Introduction
What is the one thing you enjoy most about Analytics Vidhya? The most popular answer we receive (and have received since Kunal transformed his idea into reality) is the content we publish. Our content is the one thing take pride in, and 2018 saw us take our high-quality content to a whole new level.
We launched multiple top-quality and popular training courses, published knowledge-rich machine learning and deep learning articles and guides, and saw our blog visits cross 2.5 million per month. A HUGE thanks to our community for supporting us and for your insatiable interest in this field!
As we draw the curtains on a wonderful 2018, we wanted to share the best of the year with our wonderful community. This article is part of that series and looks at the articles which you, dear reader, enjoyed the most. Do check out our other look-back articles so far:
- A Technical Overview of AI & ML (NLP, Computer Vision, Reinforcement Learning) in 2018 & Trends for 2019
- The 25 Best Data Science Projects on GitHub from 2018 that you Should Not Miss

In this collection, I have summarized each article and categorized them according to their respective domains. Each article also contains a summary of what the content is about. If you have any other articles you found particularly useful, we would love to hear about it. Do let us know in the comments box below.
And now without any further ado, let’s take a look at the top articles published on Analytics Vidhya in 2018!
Topics Covered in this Article
- Machine Learning and Deep Learning – The Ultimate Duo
- Business Intelligence and Data Visualization
- Careers in Data Science
- Natural Language Processing (NLP)
- Podcasts
Machine Learning and Deep Learning – The Ultimate Duo
A Comprehensive Guide to build a Recommendation Engine from Scratch (in Python)

Recommendation techniques have been around for decades (if not centuries). And the rise of machine learning has certainly accelerated the process of improving these techniques. We no longer have to rely on intuition and manual monitoring of behavior – combine the data with the right technique and voila! You have an extremely effective and profitable combination.
This article is one of the most comprehensive guides you’ll find anywhere on this topic. It covers the various types of recommendation engine algorithms and fundamentals of creating them in Python. Pulkit first explains what recommendation engines are and how they work. He then takes a case study in Python (using the popular MovieLens dataset) and uses that to explain how to build certain models. The two major techniques he has focused on are collaborative filtering and matrix factorization.
Once you’ve built your recommendation engine, how do you evaluate it? How can we tell whether it’s working as we had planned? Pulkit rounds off the guide by answering this question by showcasing six different evaluation techniques we can leverage to validate our model.
24 Ultimate Data Science Projects To Boost Your Knowledge and Skills (& can be accessed freely)

This is one of Analytics Vidhya’s most popular articles of all time. Originally published in 2016, our team updated it with the latest datasets from across industries. The datasets have been divided into three career levels – each level catering to the different stages of where you might be in your career:
- Beginner: This level comprises of data sets which are fairly easy to work with, and don’t require complex data science techniques
- Intermediate: This level comprises of data sets which are more challenging in nature. It consists of mid & large data sets which require some serious pattern recognition skills
- Advanced: This level is best suited for people who understand advanced topics like neural networks, deep learning, recommender systems, etc.
And the icing on the cake? Every project has a tutorial associated with it! So whether you want to learn from scratch, or are stuck at some point, or simply want to evaluate your results with a benchmark score, you can always bookmark and come back to that tutorial.
Understanding and Building an Object Detection Model from Scratch in Python

