This article was published as a part of the Data Science Blogathon.
Introduction
Voting ensembles are the ensemble machine learning technique, one of the top-performing models among all machine learning algorithms. As voting ensembles are the most used ensemble techniques, there are lots of interview questions related to this topic that are asked in data science interviews.
This article will explore and answer the top interview questions with their core intuition and working mechanisms with code examples. Reading and practising these questions will help one answer the interview questions related to the voting ensembles very efficiently.
Read about different ensemble methods here.

Let’s start solving them one by one.
Interview Questions on Voting Ensembles
1. What is Voting Ensemble? How does it work?
Voting ensembles are the type of machine learning algorithms that falls under the ensemble techniques. As they are one of the ensemble algorithms, they use multiple models to train on the dataset and for predictions.
They are two categories of voting ensembles.
- Classification
- Regression
Voting Classifiers are the ensembles used in classification tasks in machine learning. In Voting Classifiers, multiple models of the different machine learning algorithms are present, to whom the whole dataset is fed, and every algorithm will predict once trained on the data. Once all the models predict the sample data, the most frequent strategy is used to get the final prediction from the model. Here, the category most predicted by the multiple algorithms will be treated as the final prediction of the model.
For Example, if three models predict YES and two models predict NO, YES would be considered the final prediction of the model.
Voting Regressors are the same as voting classifiers. Still, they are used on regression problems, and the final output from this model is the mean of the prediction of all individual models.
For Example, if the outputs from the three models are 5,10, and 15, then the final result would be the mean of these values, which is 15.
2. How can Voting Ensemble be Implemented?
Several ways are used in which the voting ensemble can be Implemented.
Classification
For Classification Problem, the VotingClasssifier class can be used directly for implementation, and also there is a manual method for implementing the same.
Using VotingClassifier class from sklearn:
#Using VotingClassifier
from sklearn.ensemble import VotingClassifier
model1 = LogisticRegression(random_state=7)
model2 = tree.DecisionTreeClassifier(random_state=7)
model = VotingClassifier(estimators=[('lr', model1), ('dt', model2)])
model.fit(x_train,y_train)
Regression
In regression, there are two methods to implement the voting ensemble.
- Using VotingRegressor Class
- Manual Implementation
1. Using VotingRegressor Class:
import numpy as np
from sklearn.linear_model import LinearRegression
from sklearn.ensemble import RandomForestRegressor
from sklearn.ensemble import VotingRegressor
from sklearn.neighbors import KNeighborsRegressor
r1 = LinearRegression()
r2 = RandomForestRegressor(n_estimators=10, random_state=1)
r3 = KNeighborsRegressor()
rer = VotingRegressor([('lr', r1), ('rf', r2), ('r3', r3)])
2. Manual Implementation:
Normal Averaging:
model1 = tree.DecisionTreeClassifier() model2 = KNeighborsClassifier() model3= LogisticRegression() model1.fit(x_train,y_train) model2.fit(x_train,y_train) model3.fit(x_train,y_train) pred1=model1.predict_proba(x_test) pred2=model2.predict_proba(x_test) pred3=model3.predict_proba(x_test) finalpred=(pred1+pred2+pred3)/3
Weighted Averaging:
model1 = tree.DecisionTreeClassifier() model2 = KNeighborsClassifier() model3= LogisticRegression() model1.fit(x_train,y_train) model2.fit(x_train,y_train) model3.fit(x_train,y_train) pred1=model1.predict_proba(x_test) pred2=model2.predict_proba(x_test) pred3=model3.predict_proba(x_test) finalpred=(pred1*0.3+pred2*0.3+pred3*0.4)
3. What is the reason behind the better performance of the voting ensembles?
There are multiple reasons behind the performance of the voting ensembles. The primary reasons behind the excellent performance of the voting ensembles are listed below.1. If there are weak machine learning algorithms as base models, still the voting ensembles work well as there will be a power of multiple algorithms combined.
2. In Voting Classifier there are different machine learning algorithms are used. Some machine learning algorithms perform so well on some types of data. (e.g. some of them are robust to outliers etc.). So as there are multiple models involved in this process, knowledge of every algorithm will be used to solve the different problems and patterns of the dataset, and every algorithm will try to solve the design of the data. So multiple issues and practices of the data can be learned using different algorithms in voting ensembles.
3. There is also the option of manually giving weightage to the particular models. Let’s suppose we have a dataset having an outlier, so in this case, we can manually increase the weightage of the algorithm, which performs better on outliers, so ultimately, this helps the voting ensemble perform better.
