Overview
- Writing optimized Python code is a crucial piece in your data science skillset
- Here are four methods to optimize your Python code (with plenty of examples!)
Introduction
I’m a programmer at heart. I’ve been doing programming since well before my university days and I continue to be amazed at the sheer number of avenues that open up using simple Python code.
But I wasn’t always efficient at it. I believe this is a trait most programmers share – especially those who are just starting out. The thrill of writing code always takes precedence over how efficient and neat it is. While this works during our college days, things are wildly different in a professional environment, especially a data science project.

Writing optimized Python code is very, very important as a data scientist. There are no two ways about it – a messy, inefficient notebook will cost you time and your project a lot of money. As experienced data scientists and professionals know, this is unacceptable when we’re working with a client.
So in this article, I draw on my years of experience in programming to list down and showcase four methods you can use to optimize Python code for your data science project.
If you’re new to the world of Python (and Data Science), I recommend going through the below resources:
What is Optimization?
Let’s first define what optimization is. And we’ll do this using an intuitive example.
Here’s our problem statement:
Suppose we are given an array where each index represents a city and the value of that index represents the distance between that city and the next city. Let’s say we have two indices and we need to calculate the total distance between those two indices. In simple terms, we need to find the total sum between any two given indices.

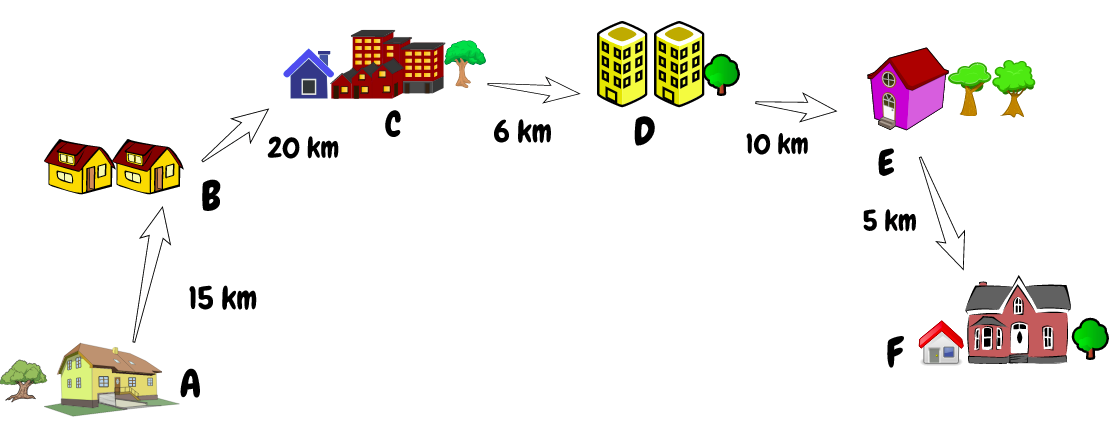
The first thought that comes to mind is that a simple FOR loop will work well here. But what if there are 100,000+ cities and we are receiving 50,000+ queries per second? Do you still think a FOR loop will give us a good enough solution for our problem?
Not really. And this is where optimizing our code works wonders.
Code optimization, in simple terms, means reducing the number of operations to execute any task while producing the correct results.
Let’s calculate the number of operations a FOR loop will take to perform this task:

We have to figure out the distance between the city with index 1 and index 3 in the above array.
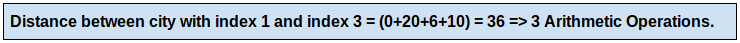
What if the array size is 100,000 and the number of queries is 50,000?

This is quite a massive number. Our FOR loop will take a lot of time if the size of the array and the number of queries are further increased. Can you think of an optimized method where we can produce the correct results while using a lesser number of solutions?
Here, I will talk about a potentially better solution to solve this problem by using the prefix array to calculate the distances. Let’s see how it works:

