This article was published as a part of the Data Science Blogathon.

Source: totaljobs.com
Introduction
Until recently, developing new, improved transformers specifically for a single modality was common practice. However, to tackle real-world tasks, there was a pressing need to develop multi-modal transformers models.
Multi-modal transformers models are the type of models that employ the process of learning representations from different modalities using a single model. Input modalities for machine learning include photos, text, audio, etc. Multi-modal learning models the combination of different modalities of data, which often arise in real-world applications.
Given the type of real-world tasks which we often face in companies, startups, business firms, and academia and also the demand, current trend, and potential of Multi-modal transformers models to tackle such tasks, it is imperative to have a thorough understanding of Multi-modal transformers models to secure a position in the industry.
In this article, I have compiled a list of five important questions on different multi-modal transformers models that you could use as a guide to get more familiar with the topic and also formulate an effective answer to succeed in your next interview.
Interview Questions on Multi-modal Transformers
Following are some of the questions with detailed answers.
Question 1: Explain the architecture of the CLIP model.
Answer: CLIP (Contrastive Language Pre-training) model is a neural network that combines text and vision. It learns visual concepts with the help of natural language supervision.
A dataset of 400 million image/caption pairs was created, and contrastive learning was employed to pre-train the CLIP model.
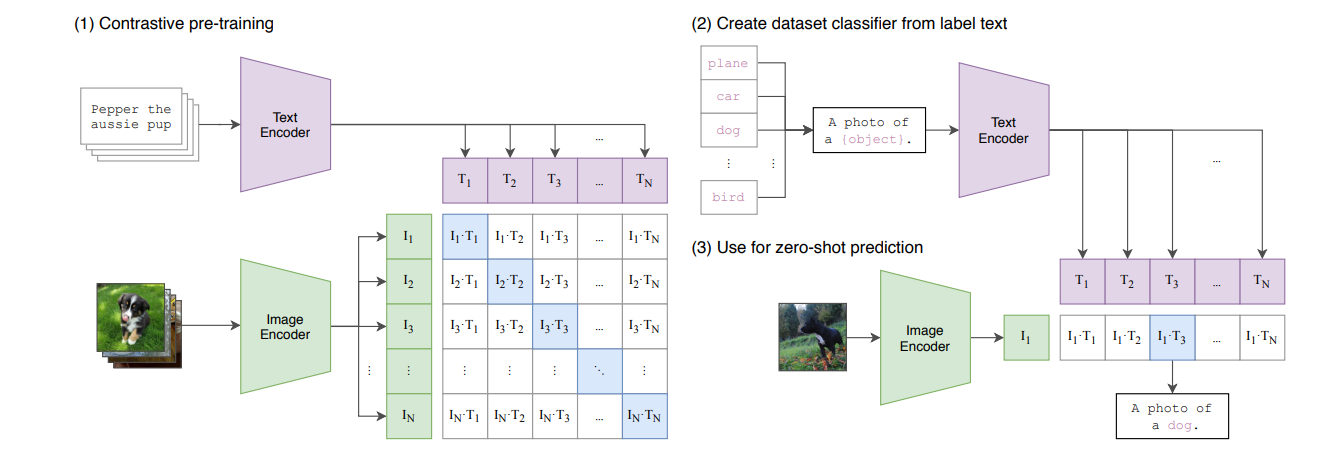
Figure 1: Overview of the CLIP model approach
Source: Arxiv
CLIP = Image Encoder + Text Encoder
Image Encoder and Text Encoder —-> creates embeddings of the images and captions, respectively.
Given a batch of N (image, caption) pairs, CLIP is trained to predict which (image, caption) pairs are a match. To achieve this, CLIP learns a multi-modal embedding space by training an image encoder and text encoder jointly to maximize the cosine similarity of the image and caption/text embeddings of the correct pairs in the batch while simultaneously minimizing the cosine similarity of the embeddings of incorrect pairings (rest of the pairs). Symmetric cross-entropy loss is optimized over these similarity scores.
The possible classes are embedded with the text encoder to use the pre-trained model for classification. Then the embeddings of all the classes are compared to the image embedding we want to classify, and the class with the highest similarity is selected.
Zero-shot image classification performance of the CLIP is remarkable and competitive with fully supervised trained vision models while being more flexible about new classes.
Note: It also learns to perform a wide set of tasks during pre-training, including OCR, geo-localization, action recognition, and many others.
Question 2: Why is CLIP-like pre-training useful? Why not use a regular classification model instead?
