Python is gaining ground very quickly among the data science community. We are increasingly moving to an ecosystem, where data scientists are comfortable with multiple tools and use the right tool depending on the situation and the stack.
Python offers ease of learning, large ecosystem (web development / automation etc.), an awesome community and of course multiple computing libraries. It is not only becoming the preferred tool for newbies wanting to learn data science, but also among the professional data scientists. Python offers the best eco-system, if you are looking to work on / learning deep learning.
With this in mind, it was only a matter of time that we came out with a skill test for Python. So, we conducted our first Python Skilltest on 25th September and guess what the winner came out flying, karim.lulu scoring 44 out of 45 questions!
If you use Python as your preferred tool for data science or are learning it, here is a chance to check your skills (in case you missed it). For those who took the test live, read on the to find the right questions.
We got 1337 registrations for the Python skill test and more than 250 people actually made a submission.
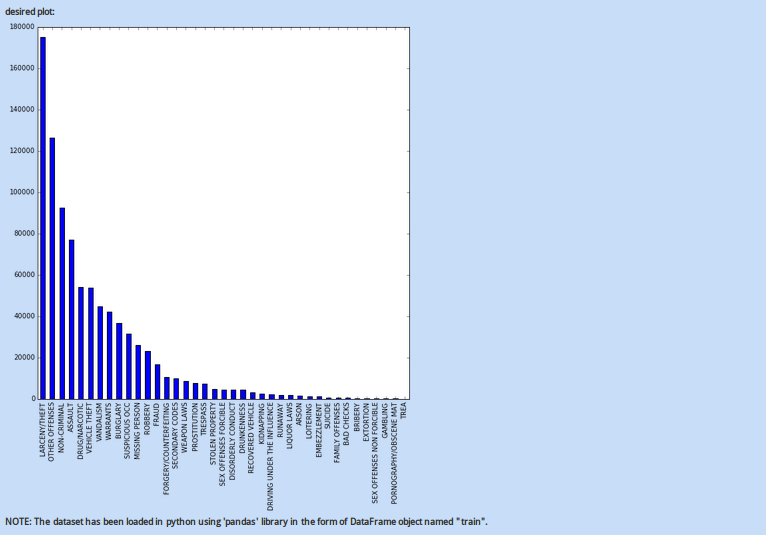
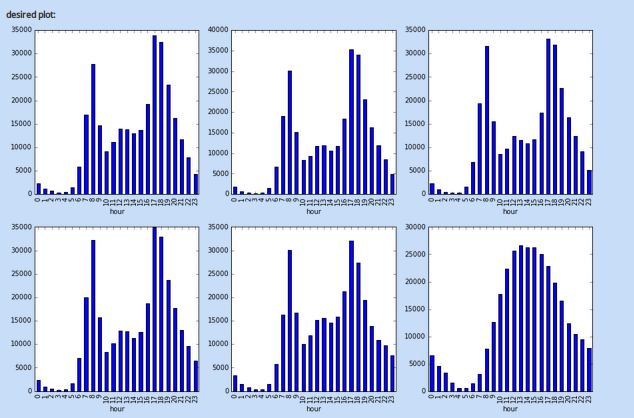
We had 45 questions in the skill test. The winner got 44 answers right! Here is the distribution of the scores:
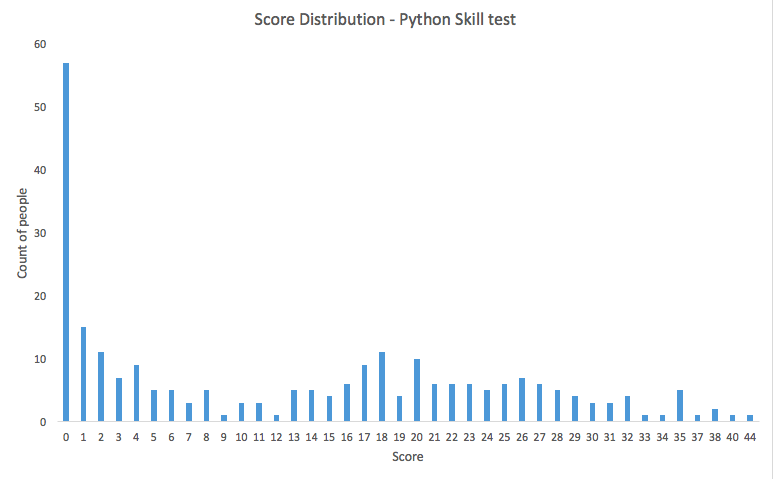
Interesting distribution! Looks like our choice of questions intimidated a lot of people with a lot of them scoring 0. Overall, here is a brief summary of the performance:
- mean = 12.8095
- Median = 13
- Mode = 0
So, here are the questions along with there answers as were used in Python skill test:
Skill test Questions and Answers
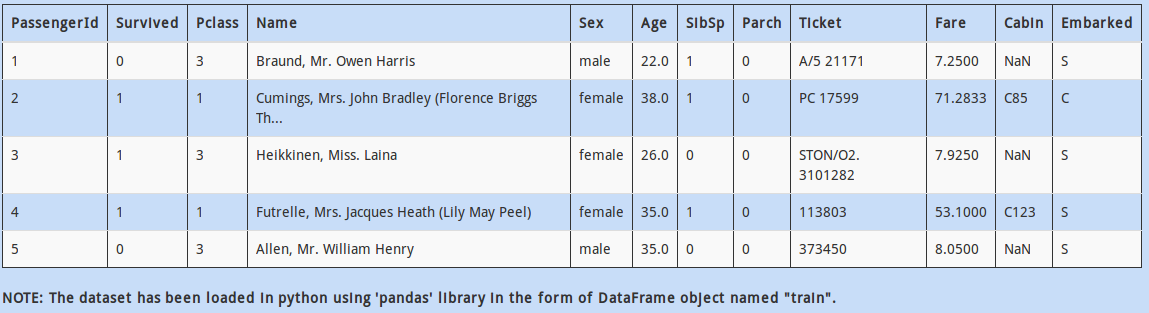
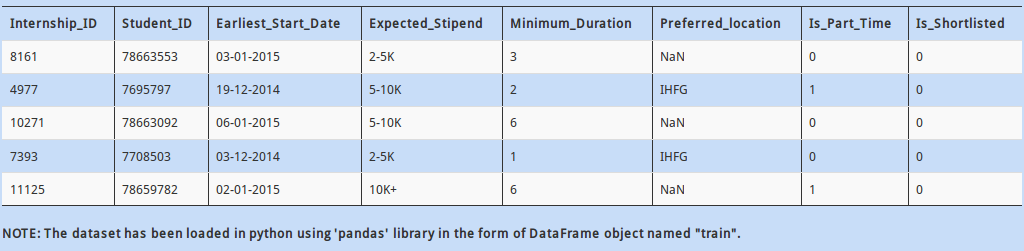
Q :1)
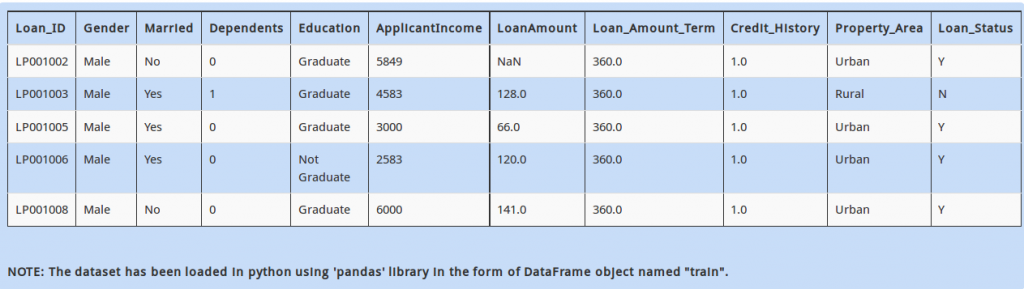
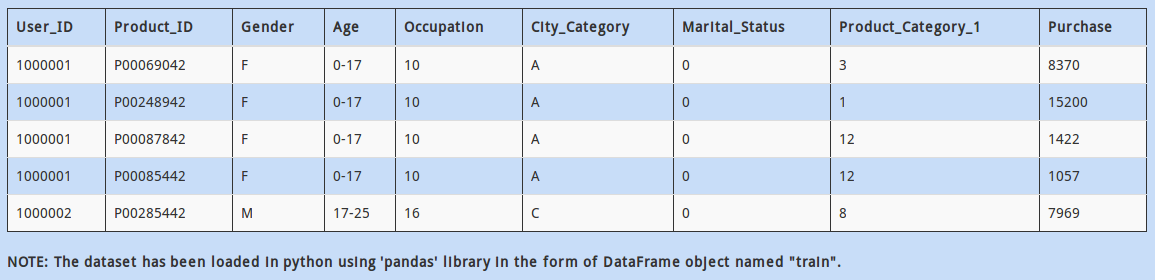
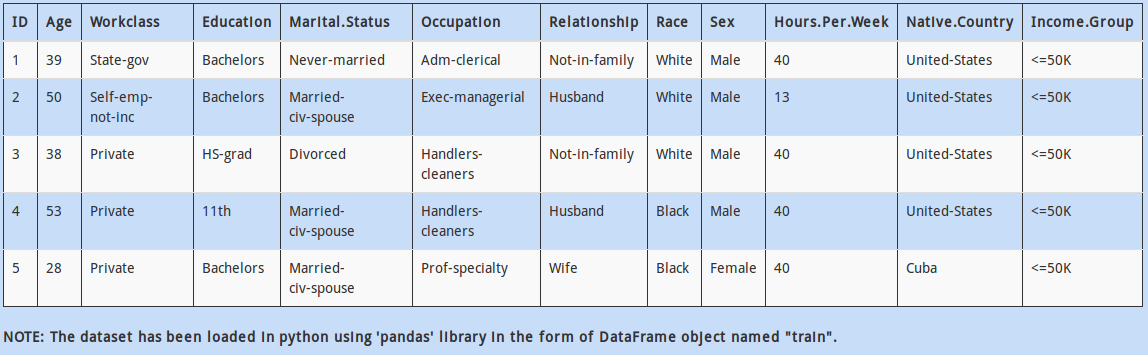
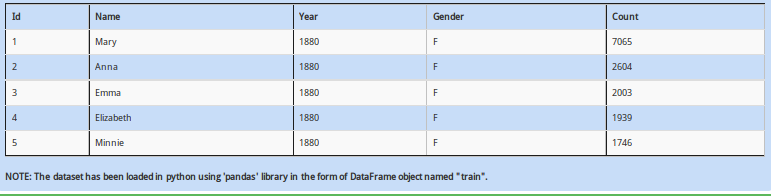
Above dataset has mix of categorical and continuous features. Every data scientist must know that handling categorical values is different from numerical values.
