when it is moved to Azure.
SQL Server 2016 also introduces several other exciting new features:
- Polybase enables you to query data stored in Hadoop clusters using the same Transact-SQL language used to query relational data in SQL Server.
- Always Encrypted protects your most sensitive data, such as credit card and banking information.
Using Databases to Improve Business Performance and Decision-Making
Databases play a crucial role in improving business performance and decision-making by providing a reliable and organized repository of data. Here are some ways in which databases contribute to enhancing business outcomes:
Data Centralization
Data bases allow businesses to centralize their data, consolidating information from various sources into a single, unified location. This facilitates easy access, eliminates data silos, and promotes consistency and integrity.
Efficient Data Management
Data bases provide robust tools and functionalities for data management, including data storage, retrieval, update, and deletion. By organizing data in a structured manner, businesses can efficiently handle large volumes of information and ensure its accuracy and reliability.
Enhanced Data Analysis
Data bases enable businesses to perform advanced data analysis, such as querying, filtering, and aggregating data based on specific criteria. This supports data-driven decision-making, trend identification, and performance monitoring.
Business Intelligence and Reporting
Data bases integrate with business intelligence tools and reporting systems to generate meaningful insights and reports. By leveraging database-driven analytics, businesses can identify patterns, trends, and opportunities, enabling them to make informed strategic decisions.
Real-time Data Processing
Data bases equipped with transaction processing capabilities allow businesses to process and update data in real time. This is particularly valuable in scenarios where immediate data availability is critical, such as online transactions, inventory management, or customer support.
Improved Collaboration
Data bases enable multiple users or departments to access and share data securely. This fosters collaboration and enables cross-functional teams to work together, leveraging a unified source of information.
Streamlined Operations
By maintaining accurate and up-to-date data, data bases streamline business operations. From inventory to customer relationship management, databases ensure that relevant information is readily available, minimizing errors, redundancies, and inefficiencies.
Data Security and Compliance
Data bases provide mechanisms to enforce data security measures, including access controls, encryption, and auditing. They help businesses comply with data protection regulations and safeguard sensitive information.
Scalability and Performance
Data bases handle large volumes of data and support scalability. As businesses grow and data requirements increase, databases can accommodate expanding datasets and deliver optimal performance.
Integration with Applications
Data bases seamlessly integrate with various business applications, allowing for data exchange and synchronization. This integration enhances operational efficiency and ensures data consistency across systems.
Conclusion
In this article, we have talked about the various types of databases, their use, and also their limitations. Other than this, there are more types of databases, like Map-Reduce Databases or XML Databases; we will discuss them in upcoming articles.
We have seen above that no database is perfect. All of them have their benefits and limitations. An ideal database must be able to store data without any loss or corruption. It must be able to retrieve data perfectly and accurately. It must be able to update data ideally without any loss or corruption. Lastly, it must be able to delete data ideally without any loss or corruption.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
I am currently pursuing my Bachelor of Technology (B.Tech.) in Electrical Engineering and Engineering from the Indian Institute of Technology Jodhpur(IITJ). I am very enthusiastic about Machine learning, and Software Development. Feel free to connect with me on Linkedin.





