Introduction
We are in the midst of a deep learning revolution. Unprecedented success is being achieved in designing deep neural network models for building computer vision and Natural Language Processing (NLP) applications.
State-of-the-art benchmarks are disrupted and updated on a regular basis in tasks like object detection, language translation, and sentiment analysis. It’s a great time to work with deep learning!
But there’s still one field that isn’t quite riding this success wave. The application of deep learning in Information Security (InfoSec) is still very much in its nascent stages. The flashy nature of other applications attracts newcomers and investors – but InfoSec is one of the most crucial fields every data scientist should pay attention to.

Here’s the good news – Malware detection and network intrusion detection are two areas where deep learning has shown significant improvements over the rule-based and classic machine learning-based solutions [3].
This article is the second part of our deep learning for cyber security series. We will demonstrate the power of deep neural networks using Tensorflow and Keras to detect obfuscated PowerShell scripts. As we mentioned – this is a must-read for anyone interested in this field.
We highly recommend the below reads to get the most out of this article:
- Using the Power of Deep Learning for Cyber Security (Part 1)
- Demystifying Information Security using Data Science
- Fundamentals of Deep Learning – Activation Functions and When to use them?
Table of Contents
- What is PowerShell?
- Understanding the Problem
- Gathering and Building the PowerShell Scripts Dataset
- Data Experiments
What is PowerShell?