Unlike traditional image classification methods, which simultaneously train an image feature extractor and a linear classifier to predict a label, CLIP trains an image encoder and a text encoder to predict the correct pairings of a batch of (image, caption/text) training examples. At test time, the learned text encoder synthesizes a zero-shot linear classifier by embedding the descriptions of the target dataset’s classes.
We often use binary information during standard image classification, i.e., whether a class is present or absent. And as a result, a lot of information is lost. For example, if we train a cat-dog classifier using images crawled from the web, the classifier won’t know whether the animal is an “Aussie” or its name is “Pepper.”
Question 3: Explain the architecture of LyoutLM.
Answer: When it comes to scanned documents like invoices, receipts, or reports, they are info-rich, and hence the visual and layout information can be extracted and encoded into the pre-trained model to recognize text fields of interest.
LayoutLM jointly models how text and layout information interact across scanned document images, which is helpful for many real-world document image understanding tasks, including information extraction from scanned docs.
LayoutLM uses a modified Transformer architecture that takes Image embeddings, LayoutLM embeddings, Text embeddings, and 2-D position embeddings. The 2-D position embedding captures the relationship or relative position among tokens within a document. While image embedding captures some visual features like font directions/styles, types, and colors.
Moreover, with the help of the self-attention mechanism of the Transformer, embedding 2-D position features into the language representation aligns better with the layout information.
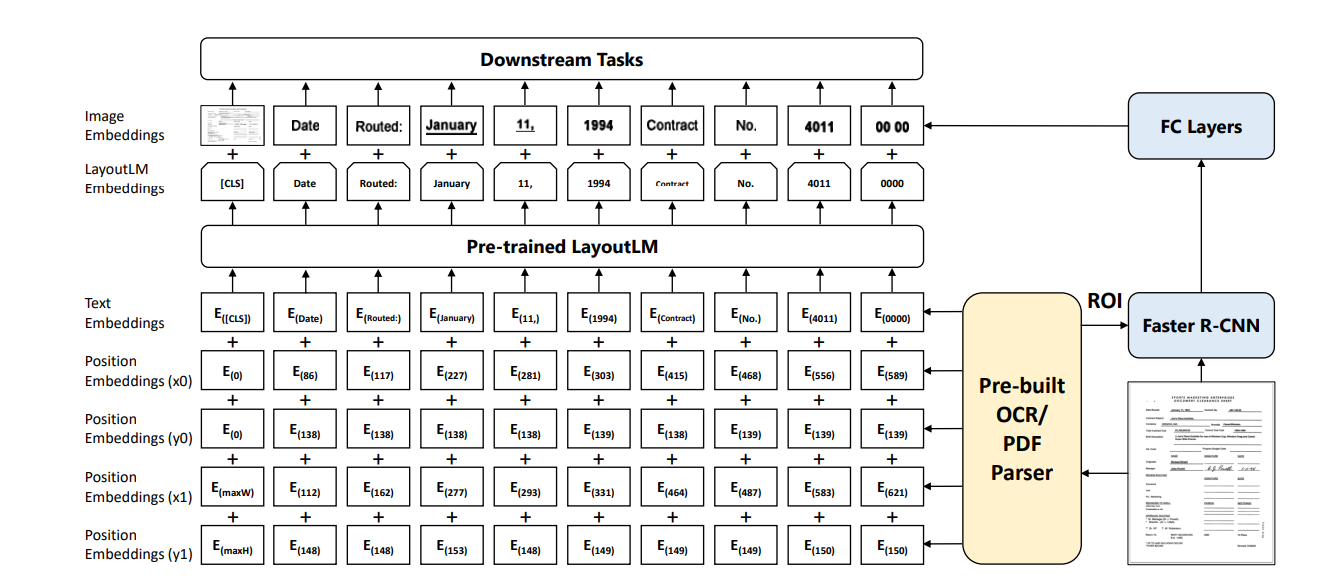
Figure 2: Architecture of LayoutLM
Source: Arxiv
In addition, LayoutLM also adopts a multi-task learning objective, a Masked Visual-Language Model (MVLM) loss, and a Multi-label Document Classification (MDC) loss, which helps in the joint pre-training for text and layout.
Notably, LayoutLM is pre-trained on the IIT-CDIP Test Collection 1.02, which has more than 6M scanned documents with 11M scanned document images, which is the reason why LayoutLM is able to transfer to various downstream tasks.
Question 4: Explain the architecture of Wav2Vec 2.0.