4. What are hard voting and soft voting?
Hard Voting in voting ensembles, the prediction predicted from most algorithms, served as the final output. For Example, if the maximum of the base models indicates YES as output, then the final product would also be YES.
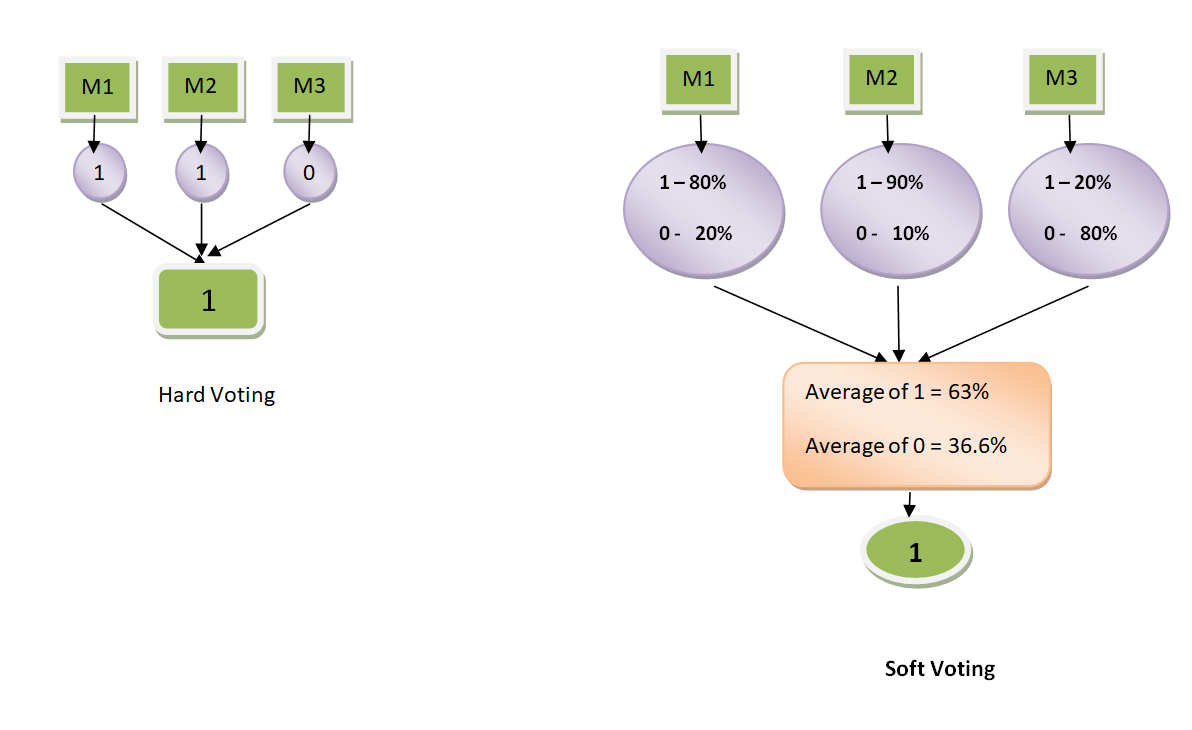
Soft voting is the process in which the probability of every prediction is considered, and the class with the highest total chance from all base models is regarded as the final output from the model. For Example, If the possibility of the category YES as a prediction for every base model is higher than category NO, then YES would be the final prediction from the model.
5. How are voting ensembles different from other ensemble techniques?
The significant difference between voting ensembles and the other boosting algorithms are discussed below:
Voting ensembles are the ensembles technique that trains the multiple machine learning models, and then predictions from all the individual models are combined for output. Unlike voting ensembles, the same algorithm is used as base models in techniques like bagging and boosting. Also, the weights and aggregations steps are performed here, unlike voting ensembles. While stacking and blending are ensemble techniques that contain layers of algorithms, e.g. base models and meta-models. Where base models are trained, the meta-model assigns the weights to the particular base models for better algorithm performance.
Conclusion
This article discusses the top 5 interview questions related to the Voting Ensembles with the core idea and intuition behind them. Reading and practising these questions will help one understand the mechanism behind voting ensembles and help answer effectively in interviews.
Some Key Insights from this article are:
1. Voting Ensembles are ensemble techniques that perform well with weak machine-learning algorithms. Also, in the end, every individual algorithm will have combined power.
2. They are faster than other ensemble techniques as less computational power is involved.
3. The Soft Voting technique can be used when we want to consider the weight or probability of every category in the output column.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
UG (PE) @PDEU | 50+ Published Articles on Data Science | Technical Writer (AI/ML/DL) | Data Science Freelancer | Amazon ML Summer School '22 | Reach Out @[email protected], @portfolio.parthshukla.live





