In one of my previous articles, we discussed about synthetic keys (Synthetic keys in Qlikview – Simplified). We discussed why synthetic keys are generated and came to conclusion that if we have multiple synthetic keys in our data model, it might be a result of bad bad data model and may deliver unexpected results. We also saw a few ways to remove synthetic keys and improve our data model.
This article starts where we finished our last article. We will discuss two more techniques to remove synthetic keys and optimize our data model in our QlikView application. These two techniques are:-
- Concatenation
- Link/ Key Table
Let’s understand these two techniques in detail using examples:
Analyse sales trend over years with YoY transaction datasets
A sales oriented company has year on year transaction datasets (one dataset for each year) with one or two different fields (due to base system changes or defects) but rest of the fields are similar. Company wants to show YoY sales trends using these datasets.
In this scenario, let’s load all YoY datasets in QlikView. As you would expect, QlikView creates synthetic keys to join these tables, as these tables have multiple common fields. You can see the data model with synthetic key below. Now to remove synthetic key, we can’t rename/ drop all these fields because they are significant and related with each other. Here, we need all the fields in a table to show YoY trends, monthly seasonality over the year and many more things. As you know, Qlikview automatically concatenate/ combines tables if they have same granularity and columns. However, in our scenario, some of the columns are different. Here we need to force concatenation using CONCATENATE and combine the datastes in a single table (See Snpashot on the right).
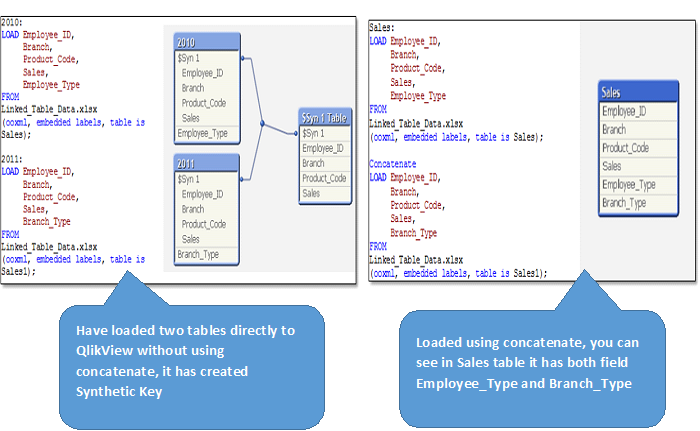
Below, you can also see that in the SALES table, both Employee_Type and Branch_Type are appearing with their available values and total number of records is N1 (number of records in 2010) + N2 (number of records in 2011).
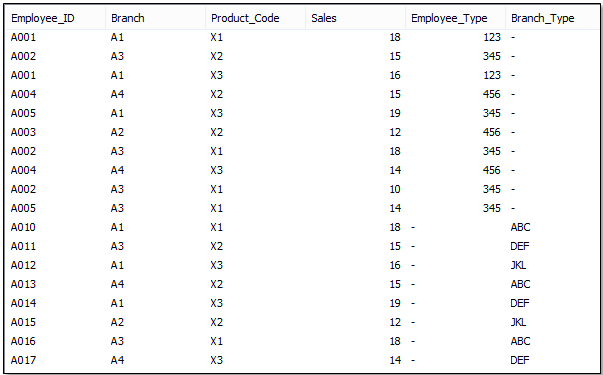
In similar manner, if the granularity and columns in the tables are same, then we can use Concatenate which will merge the tables into one and resulting table will have the sum of rows of the two tables.
Analyze the sales performance of employee against their targets (and analyze performance on several dimensions like product, Year of joining, Region):
To perform this we have five tables, in which two are fact table and others are dimension (Below is table structure).
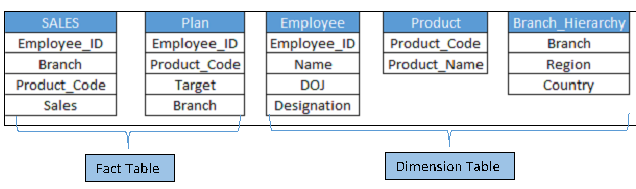
Above you can see that tables, “Sales” and “Plan” have three common fields and Dimension tables are also associated with both the fact tables.
Now, if we load all these tables directly to QlikView, it will result in a data model with synthetic keys (screenshot below).
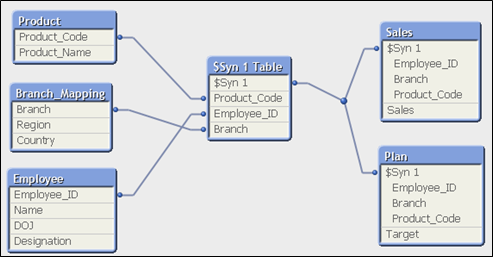
Since the fact tables do not have similar columns, we can not go for concatenation. At the same time, we need them for our analysis as well. Now to remove synthetic key in this data model we should use LINK table. It links two or more fact tables by taking all common fields out of the original tables and places them into a new table (called link table).The new link table contains all possible combinations of values for the set of fields through a unique key and is associated with the original tables.
In simple words, we can say that the link table replaces the synthetic key table and it has all the combinations of the key fields that are common for fact tables. We should also create a new compound key to connect all three tables (Two Fact tables and Link Table) and remove common fields from fact tables.
Rules to define Link Table:-
- Create a key based on common fields of fact tables and break all other association using commenting or renaming.
- Make sure that all of the combinations that exist in both fact tables are available in the created link table else it may cause missing out on some records.
- The link table must have distinct records.
Now let’s look at the methods to develop data model using Link Table:-
Step – 1 Load facts table, form key for all common fields and comment all common fields.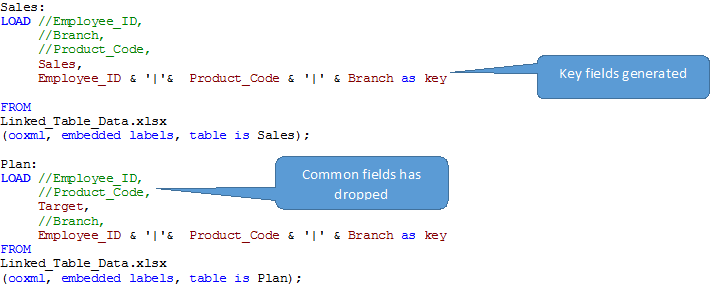
Step – 2 Create the Link Table by loading the distinct values of the fact tables

