
I love being a data scientist working in Natural Language Processing (NLP) , transformers in nlp and learning through NLP Training right now. The breakthroughs and developments are occurring at an unprecedented pace. From the super-efficient ULMFiT framework to Google’s BERT, transformers nlp is truly in the midst of a golden era.
And at the heart of this revolution is the concept of the Transformer. This has transformed the way we data scientists work with text data – and you’ll soon see how in this article.
Want an example of how useful Transformer is? Take a look at the paragraph below:

The highlighted words refer to the same person – Griezmann, a popular football player. It’s not that difficult for us to figure out the relationships among such words spread across the text. However, it is quite an uphill task for a machine.
Capturing such relationships and sequences of words in sentences is vital for a machine to understand a natural language. This is where the transformer in NLP concept plays a major role.
Note: This article assumes a basic understanding of a few deep learning concepts:
- Essentials of Deep Learning – Sequence to Sequence modeling with Attention
- Fundamentals of Deep Learning – Introduction to Recurrent Neural Networks
- Comprehensive Guide to Text Summarization using Deep Learning in Python
Table of contents
Sequence-to-Sequence Models – A Backdrop
Sequence-to-sequence (seq2seq) models in NLP are used to convert sequences of Type A to sequences of Type B. For example, translation of English sentences to German sentences is a sequence-to-sequence task.
Recurrent Neural Network (RNN) based sequence-to-sequence models have garnered a lot of traction ever since they were introduced in 2014. Most of the data in the current world are in the form of sequences – it can be a number sequence, text sequence, a video frame sequence or an audio sequence.
The performance of these seq2seq models was further enhanced with the addition of the Attention Mechanism in 2015. How quickly advancements in NLP have been happening in the last 5 years – incredible!
These sequence-to-sequence models are pretty versatile and they are used in a variety of NLP tasks, such as:
- Machine Translation
- Text Summarization
- Speech Recognition
- Question-Answering System, and so on
RNN based Sequence-to-Sequence Model
Let’s take a simple example of a sequence-to-sequence model. Check out the below illustration:

The above seq2seq model is converting a German phrase to its English counterpart. Let’s break it down:
- RNNs serve as both the Encoder and Decoder.
- During each time step in the Encoder, the RNN processes a word vector (xi) from the input sequence and a hidden state (Hi) from the previous time step.
- The hidden state undergoes updates at each time step.
- The last unit’s hidden state becomes the context vector, containing information about the input sequence.
- This context vector is transmitted to the decoder, which employs it to generate the target sequence (English phrase).
- When using the Attention mechanism, the decoder receives the weighted sum of the hidden states as the context vector.
Challenges
Despite being so good at what it does, there are certain limitations of seq-2-seq models with attention:
- Dealing with long-range dependencies is still challenging
- The sequential nature of the model architecture prevents parallelization. These challenges are addressed by Google Brain’s transformer in NLP concept
Introduction to the Transformer
The Transformer in NLP is a novel architecture that aims to solve sequence-to-sequence tasks while handling long-range dependencies with ease. The Transformer was proposed in the paper Attention Is All You Need. It is recommended reading for anyone interested in NLP.
Quoting from the paper:
“The Transformer is the first transduction model relying entirely on self-attention to compute representations of its input and output without using sequence-aligned RNNs or convolution.”
Here, “transduction” means the conversion of input sequences into output sequences. The idea behind Transformer is to handle the dependencies between input and output with attention and recurrence completely.
Let’s take a look at the architecture of the Transformer below. It might look intimidating but don’t worry, we will break it down and understand it block by block.
Understanding Transformer’s Model Architecture

The above image is a superb illustration of transformer in NLP architecture. Let’s first focus on the Encoder and Decoder parts only.
Now focus on the below image. The Encoder block has 1 layer of a Multi-Head Attention followed by another layer of Feed Forward Neural Network. The decoder, on the other hand, has an extra Masked Multi-Head Attention.

The encoder and decoder blocks are actually multiple identical encoders and decoders stacked on top of each other. Both the encoder stack and the decoder stack have the same number of units.
The number of encoder and decoder units is a hyperparameter. In the paper, 6 encoders and decoders have been used.

Let’s see how this setup of the encoder and the decoder stack works:
- The first encoder receives the word embeddings of the input sequence.
- It then transforms and propagates them to the next encoder.
- The output from the last encoder in the encoder-stack is passed to all the decoders in the decoder-stack, as depicted in the figure below:

An important thing to note here – in addition to the self-attention and feed-forward layers, the decoders also have one more layer of Encoder-Decoder Attention layer. This helps the decoder focus on the appropriate parts of the input sequence.
You might be thinking – what exactly does this “Self-Attention” layer do in the Transformer architecture NLP? Excellent question! This is arguably the most crucial component in the entire setup so let’s understand this concept.
Getting a Hang of Self-Attention
According to the paper:
“Self-attention, sometimes called intra-attention, is an attention mechanism relating different positions of a single sequence in order to compute a representation of the sequence.”