Object detection really took flight in 2018. It helps self-driving cars safely navigate through traffic, spots violent behavior in a crowded place, assists sports teams analyze and build scouting reports, ensures proper quality control of parts in manufacturing, among many, many other things. And these are just scratching the surface of what object detection technology can do!
In this article, Faizan Shaikh first explains what object detection is, before diving into the different approaches one can use to solve an object detection problem. He starts from the very basic approach of dividing the image into different parts and using an image classifier on each. The article then builds on that and improves with each step, eventually showcasing how deep learning can be used to build an end-to-end object detection model.
If this topic fascinates you, and you’re looking for a place to start your deep learning journey, I recommend checking out the awesome ‘Computer Vision using Deep Learning‘ course.
A Comprehensive Guide to Ensemble Learning (with Python codes)
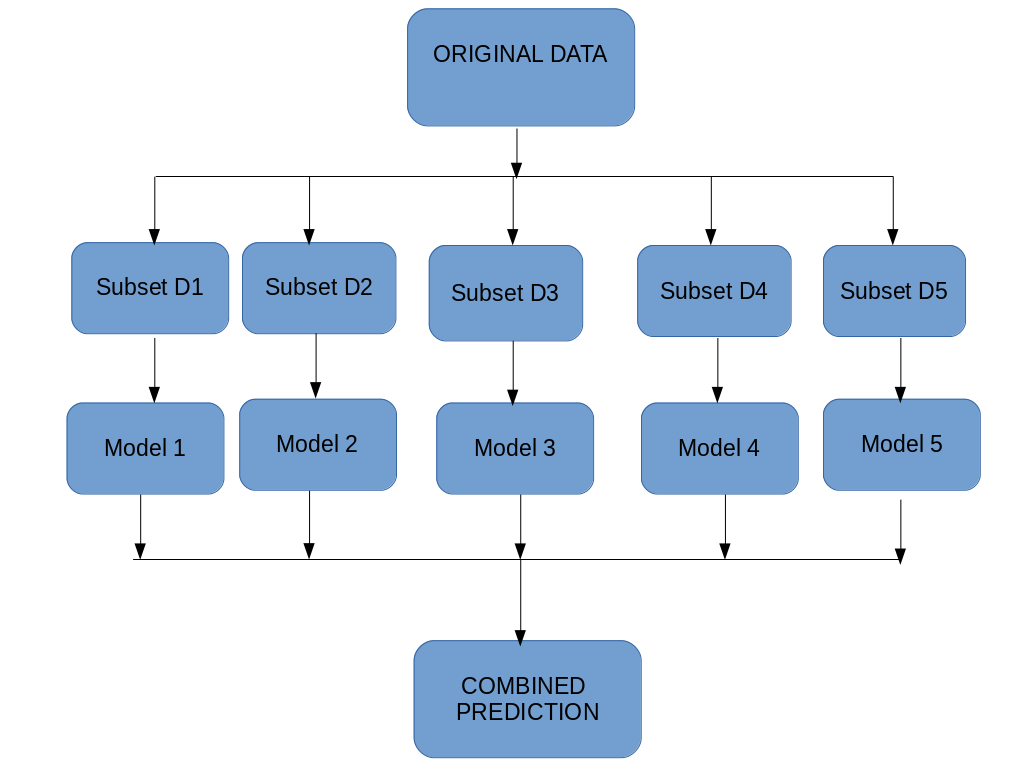
Ensemble learning comes into the picture once we’ve mastered the basic machine learning algorithms. It’s a fascinating concept and has been spectacularly well explained in this article. There are plenty of examples to help break down complex topics into easy-to-digest ideas.
And because of the comprehensive nature of this guide, Aishwarya guides us through plenty of techniques – bagging, boosting, Random Forest, LightGBM, CatBoost, among others. A treasure trove of information all in one place!
You will often come across this approach in hackathons – it’s a proven method of climbing up the leaderboard.
25 Open Datasets for Deep Learning Every Data Scientist Must Work With

What’s the best way to learn and ingrain a concept? Learning the theory is a good start, but learning by doing is when we truly understand how that technique works. And that’s especially true of a field that’s as vast as deep learning.
There’s no shortage of datasets to hone your skills – but where should you start? Which datasets are the best at building your profile? And can you get domain specific datasets which will help you get acquainted with that line of work? To help you out, we scoured the internet and hand-picked the top 25 open deep learning datasets.
These datasets are divided into three categories:
- Image Processing
- Natural Language Processing
- Audio/Speech Processing
So pick your interest and get started today!
The Ultimate Guide to 12 Dimensionality Reduction Techniques (with Python codes)

Ah, the curse of dimensionality. We all appreciate more data, it always helps to have a large enough training set. But as most data scientists will testify, having too much data can end up being quite a headache. What should you do when you’re faced with a dataset that has 1000s of variables? It’s not possible to analyze each variable at a granular level.
That’s where dimensionality reduction techniques play such a vital role. Reducing the number of features without losing (too much) information is something we all strive for. Dimensionality reduction is quite a powerful way of doing this, as Pulkit shows in this comprehensive article. Check out the 12 (yes 12!) techniques he discusses along with their implementation in Python, including Principal Component Analysis (PCA), Factor Analysis and t-SNE.
Business Intelligence and Data Visualization
Intermediate Tableau Guide for Data Science and Business Intelligence Professionals

