Overview
- Presenting the top five winning solutions and approaches from the AmExpert 2019 hackathon
- The problem statement was from the retail industry and geared towards predicting customer behaviour
- These five winning solutions have one common theme that won them this retail hackathon – read on to find out what it was!
Introduction
If I had to pick the top five industries where data science is making the biggest impact, retail would definitely make that list every time. I’m in awe of the wide variety of challenges and solutions these data science teams are solving around the globe.
The vast amount of data that this industry generates has given rise to multiple use cases for data science which are being harnessed successfully by big retailers like Tesco, Target, Walmart, etc. Just check out a few common data science use cases in the retail industry:
- Recommendation Engines
- Market Basket Analysis
- Price Optimization
- Inventory Management
- Customer Sentiment Analysis, and much more
One of the most widely used sales strategies in retail is promotions. More and more innovative offers & discounts are being offered by retailers as the competition is hotting up. Companies are increasingly relying on data-driven promotional strategies to derive maximum ROI.

I’m sure you’ve participated in quite a lot of promotions by these retailers (you know which ones I’m talking about!). Discount marketing and coupons are perhaps the two most commonly used promotional techniques to attract new customers and to retain & reinforce loyalty among existing customers.
So you can imagine how valuable it would be to measure a consumer’s propensity to use a coupon or to even predict redemption behaviour. These are crucial parameters in assessing the effectiveness of a marketing campaign.
In collaboration with our Hackathon Partner and Sponsor for DataHack Summit 2019 – American Express, we conceptualized and designed a problem statement related to coupon redemption prediction using historical redemption data and customer transactions.
It was amazing to see the intense competition and engagement among some of the world’s best data scientists. Our team was overwhelmed with the response and the kind testimonials from new users as well as a lot of old-timers. Here are some of the top ones:
“I would like to thank AV for organizing a great hackathon. This was probably one of the most interesting hackathons this year.” – Sahil Verma
“A fantastic competition with regards to feature engineering, enjoyed it a lot.” – Bishwarup
“Thank you Analytics Vidhya and American Express for this amazing competition.” – Mudit Tiwari
It was an exciting week for both our team and all the participants in the competition with more than 1000 participants glued to their machines trying different techniques and creating new features to cross that 0.9 AUC-ROC mark. Let’s look at the top five winning solutions and approaches in this article.
About the AmExpert 2019 Hackathon
AmExpert 2019 was one of the biggest hackathons ever hosted by Analytics Vidhya. Just check out these amazing numbers and the prizes that were on offer:
- Total Registrations: 5,991
- Total Submissions: 14,861
- Prize Money: MacBook, iPad Mini, Smartwatches & Interview Opportunities!
It was a memorable and tightly contested 9-day hackathon with a variety of data scientists and data science professionals participating from all over the country.

Problem Statement for the AmExpert 2019 Hackathon: Predicting Coupon Redemption
Let’s understand the problem statement behind this hackathon. I have hinted at it in the introduction earlier but let me expand on that here.
The XYZ Credit Card company regularly helps its merchants understand their data better and take key business decisions accurately by providing machine learning and analytics consulting. ABC is an established Brick & Mortar retailer that frequently conducts marketing campaigns for its diverse product range.
ABC have sought XYZ to assist them in their discount marketing process using the power of machine learning. Can you wear the AmExpert hat and help out ABC?
ABC’s promotions are shared across various channels including email, notifications, etc. A number of these campaigns include coupon discounts that are offered for a specific product/range of products. The retailer would like the ability to predict whether customers redeem the coupons received across channels, which will enable the retailer’s marketing team to accurately design coupon construct, and develop more precise and targeted marketing strategies.
The data available in this problem contains the below information, including the details of a sample of campaigns and coupons used in previous campaigns:
- User demographic details
- Campaign and coupon details
- Product details
- Previous transactions
Based on previous transaction & performance data from the last 18 campaigns, the participants were asked to predict the probability of a coupon being redeemed for the next 10 campaigns in the test set for each coupon and customer combination. A really fascinating challenge!