PowerShell is a task automation and configuration management framework consisting of a robust command line shell. Microsoft open sourced and made it cross-platform compatible in August 2016.
PowerShell has been a heavily exploited tool in various cyber attacks scenarios. According to a research study by Symantec, nearly 95.4% of all scripts analyzed by Symantec Blue Coat Sandbox were malicious[4].
The Odinaff hacker group leveraged malicious PowerShell scripts as part of its attacks on banks and other financial institutions [5]. We can find many tools like PowerShell Empire [6] and PowerSploit [7] on the internet that can be used for reconnaissance, privilege escalation, lateral movement, persistence, defense evasion, and exfiltration.
Adversaries typically use two techniques to evade detection:
- First, by running fileless malware, they load malicious scripts downloaded from the internet directly into memory, thereby evading Antivirus (AV) file scanning
- Then, they use obfuscation to make their code challenging to decode. This makes it more difficult for any AV or analyst to figure out the intent of the script
Obfuscation of PowerShell scripts for malicious intent is on the rise. The task of analyzing them is made even more difficult due to the high flexibility of its syntax. In Acalvio high interaction decoys, we can monitor PowerShell logs, commands, and scripts that the attacker tried to execute in the decoy. We collect these logs and analyze them in real time and detect whether the script is obfuscated or not.
Understanding the Problem
Microsoft PowerShell is the ideal attacker’s tool in a Windows operating system. There are two primary reasons behind this:
- It is installed by default in Windows
- Attackers are better off using existing tools that allow them to blend well and possibly evade Antivirus (AV) software
Microsoft has enhanced PowerShell logging considerably since they launched PowerShell 3.0. If Script Block Logging is enabled, we can capture commands and scripts executed through PowerShell in the event logs. These logs can be analyzed to detect and block malicious scripts.
Obfuscation is typically used to evade detection. Daniel and Holmes address this problem of detecting obfuscated scripts in their Blackhat paper [8]. They used a Logistic Regression classifier with Gradient Descent method to achieve a reasonable classification accuracy to separate the obfuscated script from clean scripts.
However, a deep feed-forward neural network (FNN) might enhance other performance metrics, such as precision and recall. Hence in this blog, we decided to use a deep neural network and compare the performance metrics with different machine learning (ML) classifiers.
Gathering and Building the PowerShell Scripts Dataset
We have used the PowerShellCorpus dataset published and open sourced by Daniel [9] for our data experiments. The dataset consists of around ~300k PowerShell scripts scraped from various sources on the internet like Github, PowerShell Gallery, and Technet.
We also scraped PowerShell scripts from Poshcode [10] and added them to the corpus. Finally, we had nearly 3 GB of script data consisting of 300k clean scripts. We used the Invoke-Obfuscation [11] tool to obfuscate the scripts. Once we obfuscated all scripts using this tool, we labeled the dataset consisting of class labels as clean or obfuscated script.
Data Experiments
All the activities performed by an attacker in a high interaction decoy are malicious. However, obfuscation detection asserts the presence of an advanced attacker. Here is a simple PowerShell command to get a list of processes:
Get-Process| Where($_.Handles -gt 600}| sort Handles| Format - Table
This command may be obfuscated as:
(((“{2}{9}{12}{0}{3}{10}{13}{4}{18}{8}{17}{11}{5}{16}{1}{15}{14}{7}{19}{6}"-f'-P','es','G',
'rocess8Dy Whe',' {','S','le','-Ta','-gt','e','r','y ','t','e','t',' 8Dy Forma','ort Handl',' 600} 8D','RYl_.Handles ','b'))
-crePLACE'8Dy',[cHar]124-crePLACE'RYl',[cHar]36) | IEx
This looks suspicious and noisy. Here is another example of a subtle obfuscation for the same command:
&(“{1}{2}{0}"-f 's','G','et-Proces')| &("{1}{0}"-f'here','W') {$_.Handles -gt 600} | &("{1}{0}" -f'ort','S') Handles | .("{1}{0}{2}"-f '-','Format','Table')
This obfuscation makes it hard to detect the intent of the PowerShell command/script. Most of the malicious PowerShell scripts in the wild have these kinds of subtle variations that help them to evade anti-virus software easily.
It is nearly impossible for a security analyst to review every PowerShell script to determine whether it is obfuscated or not. Therefore, we need to automate the obfuscation detection. We can use a rule-based approach for obfuscation detection; however, it may not detect a lot of obfuscation types, and a large number of rules need to be manually written by a domain expert. Therefore, a machine learning/deep learning-based solution is an ideal answer for this problem.
Typically, the first step of machine learning is data cleaning and preprocessing. For the obfuscation detection dataset, the data preprocessing task is done to remove Unicode characters from a script.
Obfuscated scripts look different from normal scripts. Some combination of characters used in obfuscated scripts are not used in normal scripts. So, we use character-level representation for all PowerShell scripts instead of word-based representation.
Also, in the case of PowerShell scripting, sophisticated obfuscation can sometimes completely blur the boundary between words/tokens/identifiers, rendering it useless for any word-based tokenization. In fact, character-based tokenization is also used by security researchers to detect PowerShell obfuscated scripts.
Lee Holmes from Microsoft has explored character frequency-based representation and cosine similarity to detect obfuscated scripts in his blog [12].
There are multiple ways in which characters can be vectorized. One-hot encoding of characters represents every character by a bit. The bit is set to 0 or 1 depending upon whether that character is present in the script or not. The classifiers trained with a single character one-hot encoding perform well.
However, this can be improved by capturing the sequence of characters. For example, a command like New-Object may be obfuscated as (‘Ne’+’w-‘+’Objec’+’t’). The character plus (+) operator is common for any PowerShell script. However, plus (+) followed by a single (‘) or double quote (“) may not be as common. Therefore, we use tf-idf character bigrams to represent as the features input to the classifiers.
Here are 20 bigrams with top tf-idf score from the training dataset:
Clean script:
['er', 'te', 'in', 'at', 're', 'pa', 'st', 'on', 'me', 'en', 'ti', 'le', 'th', 'am', 'nt', 'es', 'se', 'or', 'ro', 'co']
Obfuscated script:
["'+", "+'", '}{', ",'", "',", 'er', 'te', 'in', 're', 'me', 'st', 'et', 'se', 'ar', 'on', 'at', 'ti', 'am', 'es', '{1']
Each script is represented using the character bigrams. We process all these features using a deep Feed Forward Neural Network (FFN) with N hidden layers using Keras and Tensorflow.
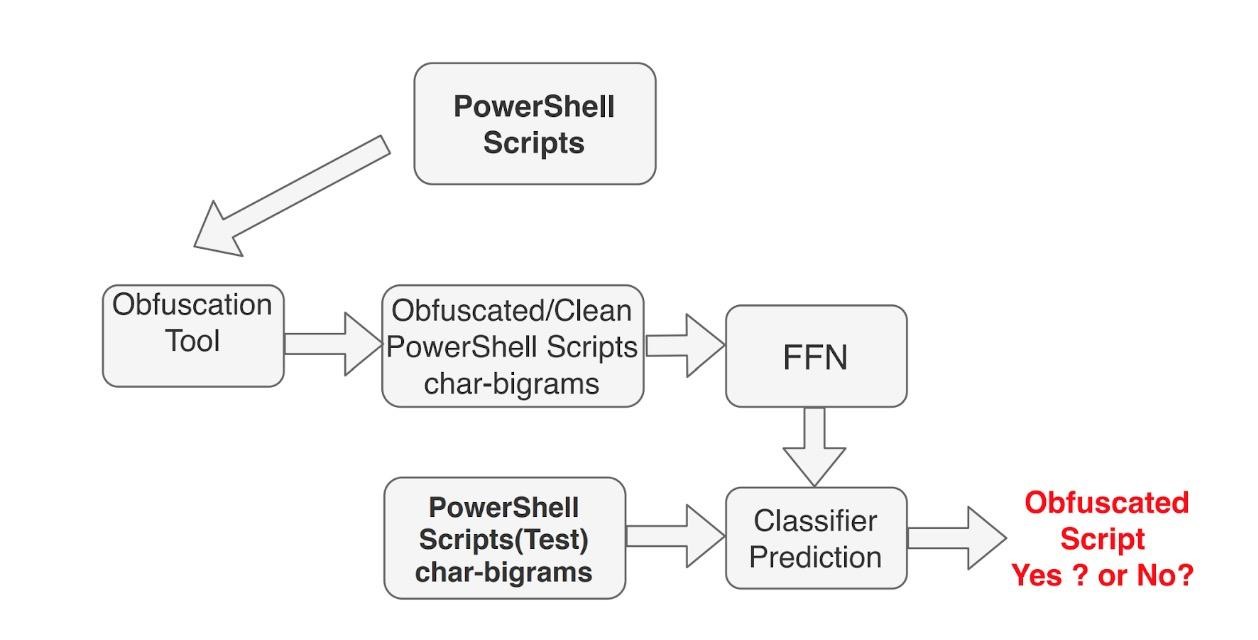
Figure 1: Obfuscation Detection data flow diagram using deep FFN
The data flow diagram above shows the training and prediction flow for obfuscation detection. We have varied the value of hidden layers in the deep FNN and found N=6 to be optimal.
The RELU activation function is used for all the hidden layers. Each hidden layer is dense in nature with a dimension of 1000 and a dropout rate of 0.5. For the last layer, sigmoid is used as the activation function. Figure 2 below shows the deep FFN network representation for obfuscation detection:

Figure 2: FFN Network Representation for Obfuscation Detection
We see a validation accuracy of nearly 92% that indicates the model has generalized well outside the training set.
Next, we test our model on the test set. We get an accuracy of 93% with 0.99 recall for the obfuscated class. Figure 3 below shows the classification accuracy and classification loss plots for training and validation data for each epoch:

Figure 3: Classification Accuracy and Loss plots for Training and Validation Phase
Check out the results of our deep FNN as compared to other ML models in the table below. Precision and recall were used to measure the efficacy of the various models:
| Classifier Used | Precision | Recall |
| Random Forest | 0.92 | 0.97 |
| Logistic Regression | 0.91 | 0.87 |
| Deep Feed-forward Neural Network (FNN) | 0.89 | 0.99 |
Our objective is to correctly detect most of the obfuscated scripts as the obfuscated script. In other words, we would like to minimize the false negative rate for the obfuscated class. The Recall metric seems to be the appropriate measure in this case.
Table 1 shows that the deep FNN model achieves more recall as compared to other classifiers. The dataset used in our experiments is of medium scale. The datasets used in the wild are typically quite big, and deep FNN performs even better as compared to the other ML classifiers.
End Notes
PowerShell obfuscation is a smart way to bypass existing antivirus software and hide the attacker’s intent. Many adversaries use this technique.
In this blog, we demonstrated the power of deep learning to detect obfuscated PowerShell scripts. In our next blog of this series, we will share some more use cases where AI and deception can be leveraged for information security.
References
- [1] “Deep Learning,” Ian Goodfellow, Yoshua Bengio, Aaron Courville; pp 196, MIT Press, 2016.
- [2] “Using the Power of Deep Learning for Cyber Security,” Acalvio Blog, 2018.
- [3] “Malware detection using machine learning,” Dragoş Gavriluţ, Mihai Cimpoeşu, Dan Anton, Liviu Ciortuz; International Multiconference on Computer Science and Information Technology, Mragowo, 2009
- [4] “The increased use of Powershell in attacks,” Symantec, 2016
- [5] “Odinaff: New Trojan used in financial attacks,” Symantec Security Response, Oct 2016
- [6] “Empire,” Will Schroeder, Justin Warner, Matt Nelson, Steve Borosh, Alex Rymdeko-harvey, Chris Ross; 2017
- [7] “PowerSploit,” Matthew Graeber; 2012
- [8] “Revoke-Obfuscation,” Daniel Bohannan, Lee Holmes; 2017
- [9] “PowerShell Corpus”
- [10] “PoshCode – PowerShell Projects for Power Users.”
- [11] “Invoke-Obfuscation,” Daniel Bohannan; 2017
- [12] ”More Detecting Obfuscated PowerShell,” Lee Holmes; 2016
About the Authors

Santosh Kosgi, Data Scientist – Acalvio Technologies
Santosh is a member of Data Science team at Acalvio Technologies. He holds a Masters in Computer Science from IIIT Hyderabad. He previously worked at 247.ai. He is interested in solving real world problems using Machine Learning.

Arunabha Choudhury, Data Scientist – Acalvio Technologies
Arunabha is a member of the Data Science team at Acalvio Technologies. He holds a Masters Degree in CS from University of Kansas with minor in Machine Learning. In his 6+ years of experience as Data Scientists, he has worked with companies like Tresata (now considered a Big Data Unicorn based out of Charlotte, NC) and Samsung R&D. To his credit he has 3 patents and 4 conference publications. He is primarily interested in Machine Learning at Scale.

Waseem Mohd., Data Scientist – Acalvio Technologies
Waseem is a member of the Data Science team at Acalvio. He is a Computer Science graduate from IIT Delhi and has previously worked with companies like Samsung and Microsoft. He is interested in real world applications of Deep Learning.

Dr. Satnam Singh, Chief Data Scientist – Acalvio Technologies
Dr. Satnam Singh is currently leading security data science development at Acalvio Technologies. He has more than a decade of work experience in successfully building data products from concept to production in multiple domains. He was named as one of the top 10 data scientists in India in 2015. He has 25+ patents and 30+ journal and conference publications to his credit.
Apart from holding a PhD degree in ECE from University of Connecticut, Satnam also holds a Masters in ECE from University of Wyoming. Satnam is a senior IEEE member and a regular speaker in various Big Data and Data Science conferences.