So how would you calculate the number of columns having categorical values?
A - (train.dtype == 'object').sum()
B - (train.dtypes == object).sum()
C - (train.dtypes == object).count()
D – None of these
Solution: B
Categorical variables are denoted with datatype as “object”.
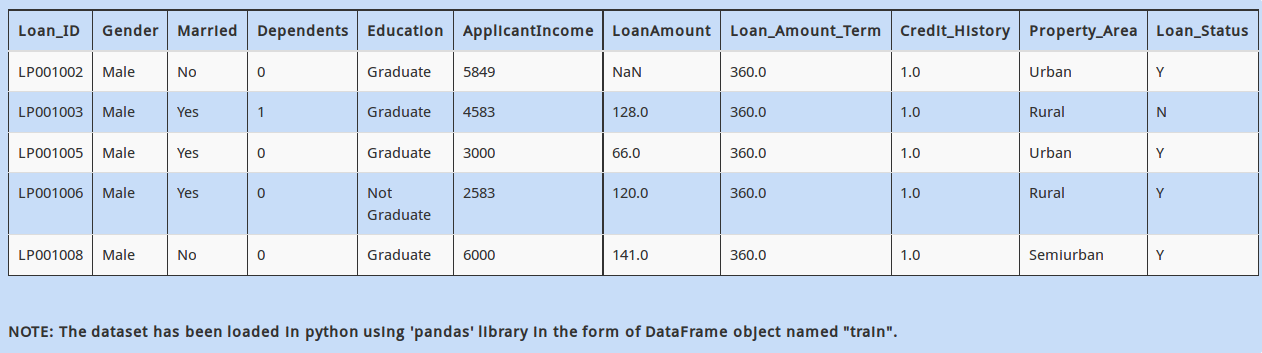
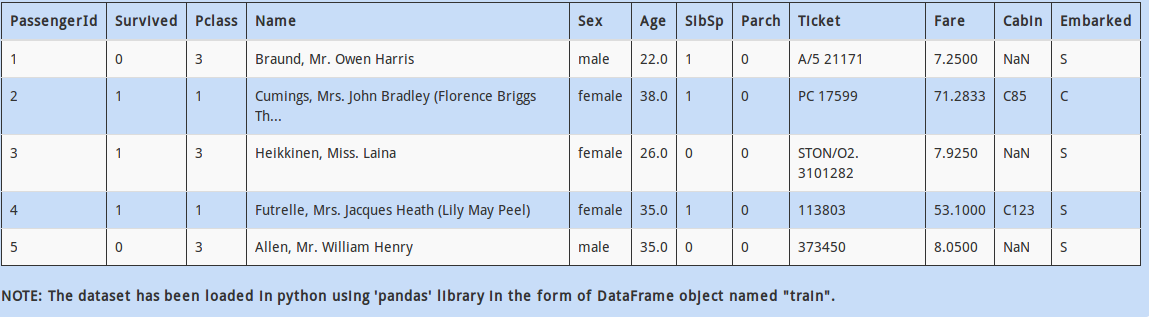
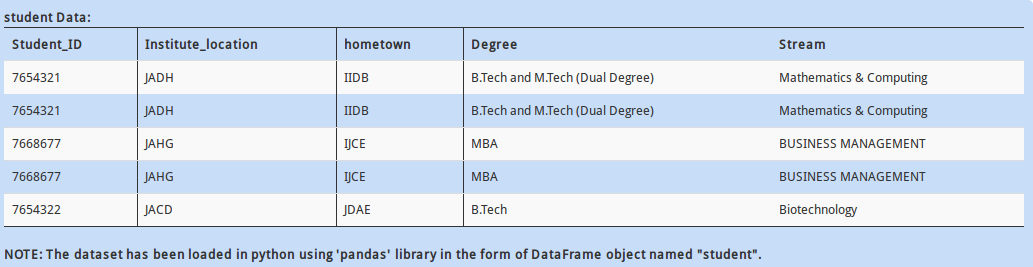
Q 2)
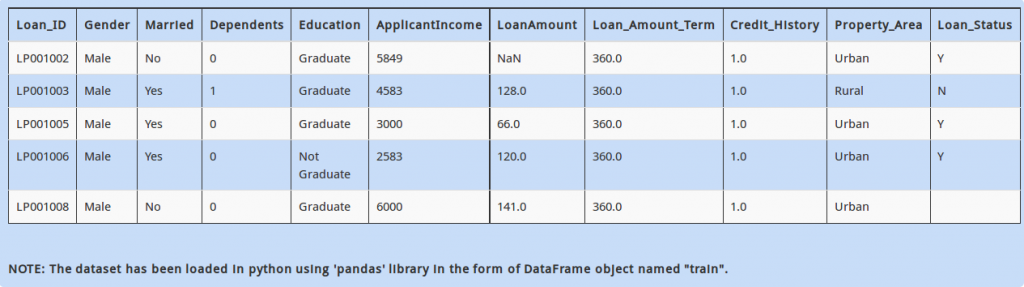
Now that you have found that there are some categorical columns present in the dataset. Each categorical column may contain more than two distinct values. For example, “Married” has two values, “Yes” and “No”.
How will you find all the distinct values present in the column “Education”?
A - train.Education.individuals()
B - train.Education.distinct()
C - train.Education.unique()
D – None of these
Solution: C
To find all the distinct values of a particular column, the function “unique” can be used.
Q 3)
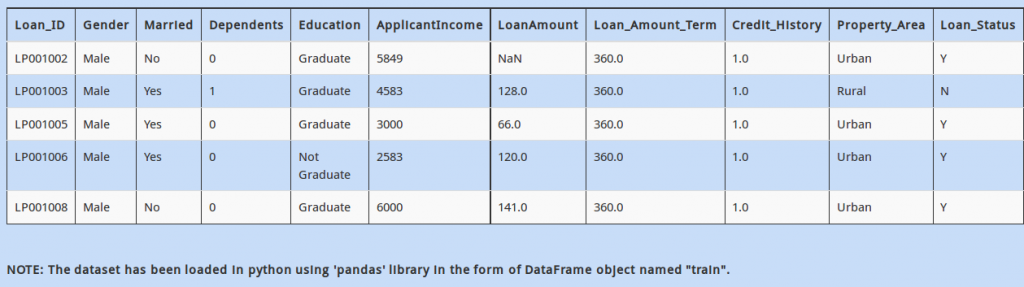
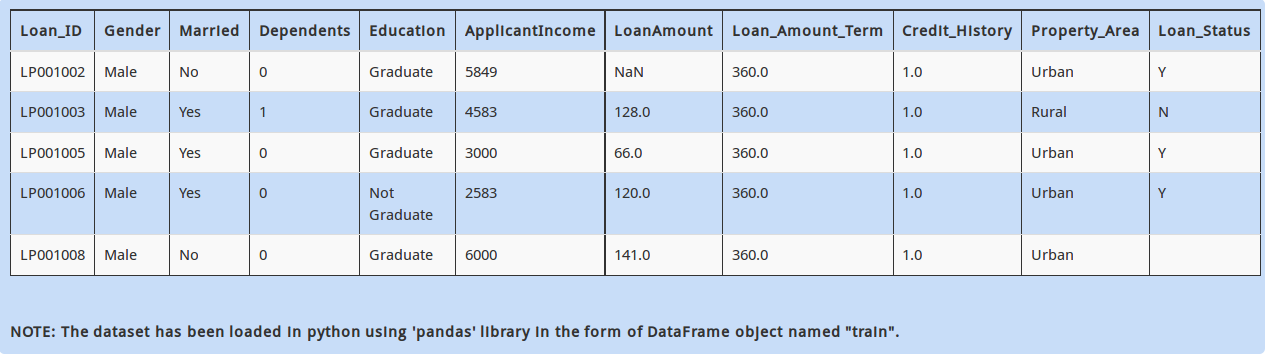
Further, you observe that the column “LoanAmount” has some missing values.
How can you find the number of missing values in the column “LoanAmount”?
A - train.count().maximum() - train.LoanAmount.count()
B - (train.LoanAmount == NaN).sum()
C - (train.isnull().sum()).LoanAmount
D – All of these
Solution: C
The function “isnull()” gives us individual boolean values of the missing values, i.e. is the value is missing or not. In python 2.7, boolean values are represented as 1 and 0 for True and False respectively. So taking their sum gives us the answer.
