Text Mining is one of the most complex analysis in the industry of analytics. The reason for this is that, while doing text mining, we deal with unstructured data. We do not have clearly defined observation and variables (rows and columns). Hence, for doing any kind of analytics, you need to first convert this unstructured data into a structured dataset and then proceed with normal modelling framework. The additional step of converting an unstructured data into a structured format is facilitated by a Word dictionary. You need a dictionary to do any kind of information extraction. Dictionary to do a sentiment analysis is easily available on web world. But, for some specific analysis you need to create a dictionary of your own.
This series of article starts from the very basic level to enable anyone, who might not have ever worked on text mining, be able to do one after a read. We will consider a business case to explain this framework and the practical usage. In this article we will start with an overall broad steps, which we need to follow to do an unstructured text mining. In coming articles we will get into more specifics steps like building a dictionary and scoring the entire text.
Business Problem
You are the owner of Metrro cash n carry. Metrro has a tie up with Barcllays bank to launch co-branded cards. Metrro and Barcllay have recently entered into an agreement to share transactions data. Barcllays will share all transaction data done on their credit card on any retail store. Metrro will share all transaction done by any credit card on their stores. You wish to use this data to track where are your high value customers shopping other than Metrro.
To do this you need to fetch out information from the free transactions text available on Barcllays transaction data. For instance, a transaction with free text “Payment made to Messy” should be tagged as transaction made to the retail store “Messy”. Once we have the tags of retail store and the frequency of transactions at these stores for Metrro high value customers, you can analyze the reason of this customer outflow by comparing services between Metrro and the other retail store.
Unstructured data mining framework
The dictionary we need in this business problem looks like a very niche dictionary. We need to identify all retail store names from the transaction free text. Probability of such a dictionary being available and this dictionary being reliable is very low. Hence we need to create such a dictionary and then score our entire data set.
Following is a framework you can follow to create this dictionary :
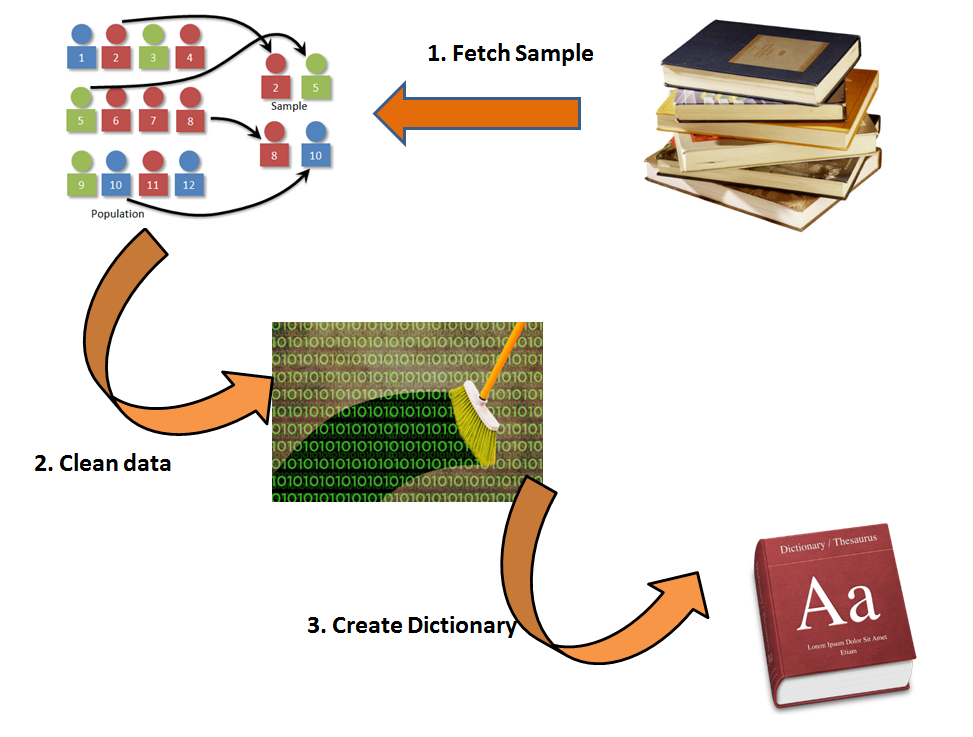
Sampling Image Source: http://faculty.elgin.edu/dkernler/statistics/ch01/1-3.html
Step 1 : As analyzing the entire text manually is an impossible task, we take a random/stratified sample to build a dictionary.
Step 2 : We clean the data to make sure we capture the real essence of the text available. For instance, Maccy’s , maccy and Maccy should be counted as one word. Also, we need to remove stopwords of English dictionary.
Step 3 : Once you have the clean text, extract the most frequently occurring words. Just imagine how non conclusive results you will get if cleaning was not done. Manually identify the frequently occurring words as identifiers. This will form your dictionary.
Once you have the final dictionary, it is now time to score your entire dataset. Following is a framework you can follow to score your dataset :
 Step 4: Now is the time to clean the entire data-set. This is done to make sure that the dictionary we have created in step 3 works on this entire dataset.
Step 4: Now is the time to clean the entire data-set. This is done to make sure that the dictionary we have created in step 3 works on this entire dataset.
Step 5 : Using the dictionary, we can categorize each transaction statement.
Step 6: Once we have tags of category on each transaction statement, we can summarize the entire dataset to fetch business insights and frame business strategy.
End Notes
This article gives you an overview on how to do text mining on real life problem statement. Starting from next article, we will give details on each step mentioned in this framework. I personally prefer using both R and SAS in conjunction to build a unstructured data model.R is very handy to create dictionary on smaller datasets. Whereas, SAS is capable of scoring this dictionary on the entire dataset. Once, we solve this business case completely, we will also look at some text mining visualization techniques.
Have you ever worked on unstructured datasets? If you did, what framework did you use? Did you find the article useful? Did this article solve any of your existing dilemma?
If you like what you just read & want to continue your analytics learning, subscribe to our emails, follow us on twitter or like our facebook page.
Tavish Srivastava, co-founder and Chief Strategy Officer of Analytics Vidhya, is an IIT Madras graduate and a passionate data-science professional with 8+ years of diverse experience in markets including the US, India and Singapore, domains including Digital Acquisitions, Customer Servicing and Customer Management, and industry including Retail Banking, Credit Cards and Insurance. He is fascinated by the idea of artificial intelligence inspired by human intelligence and enjoys every discussion, theory or even movie related to this idea.






Text mining from unstructured data is very well explained...especially with the business problem and solution mentioned above helped me to understand the concept more easily. Thanks Kunal.
Nitin, Stay tuned for the detailed explanation on each step in next few articles. Tavish
Nicely written ,is it possible to create a document term matrix rather against sampling after cleaning of corpus (bag of words) in one go . Macy, ,macci etc similar words can be clubbed by sodex or metaphone Categozie or classify using conditionwl frequency of asociation words (or using mono grams and bigrams conditional frequency) via multinomial naive bayes
Mahendra, We can make a document term matrix but the concern I have is the limitation of hardware if you are using 4-6 GB RAM. Imagine a matrix with millions/billions of rows (or transactions) and thousands of columns (or frequently occurring words) being handled by R. Let me know in case I did not get what you were trying to say. You are bang on with the metaphone and association part. I intend to cover this in next few pieces of the article. Tavish