Tableau is such a wonderful tool for analyzing the data at hand. But it’s not just limited to producing beautiful visualizations – you can perform Excel-like tasks in it as well. Tableau’s extended functionality really puts the “intelligence” in BI.
This article is aimed towards users who are familiar with the basic functionality of Tableau and wish to expand their knowledge of the tool. The author covers topics like joins, data blending, performing calculations, analyzing and understanding parameters, among other topics. It’s a beautifully illustrated article that will make you want to power up Tableau!
You can go through the Tableau Beginner’s Guide first in case you need a quick refresher.
A Step-by-Step Guide to learn Advanced Tableau – for Data Science and Business Intelligence Professionals
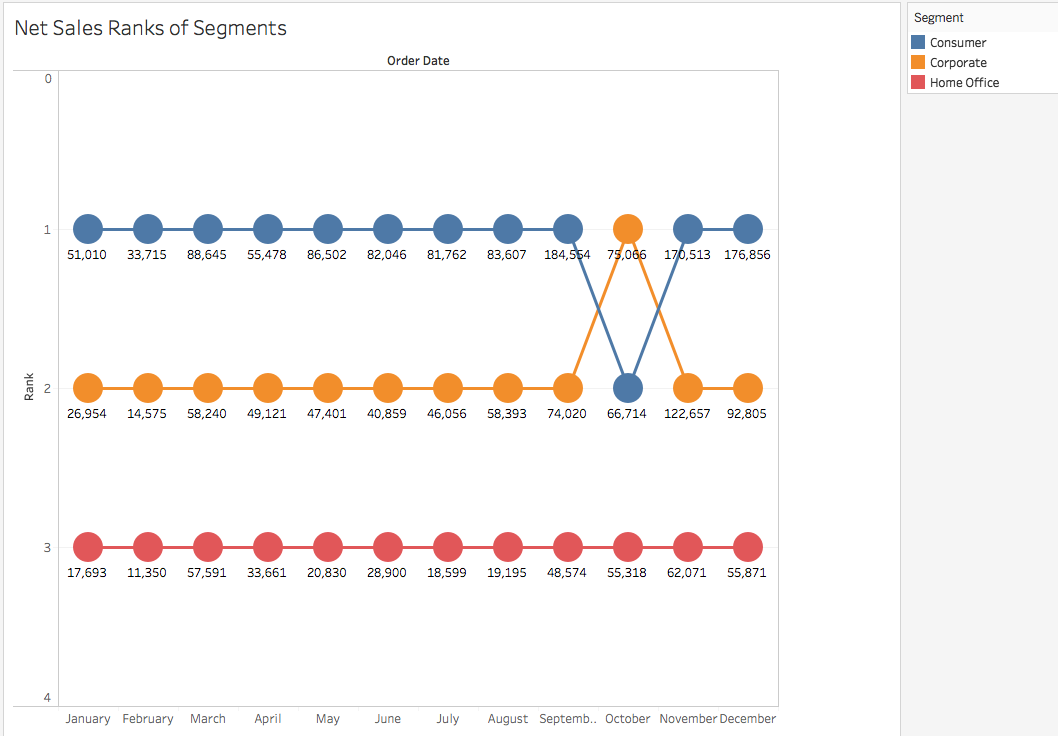
This guide is the logical next step after you’ve gone through the intermediate article. We move beyond the ‘Show Me’ feature of Tableau and explore advanced graphs here. As Pavleen puts it so eloquently – “there is something exciting and enrapturing about the grandeur of these advanced charts”.
The different charts covered in this article – Motion, Bump, Donut, Waterfall and Pareto. Additionally, you will be introduced to the concept of R programming in Tableau. This can come in really handy when you’re looking to combine data science with BI!
Careers in Data Science
The Most Comprehensive Data Science & Machine Learning Interview Guide You’ll Ever Need