Q 4)
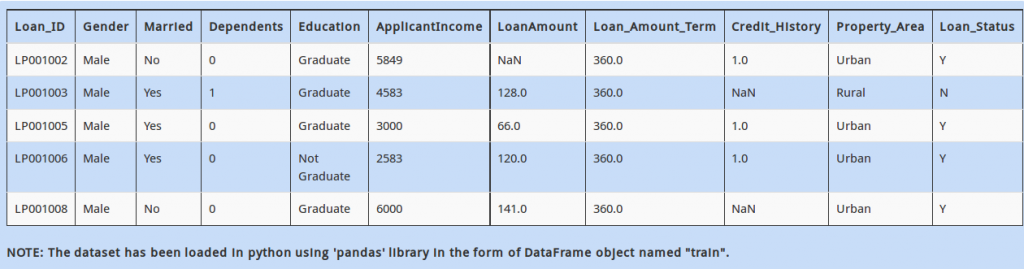
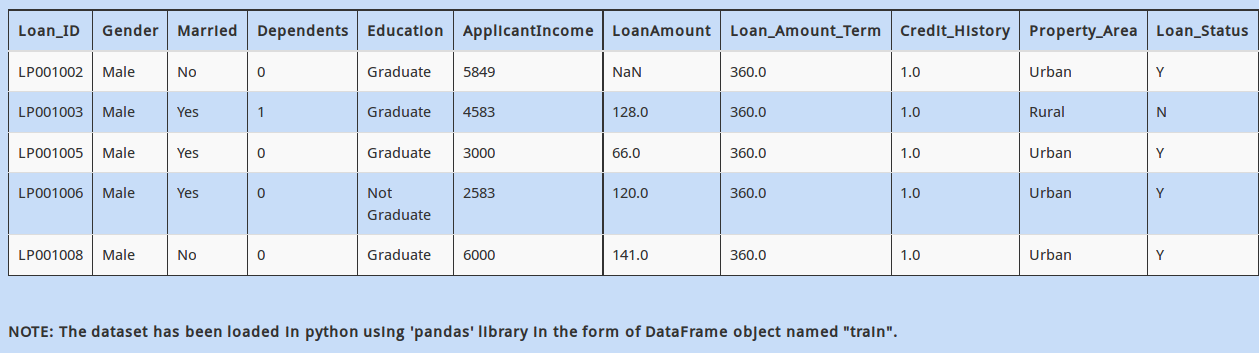
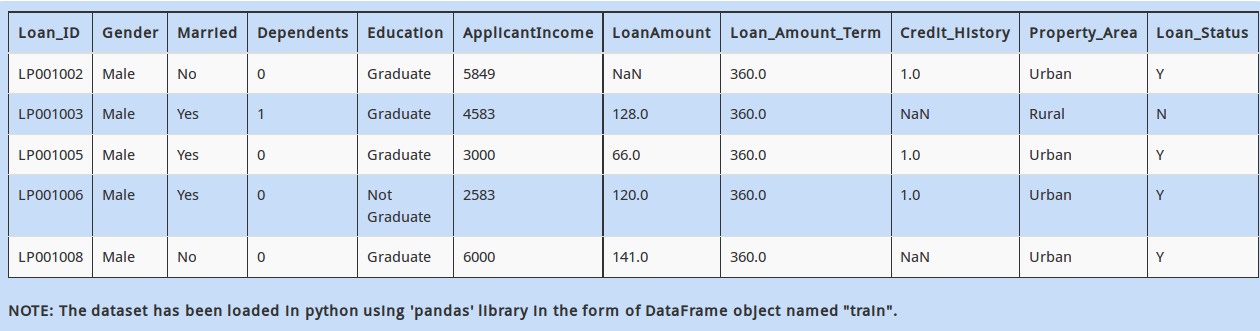
Next, you also see that “Credit_History” has a few missing values. You want to first analyze people who have a “Credit_History”.
You need to create a new DataFrame named “new_dataframe”, which contains rows which have a non-missing value for variable”Credit_History” in our DataFrame “train”. Which of the following commands would do this?
A - new_dataframe = train[~train.Credit_History.isnull()]
B - new_dataframe = train[train.Credit_History.isna()]
C - new_dataframe = train[train.Credit_History.is_na()]
D – None of these
Solution: A
The “~” operator works as a negation operator to boolean values. So in simple terms, option A is correct.
Q 5)
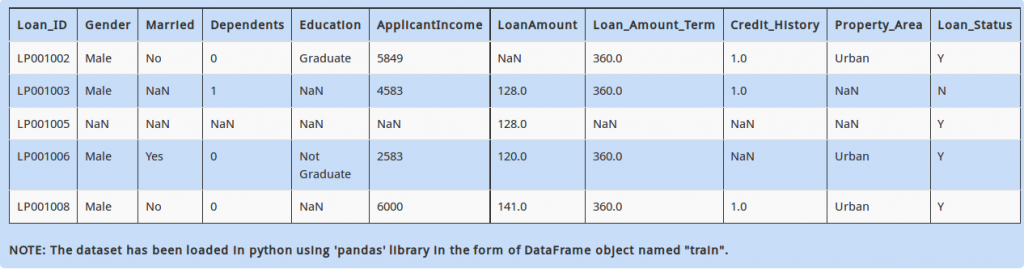
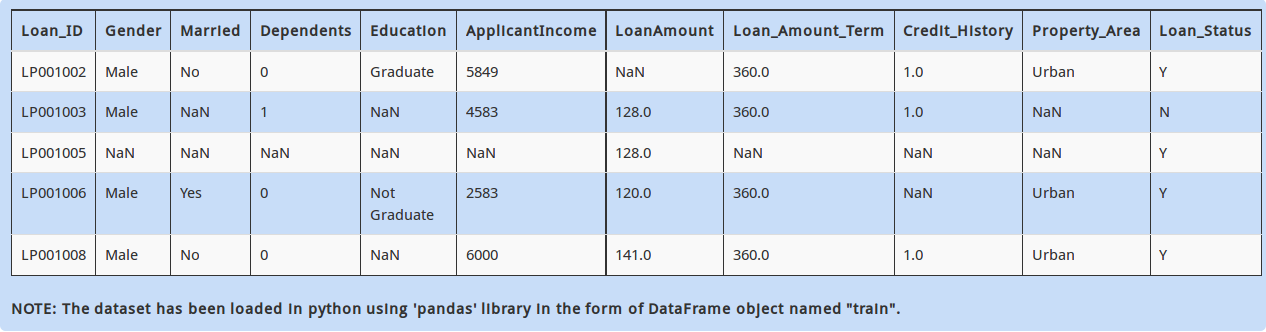
In the dataset above, you can see row with Loan_id = LP001005 has very little information (i.e. most of the variables are missing). It is recommended to filter out these rows as they could create problems / noise in your model.
If a row contains more than 5 missing values, you decide to drop them and store remaining data in DataFrame “temp”. Which of the following commands will achieve that?
A - temp = train.dropna(axis=0, how='any', thresh=5)
B - temp = train.dropna(axis=0, how='all', thresh=5)
C - temp = train.dropna(axis=0, how='any', thresh=train.shape[1] - 5)
D – None of these
Solution: C
In the “thresh” argument of “dropna” function, you have to specify the threshold after which to drop Nan values, i.e. if you want to drop rows with more than 5 missing values, you would have to subtract it with total number of columns.
Q 6)
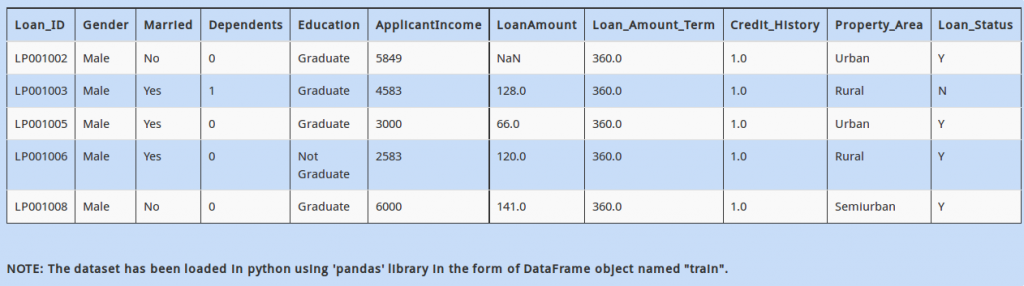
Now, it is time to slice and dice data. The first logical step is to make data ready for your machine learning algorithm. In the dataset, you notice that number of rows having “Property_Area” equal to “Semiurban” is very low. After thinking and talking to your business stakeholders, you decide to combine “Semiurban” and “Urban” in a new category “City” . You also decide to rename “Rural” to “Village”
Which of the following commands will make these changes in the column ‘Property_Area’ ?
A - >>> turn_dict = ['Urban': 'City', 'Semiurban': 'City', 'Rural': 'Village']
>>> train.loc[:, 'Property_Area'] = train.Property_Area.replace(turn_dict)
B - >>> turn_dict = {'Urban': 'City', 'Semiurban': 'City', 'Rural': 'Village'}
>>> train.loc[:, 'Property_Area'] = train.Property_Area.replace(turn_dict)
C - >>> turn_dict = {'Urban, Semiurban': 'City', 'Rural': 'Village'}
>>> train.iloc[:, 'Property_Area'] = train.Property_Area.update(turn_dict)
D – None of these
Solution: B
To solve, first you create a dictionary with the specified conditions, than feed it in the “replace function”
Q 7) 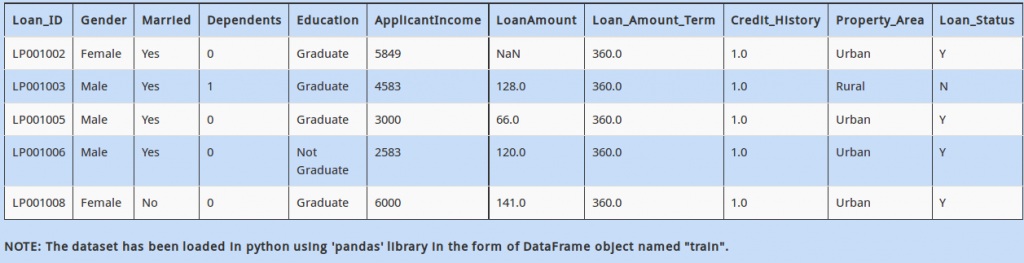
While you were progressing in direction of building your first machine learning model, you notice something interesting. On a quick overview of the first few rows, you see that percentage of people who are “Male” and are married (Married = “Yes”) seems high.
