Consider following fact:
[stextbox id=”section”]Facebook currently has more than 1 Billion active users every month[/stextbox]
Let us spend a few seconds to think what information Facebook typically stores about its users. Some of this is:
- Basic demographics (e.g. date of birth, gender, current location, past location, College)
- Pact activities & updates of users (your photos, comments, likes, applications you have used, games you played, messages, chats etc.)
- Your social network (Your friends, their circles, how you are related etc.)
- Interests of users (books read, movies watched, places etc.)

Using this and a lot of other information (e.g. what did a user click, read and how much time did he spend on it), Facebook then performs following in real time:
- Recommend people you might know & mutual connections with them
- Use your current and all past activities to understand what you are interested in
- Target you with updates, activities and advertisements you might be most interested in
Over and above these, there are near time activities (refreshed in batches and not in real time) like number of people talking about a page, people reached in a week.
Now, imagine the kind of data infrastructure required to run Facebook, the size of its data center, the processing power required to suffice its user requirements.The magnitude could be exciting or scary, depending on how you look at it.
Following infographic from IBM brings out the magnitude of data requirement / processing for some similar Organizations:

This kind of size and scale was unheard by any analyst till a few years back and the data infrastructure some of these Organizations had invested in was not prepared to handle this scale. This is typically referred as Big data problem.
[stextbox id=”section”]So, what is big data?[/stextbox]
Big Data is data that is too large, complex and dynamic for any conventional data tools to capture, store, manage and analyze. Traditional tools were designed with a scale in mind. For example, when an Organization would want to invest in a Business Intelligence solution, the implementation partner would come in, study the business requirements and then would create a solution to cater to these requirements.
If the requirement of this Organization increases over time or if it wants to run more granular analysis, it had to re-invest in data infrastructure. The cost of resources involved in scaling up the resources typically used to increase exponentially. Further, there would be a limitation on the size you could scale up to (e.g. size of machine, CPU, RAM etc.). These traditional systems would not be able to support the scale required by some of the internet companies.
[stextbox id=”section”]How is big data different from traditional data? [/stextbox]
Fortunately or unfortunately, there is no size / parametric cut off to decide whether the data is “big data” or not. Big data is typically characterized basis what is popularly known as 3 Vs:
- Volume – Today, there are organizations producing terabytes of data in a day. With increasing data, you will need to leave some data without analyzing, if you want to use traditional tools. As data size increases further, you will leave more and more data without analysis. This means leaving value on table. You have all the information about what customer is doing and saying, but you are unable to comprehend! – a sure sign that you are dealing with bigger data than what your system supports.
- Variety – While volume is just the start, variety is what makes it really difficult for traditional tools. Traditional tools work best with structured data. They require data is a particular structure and format to make sense out of it. However, the flood of data coming from emails, customer comments, social media forums, customer journey on website and call-centers are unstructured in nature or semi-structured at best.
- Velocity – The pace at which data gets generated is as critical as the other two factors. The speed with which a company can analyze data would eventually become competitive advantage for them. It is their speed of analysis, which allows Google to predict the location of flu patients almost real time. So, if you are unable to analyze data at a speed faster than its inflow, you might need a big data solution.
Individually, each of these Vs can still be worked around with help of traditional solutions. For example, if most of your data is structured, you can still get 80% – 90% of business value through traditional tools. However, if you face a challenge with all three Vs – you know you are dealing with “big data”.

[stextbox id=”section”]When do you need a big data solution?[/stextbox]
While the 3 Vs will tell you whether you are dealing with “big data” or not, you may or may not need a big data solution depending on your need. Following are scenarios where big data solutions are inherently more suitable:
- When you are dealing with huge semi-structured or unstructured data from multiple sources
- You need to analyze all of your data and can not work with sampling them.
- The process is iterative in nature (e.g. Searches on Google, Facebook graph search)
[stextbox id=”section”]How do big data solution work?[/stextbox]
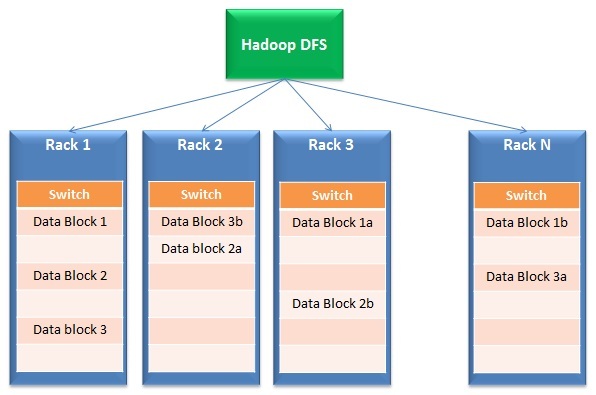
While the limitations of traditional solutions are clear, how do big data solutions solve them? Big data solutions work on a fundamentally different architecture which is built on following characteristics (illustrative below):
- Data Distribution and parallel processing: Big data solutions work on distributed storage and parallel processing. Simply put, files are broken into multiple small blocks and stored in different units (called racks). Then, the processing happens in parallel on these blocks and results are merged back together. The first part of the operation is typically called a Distributed File System (DFS) while the second part is called Mapreduce.
- Tolerance to failure: By nature of their design, big data solution have built in redundancy. For example, Hadoop creates 3 copies of each data block across at least 2 racks. So, even if an entire rack fails or is unavailable, the solution continues to work. Why is this built in? This feature enables big data solutions to scale up even on cheap commodity hardware rather than expensive SAN disks.
- Scalability & Flexibility: This is the genesis of entire big data solution paradigm. You can easily add or remove racks from the cluster without worrying about the size for which this solution was designed for.
- Cost effectiveness: Because of use of commodity hardware, the cost of creating this infrastructure is far lower than buying expensive servers with failure resistant disks (e.g. SAN)
[stextbox id=”section”]Finally, what if all of this was on cloud?[/stextbox]
While developing big data architecture is cost effective, finding right resources is difficult which increases the cost of implementation.
Imagine a situation where all of your IT / infrastructure worries are also taken care by a cloud service provider. You focus on performing analysis and delivering results to business rather than arranging racks and worrying about extent of their usage.
All you have to do is pay as per your usage. Today, there are such end to end solutions available in market, where you can not only store your data on cloud, but also query and analyze it over the cloud. You can query terabytes of data in matter of seconds and leave all the worry about these infrastructure for some one else!
While I have provided an overview of big data solutions, this by no means covers the entire spectrum. The purpose is to start the journey and be ready for the revolution which is on it’s way.
If you like what you just read & want to continue your analytics learning, you can subscribe to our emails or like our facebook page