I had a lot of fun putting this guide together. Interviews are often the biggest stumbling block aspiring data scientists face, and getting through them requires a combination of certain skills. Cracking these interviews becomes even more challenging if you’re coming from a non-technical background (like me).
What kind of questions are usually asked? What does the interviewer look for? What’s the right combination of technical and soft skills required? These can be daunting..only if you’re not prepared. And that was the idea behind writing this lengthy and detailed guide.
This comprehensive post covers multiple topics with plenty of resources, including data science and machine learning questions, tool specific quizzes, a variety of case studies, puzzles, guesstimates, and even a couple of really inspiring stories to point you towards the finishing line!
13 Common Mistakes Amateur Data Scientists Make and How to Avoid Them

Aspiring data scientists make tons of mistakes in their haste to break into the field. I’ve made plenty of them as well, and have penned down the 13 most common ones I have seen others experience. Trust me, becoming a data scientist is a tough path to take, and you’re not alone in making these mistakes.
Learning from someone else’s mistakes can also be a career-defining experience. Hence I have also provided a list of resources along with each point with the aim of helping you overcome these obstacles and accelerating your journey towards the promised land of data science.
Want to Become a Data Engineer? Here’s a Comprehensive List of Resources to get Started

We’ve been talking primarily about data scientists so far. But the field of data science has a variety of other roles to offer, and the hottest one right now is that of a data engineer. They’re overlooked in all the data scientist hype going around, but are very crucial cogs in any DS project.
There is currently no single structured path which one can follow to become a data engineer. You learn on the job, no tow ways about it. My hope is that this article will help provide a different option. There are tons of free resources here, including ebooks, video courses, text based article, etc.
Once we understand what a data engineer is and how the role is different from that of a data scientist, we dive straight into the various aspects you need to know in order to make this role your own. I have also mentioned a few data engineering certifications that are respected within the data science community.
Natural Language Processing
Ultimate Guide to deal with Text Data (using Python) – for Data Scientists & Engineers

This is one guide you NEED to read. This is the essential NLP beginner’s guide, which starts with some basic concepts and gradually builds towards more advanced techniques like Bag of Words and word embeddings. There are quite a number of ways you can approach a text data problem and you will understand these different methods here.
Feature extraction, preprocessing and advanced techniques – these are all covered in terms of text data. Each technique is showcased using Python code and an open dataset so you can code along as you learn.
You can also check out the comprehensive ‘Natural Language Processing using Python‘ course to get started with your own NLP career.
Building a FAQ Chatbot in Python – The Future of Information Searching

2018 was the year chatbots peaked. They were the most common application of Natural Language Processing (NLP) to hit the market. Understandably, more and more folks want to learn how to build one. Well, you’ve come to the right place!
This articles explores how to build a chatbot in Python by extracting information related to the recently introduced Goods and Services Tax (GST) in India. A GST-FAQ bot! The author has used the RASA-NLU library to build this bot.
Tutorial on Text Classification (NLP) using ULMFiT and fastai Library in Python
This is a very important topic – both for beginners as well as advanced NLP users. The ULMFiT framework was developed by Sebastian Ruder and Jeremy Howard and it has paved the way for other transfer learning libraries since. The article is more for folks who are familiar with basic NLP techniques and are looking to expand their portfolio.
Prateek Joshi takes a streamlined path to introduce us to the world of transfer learning, ULMFiT and finally, how to implement these concepts in Python. As Sebastian Ruder said, “NLP’s ImageNet moment has arrived”, and it’s time for you to jump on the wagon.
Podcasts
10 Data Science, Machine Learning and AI Podcasts You Must Listen To
Podcasts are a great medium of consuming information on the go. Not all of us have the time to read through articles. Podcasts have done an excellent job of filling that gap and keeping us up-to-date with the latest developments in machine learning. This collection of the top 10 podcasts went viral at the time of publication and has been at the top ever since.
We also launched our own podcast series this year called DataHack Radio. DHR features top leaders and practitioners in the data science and machine learning industry and caters to all levels of the data science community. It’s available on SoundCloud, iTunes and of course, our own site!
End Notes
Once again, a massive shout out to our community for their continued support and interest in data science. Let’s work together to make 2019 an even better and bigger year, and promise to keep our hunger for learning intact and well fuelled! See you next year.
Senior Editor at Analytics Vidhya.Data visualization practitioner who loves reading and delving deeper into the data science and machine learning arts. Always looking for new ways to improve processes using ML and AI.





Right on, man!!! I love this community!