To check this hypothesis, how will you find the percentage of married males in the data?
A - (train.loc[(train.Gender == 'male') && (train.Married == 'yes')].shape[1] / float(train.shape[0]))*100
B - (train.loc[(train.Gender == 'Male') & (train.Married == 'Yes')].shape[1] / float(train.shape[0]))*100
C - (train.loc[(train.Gender == 'male') and (train.Married == 'yes')].shape[0] / float(train.shape[0]))*100
D – None of these
Solution: D
Always remember, to take multiple boolean indexing, specify with “&” operator. Also “shape[0]” returns the total number of columns. And don’t forget the case, as python is case sensitive!
Q 8)
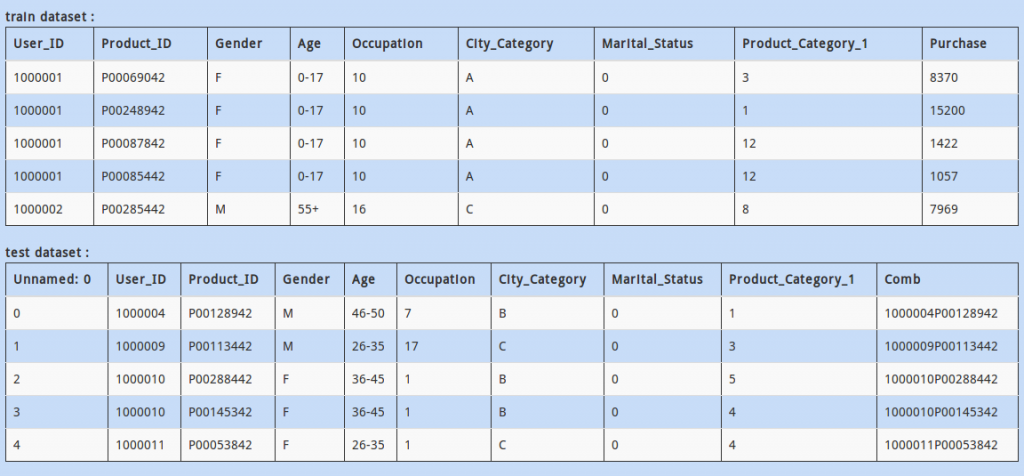
Take a brief look at train and test datasets mentioned above. You might have noticed that the columns in these datasets do not match, i.e. some columns in train are not present in test and vice versa.
How to find which cols are present in test but not in train? Assume data has already been read in DataFrames “train” & “test” respectively.
A - set(test.columns).difference(set(train.columns))
B - set(test.columns.tolist()) - set(train.columns.tolist())
C - set(train.columns.tolist()).difference(set(test.columns.tolist()))
D – Both A and B
Solution: D
This is a classic example of set theory.
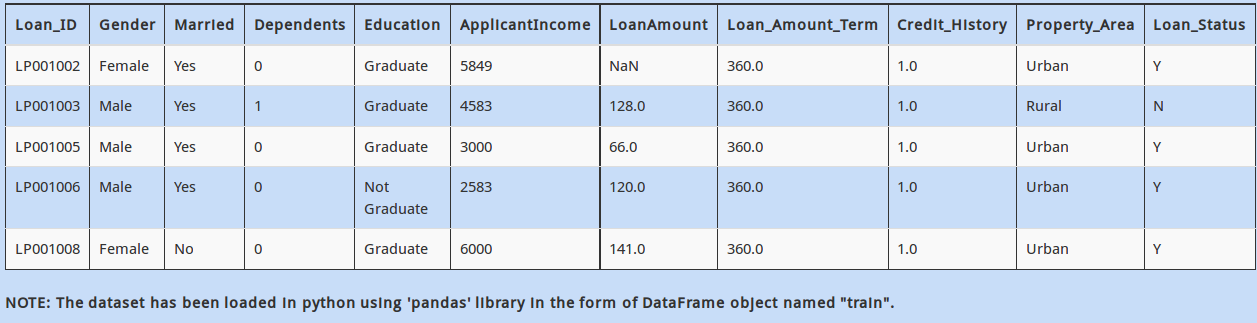
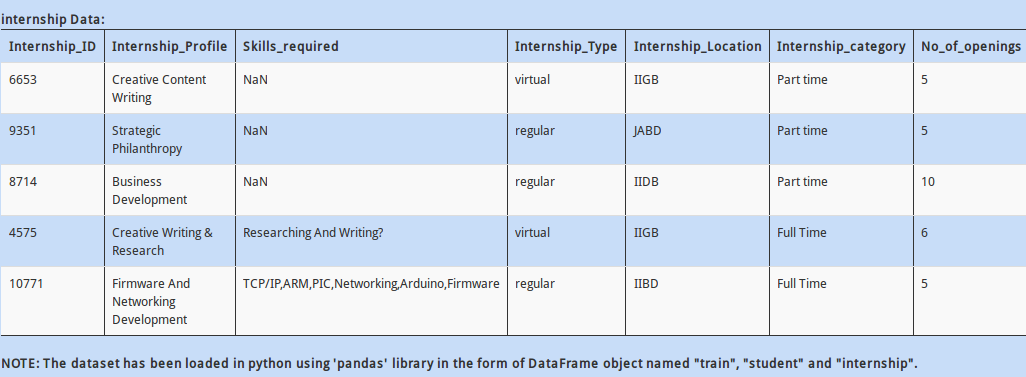
Q 9) 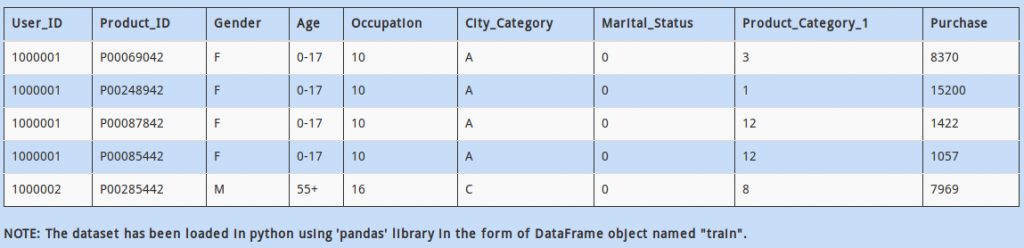 As you might be aware, most of the machine learning libraries in Python and their corresponding algorithms require data to be in numeric array format.
As you might be aware, most of the machine learning libraries in Python and their corresponding algorithms require data to be in numeric array format.
Hence, we need to convert categorical “Gender” values to numerical values (i.e. change M to 1 and F to 0). Which of the commands would do that?