Answer: Wav2Vec 2.0 is a model for self-supervised learning of speech representations. It masks the speech input in the latent space. It solves a contrastive task (where the true latent is to be distinguished from distractors) spanned over a quantization of latent representations that were jointly learned.
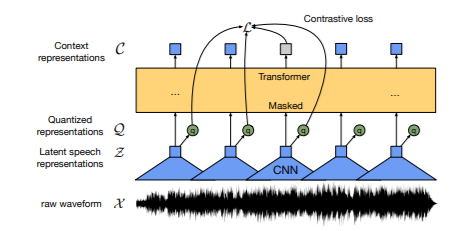
Figure 3: Architecture of Wav2Vec2
Source: Arxiv
In terms of architecture, Wav2Vec 2.0 has a multi-layer convolutional feature encoder (f) containing layer normalization and a GELU activation, which takes raw audio input (X) and generates latent speech representations (z1, z2. . . , zT) for T time-steps, where the total stride of the encoder determines the number of time steps T.
The latent speech representations are subsequently fed to a Transformer (g), which creates context representations (c1, c2. . . , cT) that capture data from the entire sequence.
Moreover, the output of the feature encoder is also discretized (qt) with the help of a quantization module to represent the targets in the self-supervised objective.
By pre-training the model on 53k hours of unlabeled data and fine-tuning on just 10 minutes of labeled data, it also achieves 4.8/8.2 WER. This demonstrates that speech recognition can function even with little labeled data. This can be crucial in developing ASR solutions for native languages and dialects, for which data collection can be difficult.
Question 5: What’s the role of Gumbel-Softmax in Wav2Vec 2.0?
Answer: Discrete sampling is used in many areas of Deep Learning. For example, in language models, we have a sequence of words/character tokens that are sampled, where each discrete token corresponds to a word/character. Hence in this way, we sample from discrete space, which isn’t the same as sampling from continuous. Gumbel-Softmax not only helps sampling from discrete space operate like a continuous, but it keeps the stochastic nature of the node intact while also keeping the backpropagation step viable.
In Wav2Vec 2.0, the feature encoder (z) output is discretized to a finite set of speech representations with the help of product quantization. Choosing quantized representations from various codebooks and concatenating them is what product quantization entails.
Given a set of G codebooks/groups with V entries, one entry from each codebook is chosen, the resulting vectors (e1,…, eG)are concatenated, and a linear transformation (R) is applied to obtain q.
The Gumbel softmax helps choose discrete codebook entries in a fully differentiable way. The output of the feature encoder (z) is mapped to l logits, and the probabilities for selecting the
v-th codebook entries for group g is:
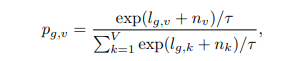
(Source: Arxiv
For forward pass, Codeword i is chosen using: i = argmaxj pg,j.
During backward pass: The true gradient of the Gumbel softmax outputs is used.
Moreover, to facilitate training and codewords utilization, a small randomness effect is added, whose effect is controlled with the help of the temperature argument.
Conclusion
This article presents the five most imperative interview questions on Multi-modal Transformers that could be asked in data science interviews. Using these interview questions, you can work on your understanding of different concepts and formulate effective responses and present them to the interviewer.
To sum it up, the key takeaways from this article are:
1. CLIP (Contrastive Language Pre-training) model combines text and vision. It learns visual concepts with the help of natural language supervision.
2. CLIP consists of an Image Encoder and a Text Encoder. Image Encoder and Text Encoder create embeddings of the images and captions, respectively.
3. In the traditional classification approach, an image feature extractor and a linear classifier are simultaneously trained to predict a label. CLIP trains an image encoder and a text encoder to predict the correct pairings of a batch of (image, caption/text) training examples.
4. LayoutLM jointly models how text and layout information interact across scanned document images, which is helpful for many real-world document image understanding tasks, including information extraction from scanned docs.
5. Wav2Vec 2.0 is a model for self-supervised learning of speech representations. It has a multi-layer convolutional feature encoder (f) containing layer normalization and a GELU activation, which takes raw audio input (X) and generates latent speech representations (z1, z2. . . , zT) for T time-steps.
6. The Gumbel softmax helps choose discrete codebook entries in a fully differentiable way.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
I'm a Researcher who works primarily on various Acoustic DL, NLP, and RL tasks. Here, my writing predominantly revolves around topics related to Acoustic DL, NLP, and RL, as well as new emerging technologies. In addition to all of this, I also contribute to open-source projects @Hugging Face.
For work-related queries please contact: [email protected]