Take a look at the above image. Can you figure out what the term “it” in this sentence refers to?
Is it referring to the street or to the animal? It’s a simple question for us but not for an algorithm. When the model is processing the word “it”, self-attention tries to associate “it” with “animal” in the same sentence.
Self-attention allows the model to look at the other words in the input sequence to get a better understanding of a certain word in the sequence. Now, let’s see how we can calculate self-attention.
Calculating Self-Attention
I have divided this section into various steps for ease of understanding.
First, we need to create three vectors from each of the encoder’s input vectors:
- Query Vector
- Key Vector
- Value Vector.
During the training process, we train and update these vectors. We’ll gain a deeper understanding of their roles once we complete this section.
Next, we will calculate self-attention for every word in the input sequence
Consider this phrase – “Action gets results”. To calculate the self-attention for the first word “Action”, we will calculate scores for all the words in the phrase with respect to “Action”. This score determines the importance of other words when we are encoding a certain word in an input sequence
1. Taking the dot product of the Query vector (q1) with the keys vectors (k1, k2, k3) of all the words calculates the score for the first word:

2. Then, these scores are divided by 8 which is the square root of the dimension of the key vector:

3. Next, these scores are normalized using the softmax activation function:

Checkout this article about the Advanced Encoders and Decoders in Generative AI
4. These normalized scores are then multiplied by the value vectors (v1, v2, v3) and sum up the resultant vectors to arrive at the final vector (z1).
This is the output of the self-attention layer. It is then passed on to the feed-forward network as input.

So, z1 is the self-attention vector for the first word of the input sequence “Action gets results”. We can get the vectors for the rest of the words in the input sequence in the same fashion:

In the Transformer’s architecture, self-attention is computed multiple times, in parallel and independently. This process is referred to as Multi-head Attention. The outputs concatenate and linearly transform, as depicted in the figure below:
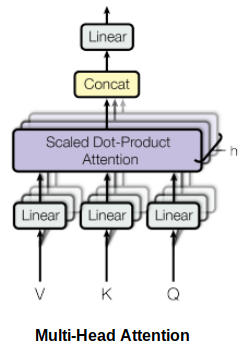
According to the paper “Attention Is All You Need”:
“Multi-head attention allows the model to jointly attend to information from different representation subspaces at different positions.”
You can access the code to implement Transformer here.
Limitations of the Transformer
Transformer architecture NLP is undoubtedly a huge improvement over the RNN based seq2seq models. But it comes with its own share of limitations:
- Attention can only deal with fixed-length text strings. The text has to be split into a certain number of segments or chunks before being fed into the system as input
- This chunking of text causes context fragmentation. For example, if a sentence is split from the middle, then a significant amount of context is lost. In other words, the text is split without respecting the sentence or any other semantic boundary
So how do we deal with these pretty major issues? That’s the question folks who worked with Transformer asked. And out of this came Transformer-XL.
Understanding Transformer-XL
Transformer in NLP architectures can learn longer-term dependency. However, they can’t stretch beyond a certain level due to the use of fixed-length context (input text segments). A new architecture was proposed to overcome this shortcoming in the paper – Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context.
In this architecture, we reuse the hidden states obtained in previous segments as a source of information for the current segment. It enables modeling longer-term dependency as the information can flow from one segment to the next.
Using Transformer for Language Modeling
Think of language modeling as a process of estimating the probability of the next word given the previous words.
Al-Rfou et al. (2018) proposed the idea of applying the transformer architecture NLP model for language modeling. As per the paper, the entire corpus can be split into fixed-length segments of manageable sizes. Then, we train the Transformer model on the segments independently, ignoring all contextual information from previous segments:

This architecture doesn’t suffer from the problem of vanishing gradients. But the context fragmentation limits its longer-term dependency learning. During the evaluation phase, shifting the segment to the right by only one position occurs. Processing the new segment entirely from scratch is necessary. This evaluation method is unfortunately quite compute-intensive.
Checkout this article about the Evaluation Metrics for Classification Model
Using Transformer-XL for Language Modeling
During the training phase in Transformer-XL, we use the hidden state computed for the previous state as an additional context for the current segment. This recurrence mechanism of Transformer-XL takes care of the limitations of using a fixed-length context.

During the evaluation phase, reusing representations from previous segments is possible instead of computing them from scratch, as in the case of the Transformer model. This, of course, increases the computation speed manifold.
You can access the code to implement Transformer-XL here.
The New Sensation in NLP: Google’s BERT (Bidirectional Encoder Representations from Transformers)
We all know how significant transfer learning has been in the field of computer vision. For instance, one could fine-tune a pre-trained deep learning model for a new task on the ImageNet dataset and still achieve decent results on a relatively small labeled dataset.
Language model pre-training similarly has been quite effective for improving many natural language processing tasks: Click here and here.
The BERT framework, a new language representation model from Google AI, uses pre-training and fine-tuning to create state-of-the-art models for a wide range of tasks. These tasks include question answering systems, sentiment analysis, and language inference.