A - train.ix[:, 'Gender'] = train.Gender.applymap({'M':1,'F':0}).astype(int)
B - train.ix[:, 'Gender'] = train.Gender.map({'M':1,'F':0}).astype(int)
C - train.ix[:, 'Gender'] = train.Gender.apply({'M':1,'F':0}).astype(int)
D – None of these
Solution: B
(diff map, apply)
Q 10)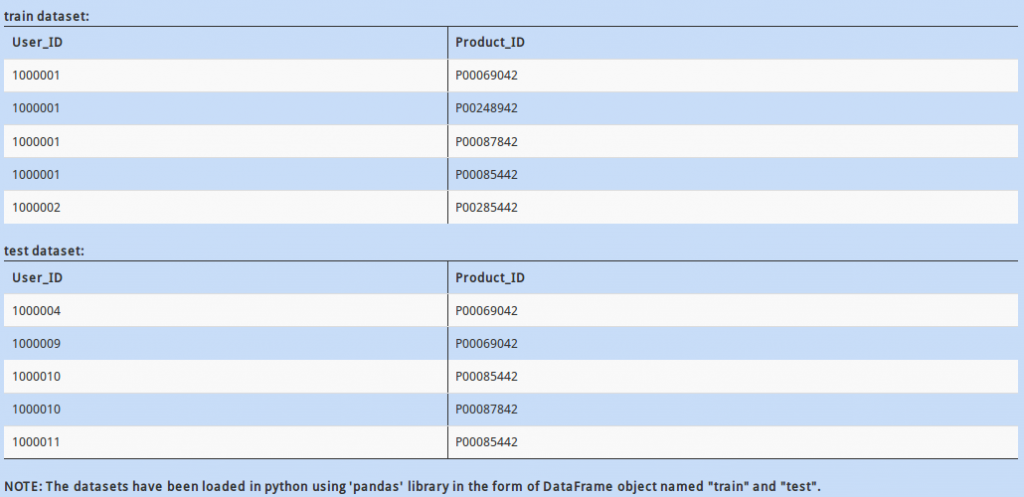
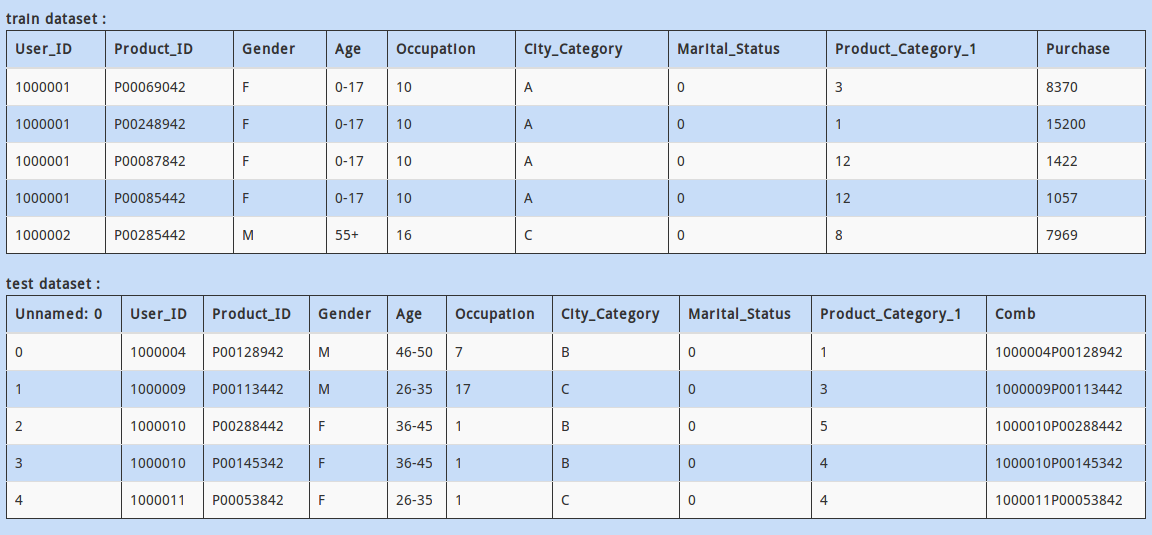
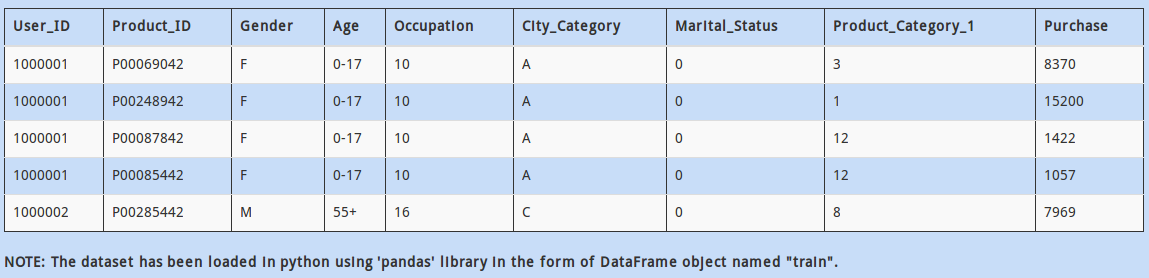
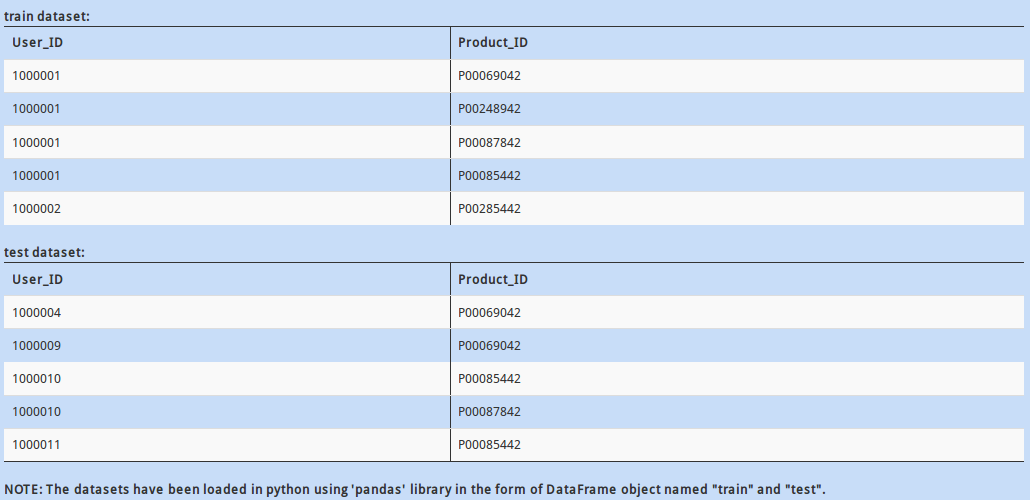
In the datasets above, “Product_ID” column contains a unique identification of the products being sold. There might be a situation when there are a few products present in the test data but not id train data. This could be troublesome for your model, as it has no “historical” knowledge for the new product.
How would you check if all values of “Product_ID” in test DataFrame are available in train DataFrame dataset?
A - train.Product_ID.unique().contains(test.Product_ID.unique())
B - set(test.Product_ID.unique()).issubset(set(train.Product_ID.unique()))
C - train.Product_ID.unique() = test.Product_ID.unique()
D – None of these
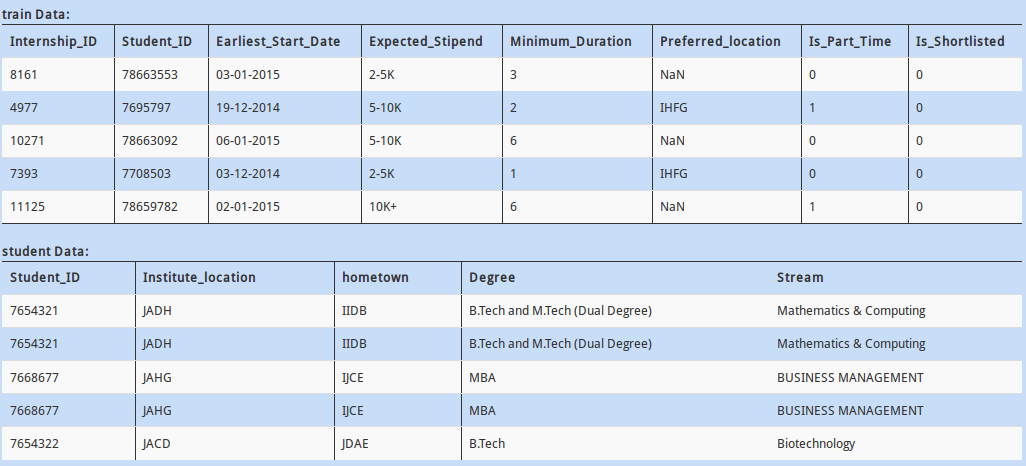
Q 11) 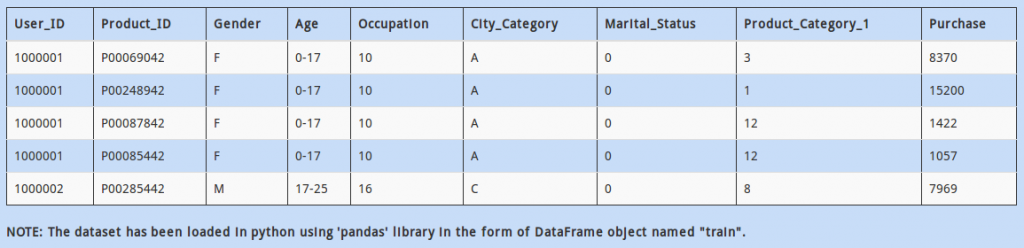
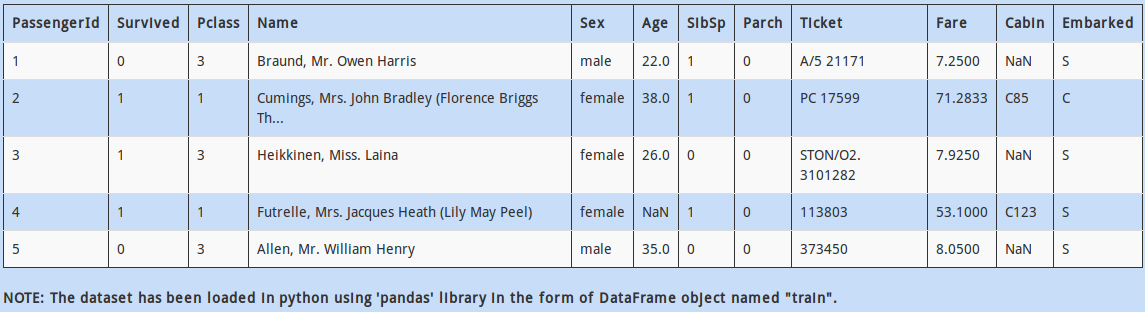
If you look at the data above, “Age” is currently a categorical variable. Converting it to a numerical field might help us extract more meaningful insight.