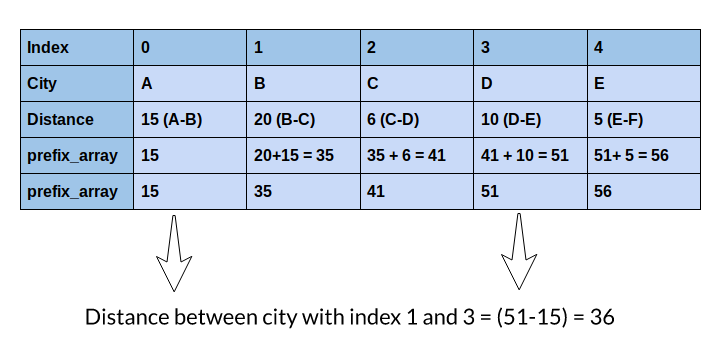

Can you understand what we did here? We got the same distance with just one operation! And the best thing about this method is that it will take just one operation to calculate the distance between any two indices, regardless of if the difference between the indices is 1 or 100,000. Isn’t that amazing?
I have created a sample dataset with an array size of 100,000 and 50,000 queries. Let’s compare the time taken by both the methods in the live coding window below.
Note: The dataset has a total of 50,000 queries and you can change the parameter execute_queries to execute any number of queries up to 50,000 and see the time taken by each method to perform the task.
import time
from tqdm import tqdm
data_file = open('sample-data.txt', 'r')
distance_between_city = data_file.readline().split()
queries = data_file.readlines()
print('SIZE OF ARRAY = ', len(distance_between_city))
print('TOTAL NUMBER OF QUERIES = ', len(queries))
data_file.close()
# assign number of queries to execute
execute_queries = 2000
print('\n\nExecuting',execute_queries,'Queries')
# FOR LOOP METHOD
# read file and store the distances and queries
start_time_for_loop = time.time()
data_file = open('sample-data.txt', 'r')
distance_between_city = data_file.readline().split()
queries = data_file.readlines()
# list to store the distances
distances_for_loop = []
# function to calculate the distance between the start index and end index
def calculateDistance(startIndex, endIndex):
distance = 0
for number in range(startIndex, endIndex+1, 1):
distance += int(distance_between_city[number])
return distance
for query in tqdm(queries[:execute_queries]):
query = query.split()
startIndex = int(query[0])
endIndex = int(query[1])
distances_for_loop.append(calculateDistance(startIndex,endIndex))
data_file.close()
# end time
end_time_for_loop = time.time()
print('\n\nTime Taken to execute task by for loop :', (end_time_for_loop-start_time_for_loop),'seconds')
# PREFIX ARRAY METHOD
# read file and store the distances and queries
start_time_for_prefix = time.time()
data_file = open('sample-data.txt', 'r')
distance_between_city = data_file.readline().split()
queries = data_file.readlines()
# list to store the distances
distances_for_prefix_array = []
# create the prefix array
prefix_array = []
prefix_array.append(int(distance_between_city[0]))
for i in range(1, 100000, 1):
prefix_array.append((int(distance_between_city[i]) + prefix_array[i-1]))
for query in tqdm(queries[:execute_queries]):
query = query.split()
startIndex = int(query[0])
endIndex = int(query[1])
if startIndex == 0:
distances_for_prefix_array.append(prefix_array[endIndex])
else:
distances_for_prefix_array.append((prefix_array[endIndex]-prefix_array[startIndex-1]))
data_file.close()
end_time_for_prefix = time.time()
print('\n\nTime Taken by Prefix Array to execute task is : ', (end_time_for_prefix-start_time_for_prefix), 'seconds')
# verify the results
correct = True
for result in range(0,execute_queries):
if distances_for_loop[result] != distances_for_prefix_array[result] :
correct = False
if correct:
print('\n\nDistance calculated by both the methods matched.')
else:
print('\n\nResults did not matched!!')This is the importance and power of optimizing your Python code. We not only save time by getting things done a lot faster, but we also save a lot of computational power too!
You might be wondering how all of this applies to data science projects. Well, you might have noticed that a lot of the time we have to execute the same query on a large number of data points. This is especially true during the data pre-processing stage.
It’s essential that we use some optimized techniques instead of basic programming to get things done as quickly and efficiently as possible. So, here I will share some of the best techniques that I use to improve and optimize my Python code.
1. Pandas.apply() – A Feature Engineering Gem
Pandas is already a highly optimized library but most of us still do not make the best use of it. Think about the common places in a data science project where you use it.
One function I can think of is Feature Engineering where we create new features using existing features. One of the most effective ways to do this is using Pandas.apply().
Here, we can pass a user-defined function and apply it to every single data point of the Pandas series. It is one of the best add-ons to the Pandas library as this function helps to segregate data according to the conditions required. We can then efficiently use it for data manipulation tasks.
Let’s use the Twitter sentiment analysis data to calculate the word count for each tweet. We will be using different methods, like the dataframe iterrows method, NumPy array, and the apply method. We’ll then compare it in the live coding window below. You can download the data set from here.
'''
Optimizing Codes - Apply Function
'''
# importing required libraries
import pandas as pd
import numpy as np
import time
import math
data = pd.read_csv('train_E6oV3lV.csv')
# print the head
print(data.head())
# calculate Number of Words using Dataframe iterrows
print('\n\nUsing Iterrows\n\n')
start_time = time.time()
data_1 = data.copy()
n_words = []
for i, row in data_1.iterrows():
n_words.append(len(row['tweet'].split()))
data_1['n_words'] = n_words
print(data_1[['id','n_words']].head())
end_time = time.time()
print('\nTime taken to calculate No. of Words by iterrows :',
(end_time-start_time),'seconds')
# Calculate Number of Words using numpy array
print('\n\nUsing Numpy Arrays\n\n')
start_time = time.time()
data_2 = data.copy()
n_words_2 = []
for row in data_2.values:
n_words_2.append(len(row[2].split()))
data_2['n_words'] = n_words_2
print(data_2[['id','n_words']].head())
end_time = time.time()
print('\nTime taken to calculate No. of Words by numpy array : ',
(end_time-start_time),'seconds')
# Calculate Number of Words by apply method:
print('\n\nUsing Apply Method\n\n')
start_time = time.time()
data_3 = data.copy()
data_3['n_words'] = data_3['tweet'].apply(lambda x : len(x.split()))
print(data_3[['id','n_words']].head())
end_time = time.time()
print('\nTime taken to calculate No. of Words by Apply Method : ',
(end_time-start_time),'seconds')
You might have noticed that the apply function is much faster than the iterrows function. Its performance is comparable to the NumPy array but the apply function provides much more flexibility. You can read more about its documentation here.
2. Pandas.DataFrame.loc – A Brilliant Hack for Data Manipulation in Python
This is one of my favorite hacks of the Pandas library. I feel this is a must-know method for data scientists who deal with data manipulation tasks (so almost everyone then!).
Most of the time we are required to update only some values of a particular column in a dataset based upon some condition. Pandas.DataFrame.loc gives us the most optimized solution for these kinds of problems.
Let’s solve a problem using this loc function. You can download the dataset we’ll be using here.
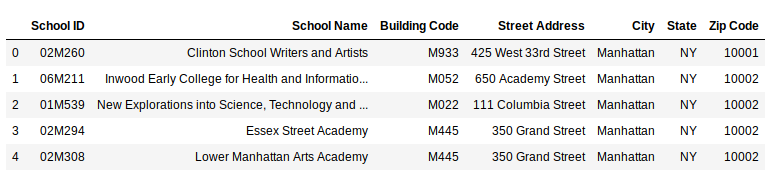
Check the value counts of the ‘City’ variable:
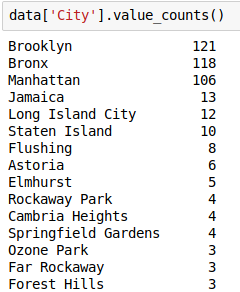
Now, let’s say we want only the top 5 cities and want to replace the rest of the cities as ‘Others’. So let’s do that:

See how easy it was to update the values? This is the most optimized way to solve a data manipulation task of this kind.
3. Vectorize your Functions in Python
Another way to get rid of slow loops is by vectorizing the function. This means that a newly created function will be applied on a list of inputs and will return an array of results. Vectorizing in Python can speed up your computation by at least two iterations.
Let’s verify this in the live coding window below on the same Twitter Sentiment Analysis Dataset.
Incredible, right? For the above example, vectorization is 80 times faster! This not only helps to speed up our code but also makes it cleaner.
4. Multiprocessing in Python
Multiprocessing is the ability of a system to support more than one processor at the same time.
Here, we break our process into multiple tasks and all of them run independently. Even the apply function looks slow when we are working with huge datasets.
So, let’s see how can we make use of the multiprocessing library in Python and speed things up.
We will create one million points at random and calculate the number of divisors for each point. We will compare its performance using both the apply function and the multiprocessing method:



Here, multiprocessing generates the output 13 times faster than the apply method. The performance might vary with different hardware systems but it will definitely improve the performance.
End Notes
This is by no means an exhaustive list. There are many other methods and techniques to optimize Python code. But I’ve found and used these four a LOT during my data science career and I believe you’ll find them useful too.
Are there any other methods you use to optimize your code? Do share those with us and the community in the comments section below!
And as I mentioned earlier, you should check out our popular courses if you’re new to Python and data science:
Ideas have always excited me. The fact that we could dream of something and bring it to reality fascinates me. Computer Science provides me a window to do exactly that. I love programming and use it to solve problems and a beginner in the field of Data Science.






Too good