BERT’s Model Architecture
BERT uses a multi-layer bidirectional Transformer encoder. Its self-attention layer performs self-attention in both directions. Google has released two variants of the model:
- BERT Base: Number of Transformers layers = 12, Total Parameters = 110M
- BERT Large: Number of Transformers layers = 24, Total Parameters = 340M

BERT uses bidirectionality by pre-training on a couple of tasks — Masked Language Model and Next Sentence Prediction. Let’s discuss these two tasks in detail.
BERT Pre-Training Tasks
The following two unsupervised prediction tasks pre-train BERT.
Masked Language Modeling (MLM)
According to the paper:
“The masked language model randomly masks some of the tokens from the input, and the objective is to predict the original vocabulary id of the masked word based only on its context. Unlike left-to-right language model pre-training, the MLM objective allows the representation to fuse the left and the right context, which allows us to pre-train a deep bidirectional Transformer.”
The Google AI researchers masked 15% of the words in each sequence at random. The task? To predict these masked words. Here, it is important to note that the masked words didn’t always get replaced by the masked tokens [MASK] because the [MASK] token would never appear during fine-tuning.
So, the researchers used the below technique:
- In 80% of cases, the words replaced the masked token [MASK].
- In 10% of cases, the words replaced random words
- In the remaining 10%, the words remained unchanged.
Next Sentence Prediction
Generally, language models do not capture the relationship between consecutive sentences. BERT was pre-trained on this task as well.
For language model pre-training, BERT uses pairs of sentences as its training data. The selection of sentences for each pair is quite interesting. Let’s try to understand it with the help of an example.
Imagine we have a text dataset of 100,000 sentences and we want to pre-train a BERT language model using this dataset. So, there will be 50,000 training examples or pairs of sentences as the training data.
- For 50% of the pairs, the second sentence would actually be the next sentence to the first sentence
- For the remaining 50% of the pairs, the second sentence would be a random sentence from the corpus
- The labels for the first case would be ‘IsNext’ and ‘NotNext’ for the second case
Architectures like BERT demonstrate that unsupervised learning (pre-training and fine-tuning) is going to be a key element in many language understanding systems. Low resource tasks especially can reap huge benefits from these deep bidirectional architectures.
Below is a snapshot of a few NLP tasks where BERT plays an important role:

Conclusion
In the ever-evolving landscape of Natural Language Processing (NLP), the Transformer model stands as a monumental breakthrough, fundamentally altering how we interact with textual data. From its inception to its application in Google’s BERT, the Transformer has reshaped the paradigm of language understanding. By enabling efficient handling of long-range dependencies and bidirectional context, the Transformer has revolutionized tasks ranging from machine translation to sentiment analysis. Despite its advancements, challenges like context fragmentation persist, addressed by innovations like Transformer-XL. As we navigate through this golden era of NLP, embracing these transformative architectures like BERT heralds a new era of language comprehension and model optimization.
You can also take the below course to learn or brush up your NLP skills:
Frequently Asked Questions
Q1. What is a transformer NLP?
A. A Transformer in NLP (Natural Language Processing) refers to a deep learning model architecture introduced in the paper “Attention Is All You Need.” It focuses on self-attention mechanisms to efficiently capture long-range dependencies within the input data, making it particularly suited for NLP tasks.
Q2. What are Transformers in ML?
A. In machine learning, Transformers refer to a class of neural network architectures that utilize attention mechanisms to process input data in parallel, enabling efficient computation of relationships between different parts of the input. Various domains widely use Transformers, including NLP, computer vision, and reinforcement learning.
Q3. What is a transformer neural network?
A. A Transformer neural network is a type of deep learning architecture that relies on self-attention mechanisms to process sequential data. Comprising multiple layers of encoder and decoder modules, each effectively utilizing self-attention to capture dependencies between various elements of the input sequence, the architecture is particularly adept at tasks like language modeling and machine translation.
Q4. What is a transformer in BERT?
A. In BERT (Bidirectional Encoder Representations from Transformers), a Transformer refers to the core architecture used for pre-training and fine-tuning the language model. BERT employs a multi-layer bidirectional Transformer encoder, which utilizes self-attention mechanisms to capture bidirectional contextual information from input text, enabling the model to generate high-quality representations for downstream NLP tasks.
Data Scientist at Analytics Vidhya with multidisciplinary academic background. Experienced in machine learning, NLP, graphs & networks. Passionate about learning and applying data science to solve real world problems.
Free Courses






Excellent post Prateek.
Glad you liked it!
NIce Article Explaining all things from sequence model to BERT
Thanks Ashwin!
This is awesome