You decide to replace the Categorical column ‘Age’ by a numeric column by replacing the range with its average (Example: 0-17 and 17-25 should be replaced by their averages 8.5 and 21 respectively)
A - train['Age'] = train.Age.apply(lambda x: (np.array(x.split('-'), dtype=int).sum()) / x.shape)
B - train['Age'] = train.Age.apply(lambda x: np.array(x.split('-'), dtype=int).mean())
C – Both of these
D – None of these
Solution: B
A somewhat hacky approach, but it works. First you separate the string on “-” and then find its mean. (If you are wondering why option A doesn’t work, check it out! )
Q 12) 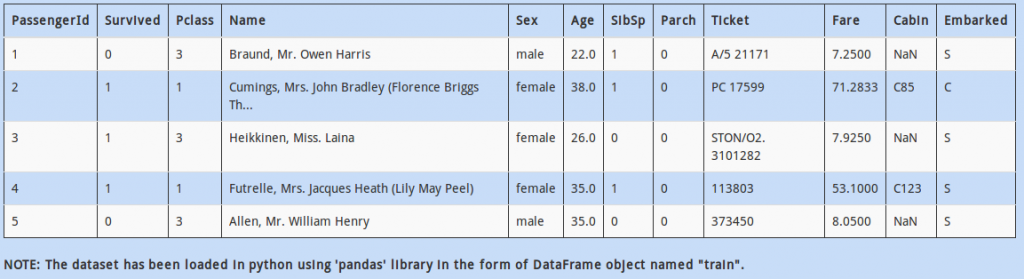
The other scenario in which numerical value could be “hiding in plain sight” is when it is plagued with characters. We would have to clean these values before moving on to model building.
For example, in “Ticket”, the values are represented as one or two blocks separated with spaces. Each block has numerical values in it, but only the first block has characters combined with numbers. (eg. “ABC0 3000”).
Which of the following code return only the last block of numeric values? (You can assume that numeric values are always present in the last block of this column)
A - train.Ticket.str.split(' ').str[0]
B - train.Ticket.str.split(' ').str[-1]
C - train.Ticket.str.split(' ')
D – None of these
Solution: B
To index the last term of a python list, you can use “-1”
Q 13)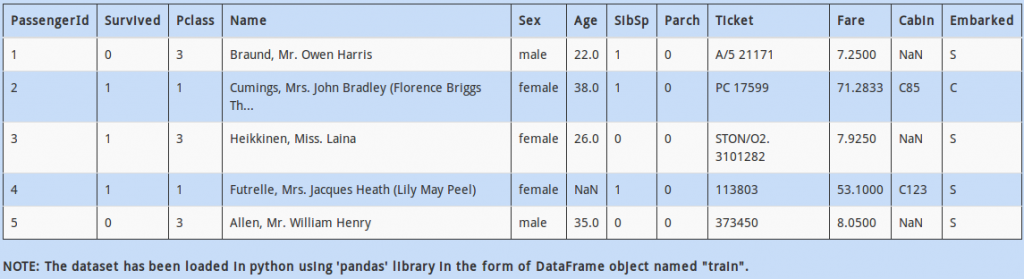
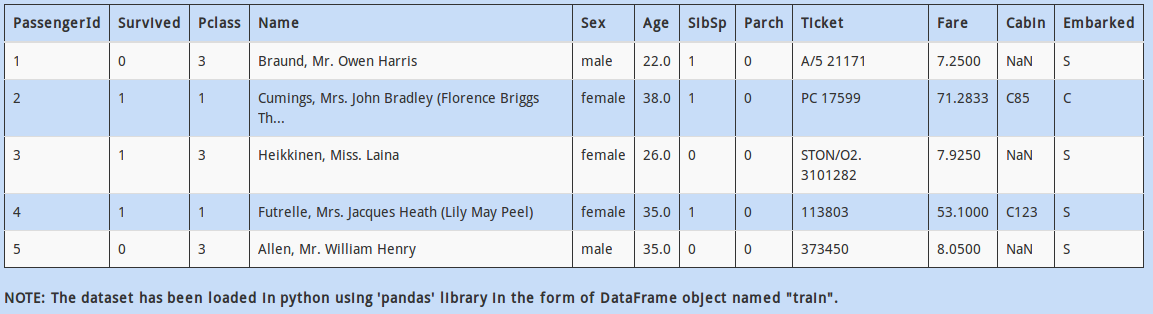
As you might have noticed (or if you haven’t, do it now!), the above dataset is the famous Titanic dataset. (PS: its a bit unclean than usual, but you get the gist, right? )
Coming back to the point, the data has missing values present in it. It is time to tackle them! The simplest way is to fill them with “known” values.
You decide to fill missing “Age” values by mean of all other passengers of the same gender. Which of the following code will fill missing values for all passengers by the above logic?
A - train = train.groupby('Sex').transform(lambda x: x.fillna(x.sum()))
B - train['Age'] = train.groupby('Sex').transform(lambda x: x.fillna(x.mean())).Age
C - train['Age'] = train.groupby('Sex').replace(lambda x: x.fillna(x.mean())).Age
D – None of these
Solution: B
To solve, group the data on “Sex”, and then fill all the missing values with the appropriate mean. Remember that python lambda is a very useful construct. Do try to inculcate the habit of using it.
Q 14) 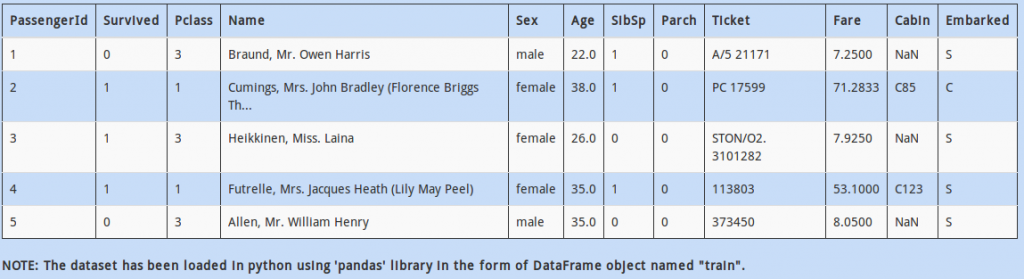
Let’s get to know the data a bit more.
We want to know how location affects the survival of people. My hypothesis is that people from location “S” (S=SouthHampton), particularly females, are more likely to survive because they had better “survival instincts”.
The question is, how many females embarked from location ‘S’?
A - train.loc[(train.Embarked == 'S') and (train.Sex == 'female')].shape[0]
B - train.loc[(train.Embarked == 'S') & (train.Sex == 'female')].shape[0]
C - train.loc[(train.Embarked == 'S') && (train.Sex == 'female')].shape[0]
D – None of these
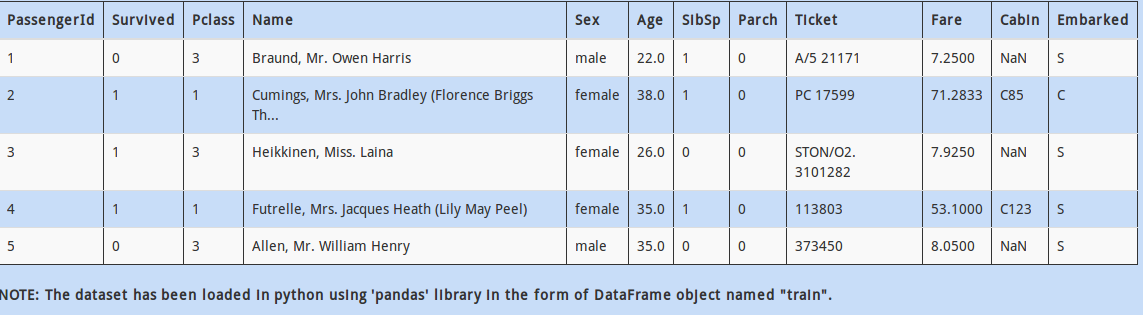
Q 15) 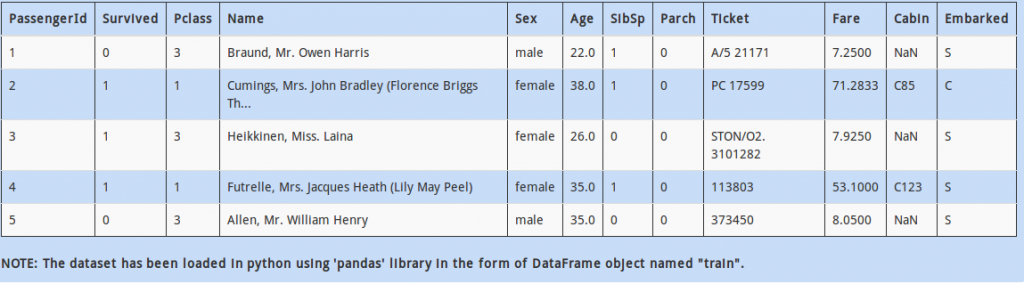
Look at the column “Name” – there is an important thing to notice. Looks like, every name has a title contained in it. For example, the name “Braund, Mr. Owen Harris” has “Mr.” in it.
Which piece of code would help us calculate how many values in column “Name” have “Mr.” contained in them?
A - (train.Name.str.find('Mr.')==False).sum()
B - (train.Name.str.find('Mr.')>0).sum()
C - (train.Name.str.find('Mr.')=0).sum()
D – None of these
Solution: B
As highlighted previously, boolean value “True” is represented by 1. So option B would be the appropriate answer.
Q 16) 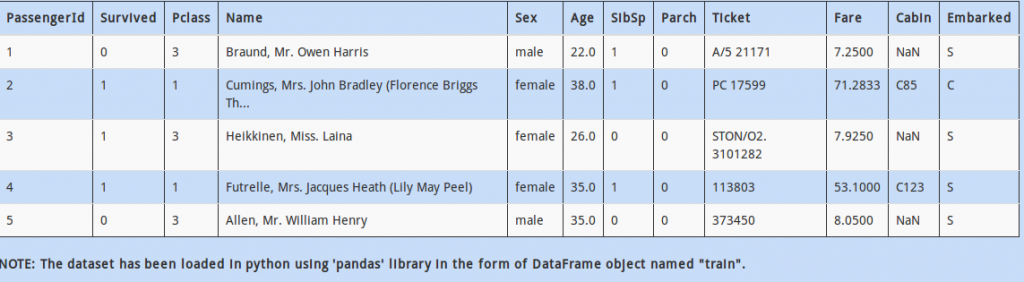
You can see that column “Cabin” has 3 missing values out 5 sample records.