Step-3 Load other dimension tables.

Step-4 Reload it and we would have following data model without a synthetic key.
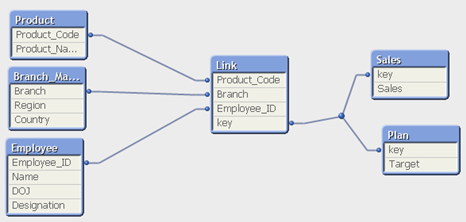
Above, you can see a data model with Link table and it has all common fields of fact tables.
Link Table Vs Concatenate
In the examples above, we looked at both the scenarios, where we should go with CONCATENATION or LINK table. Both methods have their own advantages, Let’s look at some of these:
- If the granularity and fields in the fact tables are same, we should go for Concatenate which will merge the tables into one. When these are different and joined to different dimensions, we will use LINK table.
- With Link Tables you can maintain more understandable data model. On the other hand Concatenate is a simplistic approach with excellent performance to handle large volume of data
- The choice also depends on what kind of analysis we want to perform and which model will suffice our purpose.
End Note:-
As mentioned before, multiple synthetic keys typically reflects bad data model. We had looked at a few methods to remove synthetic keys in past. In this article, we particularly looked at two methods – LINK table and Concatenation. Both the methods have their own advantages and applications. The choice of method should depend on the business requirement and the kind of analysis required from the data.
Have you found this series useful? We have simplified a complex topic – Synthetic keys and have tried to present it in simple and understandable manner. If you need any more help Synthetic Key and Data model, please feel free to ask your questions through comments below..
If you like what you just read & want to continue your analytics learning, subscribe to our emails, follow us on twitter or like our facebook page.
Sunil Ray is Chief Content Officer at Analytics Vidhya, India's largest Analytics community. I am deeply passionate about understanding and explaining concepts from first principles. In my current role, I am responsible for creating top notch content for Analytics Vidhya including its courses, conferences, blogs and Competitions.
I thrive in fast paced environment and love building and scaling products which unleash huge value for customers using data and technology. Over the last 6 years, I have built the content team and created multiple data products at Analytics Vidhya.
Prior to Analytics Vidhya, I have 7+ years of experience working with several insurance companies like Max Life, Max Bupa, Birla Sun Life & Aviva Life Insurance in different data roles.
Industry exposure: Insurance, and EdTech
Major capabilities: Content Development, Product Management, Analytics, Growth Strategy.






Its really awesome. I have a doubt, Here why you are generating Key and Temp_Key fields, why you are dropping again, Shall we try with single column with the name of Key. Can you please explain.... @Sub2a
Hi Sunil Thanks for the info. I do have the similar situation 2 fact tables, opportunity and campaign where there are no common fields across these tables. I have opportunity create date in opportunity fact and campaign start date in campaign fact, where i need to derive common date calender. Could you please suggest me on the same. Thanks Satish
Hi Sunil, In the second approach(Link Table) we have three columns in Common between the two fact tables i.e. Employee_Id, Product_Code, Branch, what if we try the concatenation concept here.