If a particular column has a high percentage of missing values, we may want to drop the column entirely. However, this might also lead to loss of information.
Another method to deal with this type of variable, without losing all information, is to create a new column with flag of missing value as 1 otherwise 0.
Which of the following code will create a new column “Missing_Cabin” and put the right values in it (i.e. if “cabin_missing” then 1 else 0)?
A - train['Missing_Cabin'] = train.Cabin.apply(lambda x: x == '')
B - train['Missing_Cabin'] = train.Cabin.isnull() == False
C - train['Missing_Cabin'] = train.Cabin.isnull().astype(int)
D – None of these
Solution: C
To convert boolean values to integer, you can use “astype(int)”
Q 17)
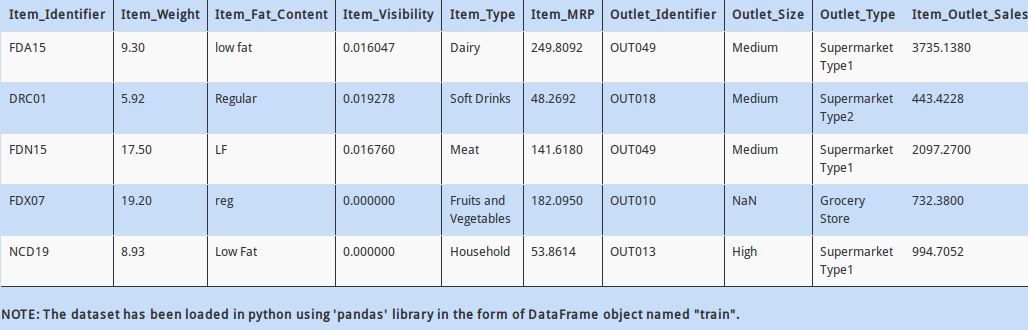
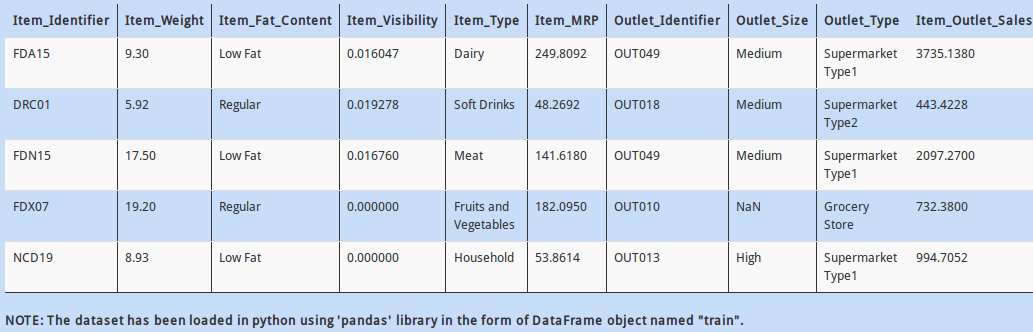
Let us take a look at another dataset. The data represents sales of an outlet along with product attributes.
The problem is, the dataset does not contain headers. Inspite of this, you know what are the appropriate column names. How would you read the the dataframe by specifying the column names?
A - pd.read_csv("train.csv", header=None, columns=['Item_Identifier', 'Item_Weight', 'Item_Fat_Content', 'Item_Visibility' ])
B - pd.read_csv("train.csv", header=None, usecols=['Item_Identifier', 'Item_Weight', 'Item_Fat_Content', 'Item_Visibility'])
C - pd.read_csv("train.csv", header=None, names=['Item_Identifier' ,'Item_Weight' ,'Item_Fat_Content', 'Item_Visibility'])
D – None of these
Solution: C
To explicitly specify column names in pandas, you can use “names” argument
Q 18)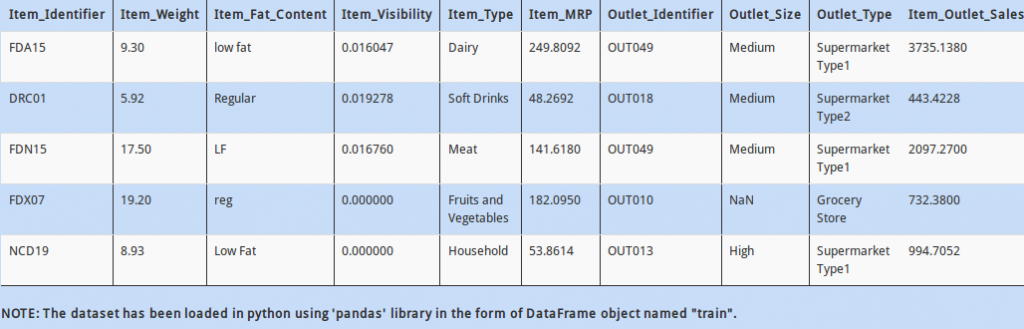
Sometimes while reading the data in pandas, the datatypes of columns are not parsed correctly. To deal with this problem, you can either explicitly specify datatypes while reading the data, or change the datatypes in the dataframe itself.
Which of the following code will change the datatype of “Item_Fat_Content” column from “object” to “category”?
A - train['Item_Fat_Content'] = train['Item_Fat_Content'].asdtype('categorical')
B - train['Item_Fat_Content'] = train['Item_Fat_Content'].astype('category')
C - train['Item_Fat_Content'] = train['Item_Fat_Content'].asdtype('category')
D – None of these
Solution: B
“category” datatype is a new feature added to pandas.
Q 19)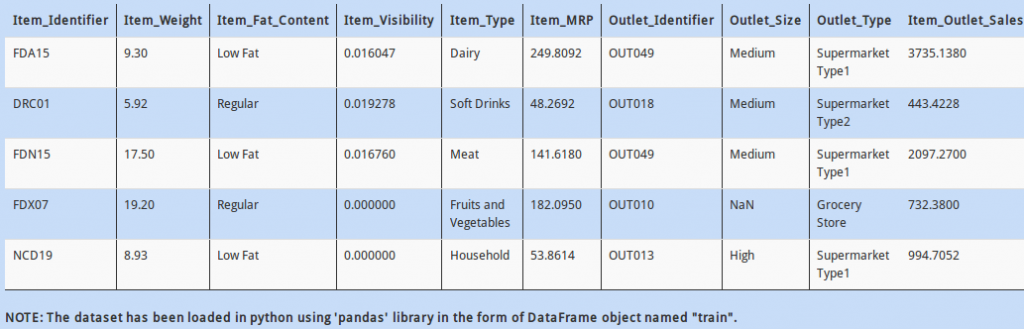
In above data, notice that the “Item_Identifier” column has some relation with the column “Item_Type”. As the first letter of “Item_Identifier” changes, the “Item_Type” changes too. For example, notice that if the value in “Item_Identifier” starts with “F”, then all the corresponding values in “Item_Type” are eatables, whereas those with “D” are drinks.
To check this hypothesis, find all values in “Item_Identifier” that starts with “F”.
A - train.Item_Identifier.str.starts_with('F')
B - train.Item_Identifier.str.startswith('F')
C - train.Item_Identifier.str.is_start('F')
D – None of these
Solution: B
Use “str” function in pandas to access string functions.
Q 20) 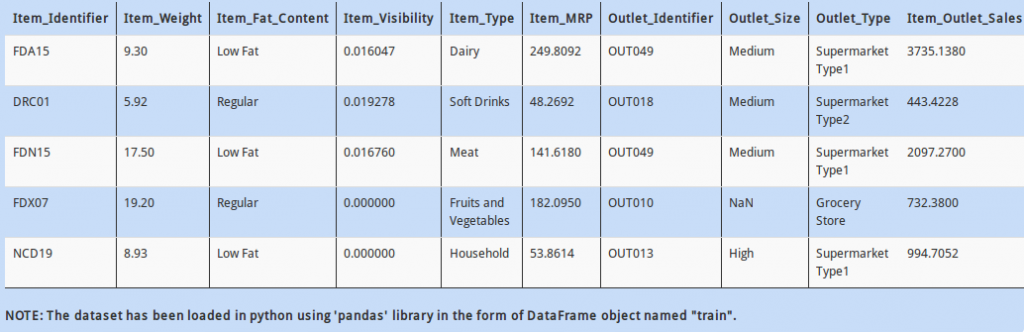
Just to give your mind some rest, let us do a simple thing; convert the float values in column “Item_MRP” to integer values
A - train['Item_MRP'] = train.Item_MRP.astype(real)
B - train['Item_MRP'] = train.Item_MRP.astype(int)
C - train['Item_MRP'] = train.Item_MRP.astype(float)
D – None of these
Solution: B
Q 21) 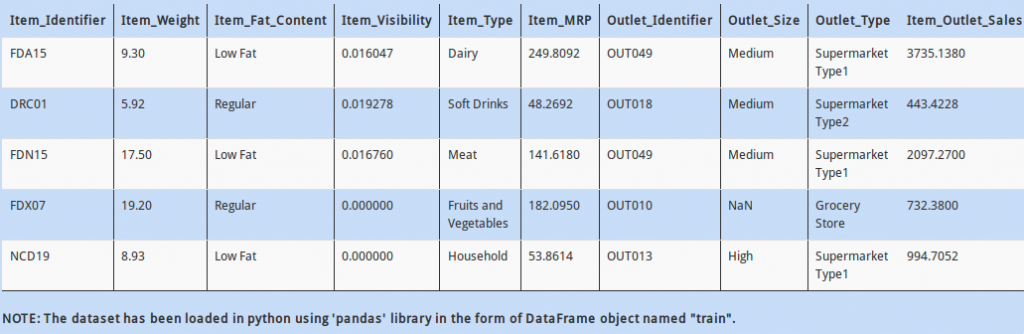
I have another hypothesis that, if an item is more visible to new customers in a supermarket, then its more likely to be sold.
So, find correlation between “Item_Outlet_Sales” and “Item_Visibility” (use correlation method ‘pearson’)
A - train.Item_Visibility.corr(train.Item_Outlet_Sales, method='pearson')
B - train.Item_Visibility.corr(train.Item_Outlet_Sales)
C - train.Item_Visibility.corrwith(train.Item_Outlet_Sales, method='pearson')
D – Both A and B
Solution: D
The default argument for “method” in “corr” function is “pearson”.
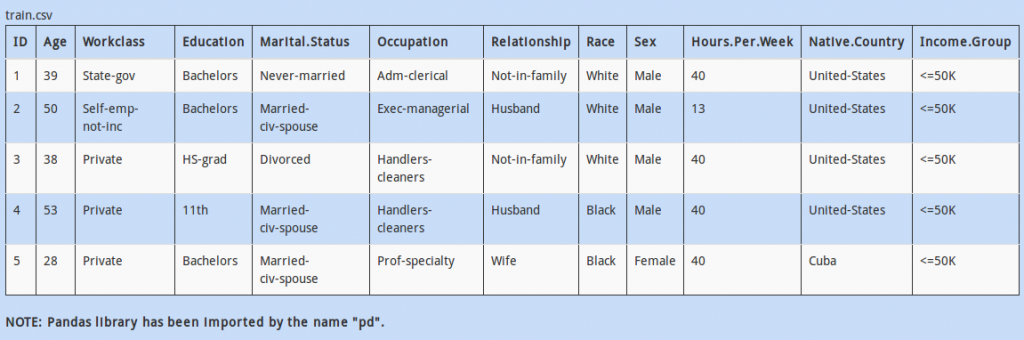
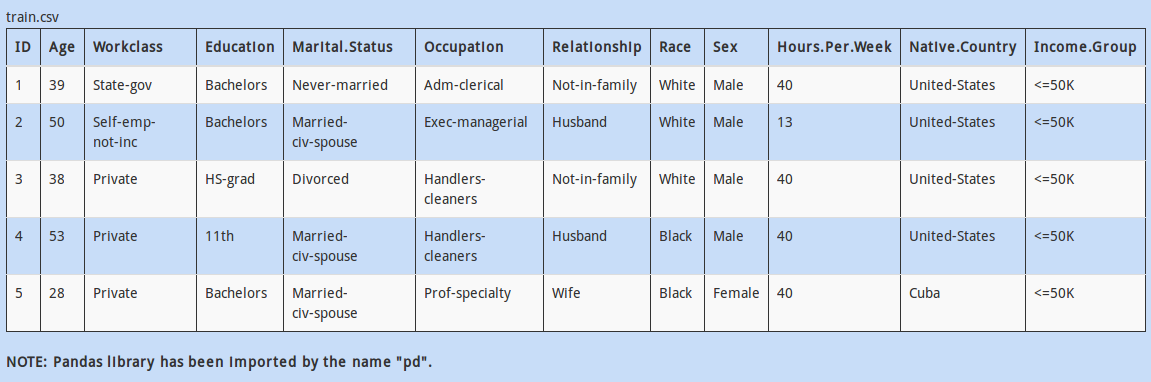
Q 22)
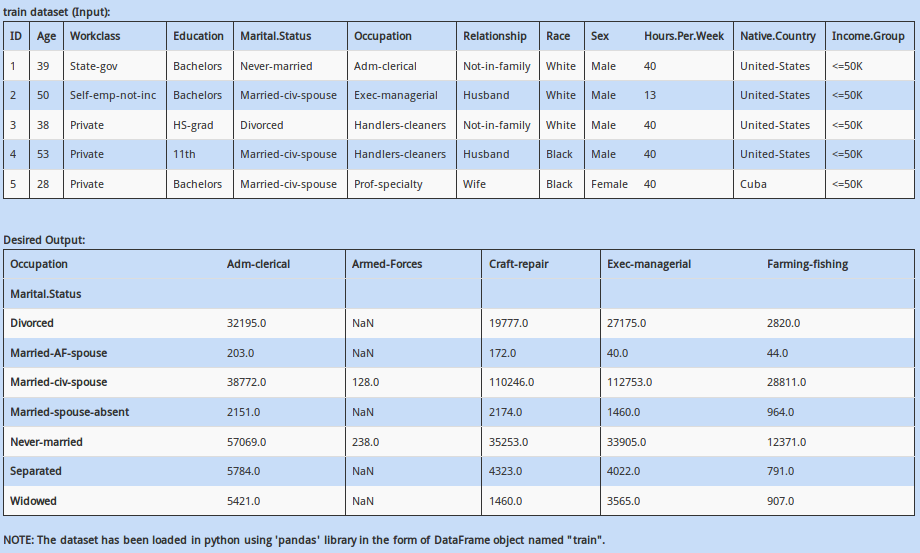 We want to check the distribution of the column ‘Hours.Per.Week’ with respect to ‘Marital.Status’ and ‘Occupation’ of the people. One thing we could do is to create a pivot table of ‘Marital.Status’ vs ‘Occupation’ and put the values.
We want to check the distribution of the column ‘Hours.Per.Week’ with respect to ‘Marital.Status’ and ‘Occupation’ of the people. One thing we could do is to create a pivot table of ‘Marital.Status’ vs ‘Occupation’ and put the values.
Create the pivot table as mentioned above, with the aggregating function as “sum”
A - train.pivot(index='Marital.Status', columns='Occupation', values='Hours.Per.Week', aggfunc='sum')
B - train.pivot_table(index='Marital.Status', columns='Occupation', values='Hours.Per.Week', aggfunc='sum')
C - train.pivot_table(index='Marital.Status', columns='Hours.Per.Week', values='Occupation', aggfunc='sum')
D – None of these
(pivot_table vs pivot)
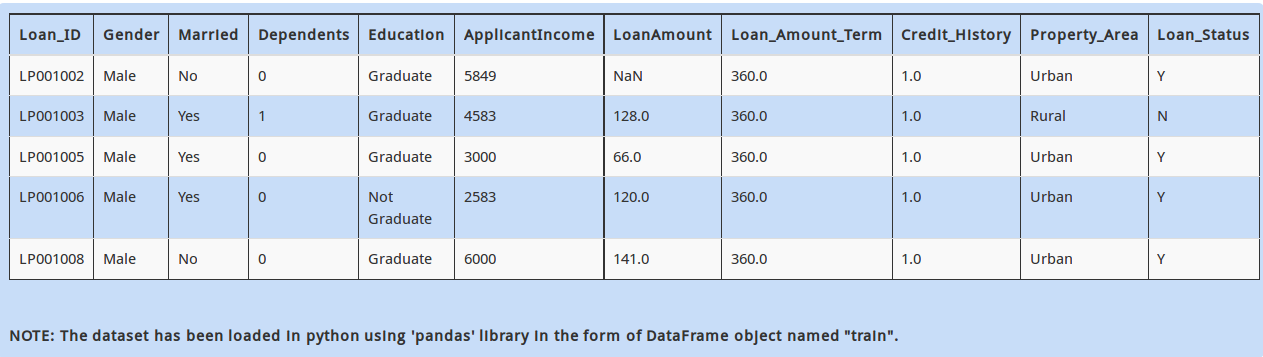
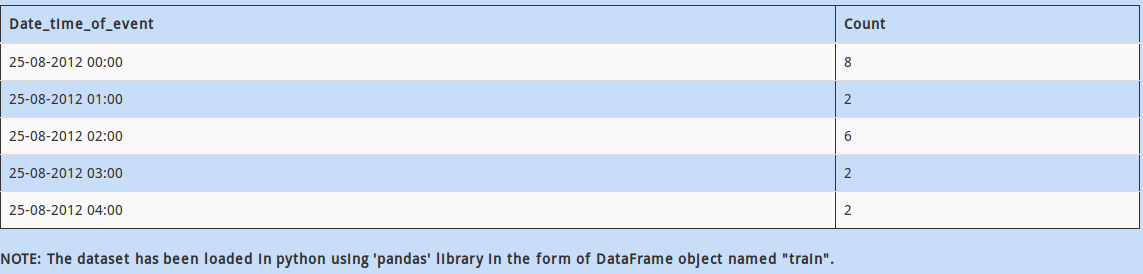
Q 23)
As you can see above, the first two rows are not part of the dataset. We want to start reading from the third row of the dataset.
How would we do this using pandas in python?
A - train = pd.read_csv('train.csv', startrow=2)
B - train = pd.csvReader('train.csv', startrow=2)
C - train = pd.read_csv('train.csv', skiprows=2)
D – None of these













不错不错
Thanks!
I took the test on sunday and it was very cool! Unfortunately, the test got stuck in question 25. As I clicked to go to the next question it kept going back to question 25 forever. I think I learned a bit more about Python and Analytics by taking the test. Keep on with this events! Greetings
Its great that you liked the skill test! The reason you got stuck is because the time allotted for the skilltest had ended, so the server shutdown. We are trying to make the experience more smooth in the future. Stay tuned!
Amazing questions I learnt a lot from this skill test. I like so much thanks for posting Many more to come
Thanks Hari! Stay tuned for more