Dataset Description
Below is the schema for the different data tables available:
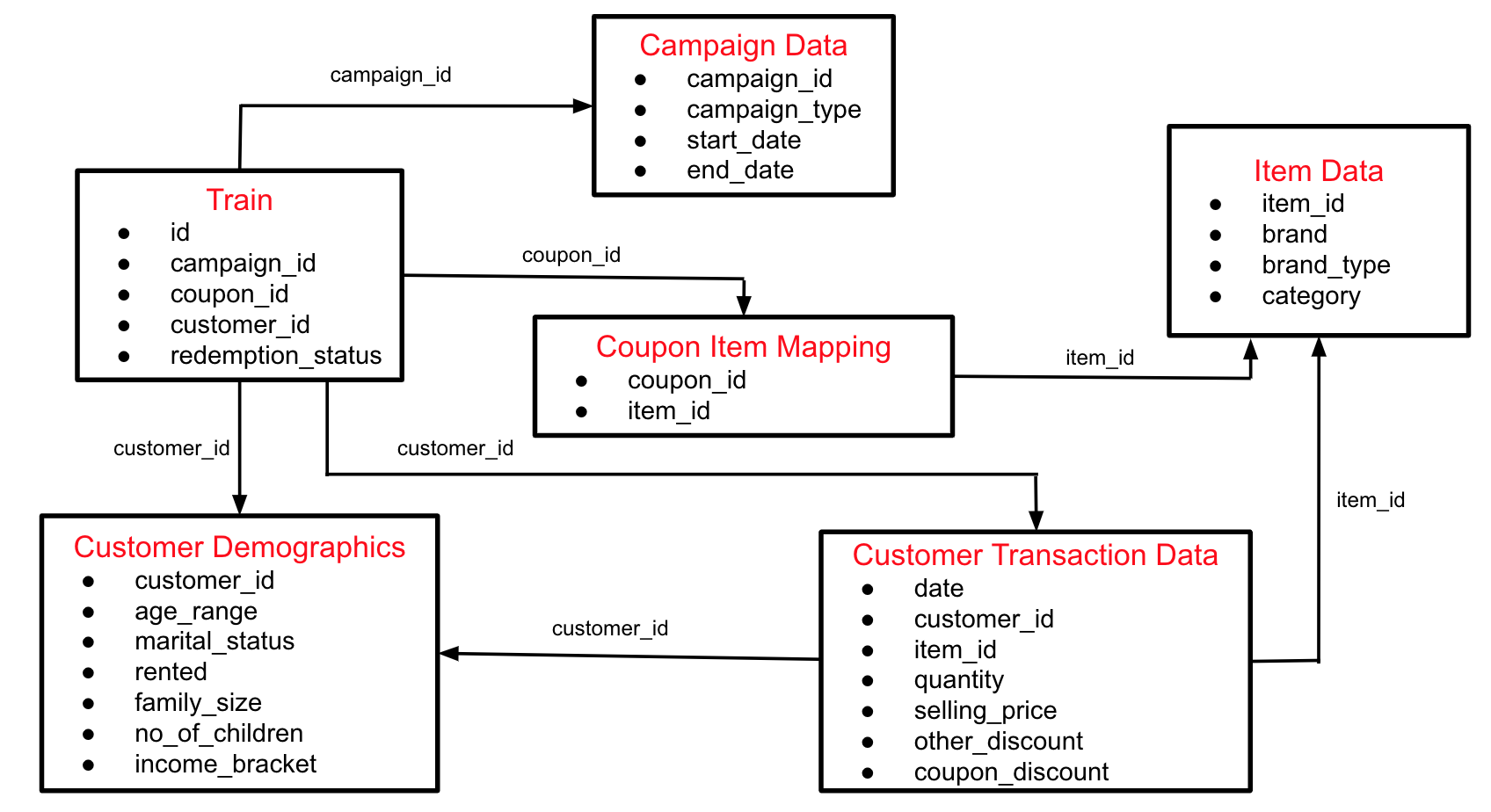
The participants were provided with the following files in the train.zip file:
- Train: Train data containing the coupons offered to the given customers under the 18 campaigns
- Campaign Data: Campaign information for each of the 28 campaigns
- Coupon Item Mapping: Mapping of coupon and items valid for discount under that coupon
- Customer Demographics: Customer demographic information for some customers
- Customer Transaction Data: Transaction data for all customers for the duration of campaigns in the train data
- Item Data: Item information for each item sold by the retailer
- Test: Contains the coupon customer combination for which redemption status was to be predicted
To summarize the entire process:
- Customers receive coupons under various campaigns and may choose to redeem them
- They can redeem the given coupon for any valid product for that coupon as per coupon item mapping within the duration between the campaign start date and end date
- Next, the customer will redeem the coupon for an item at the retailer store and that will reflect in the transaction table in the column coupon_discount
Evaluation Metric
Submissions were evaluated on the area under the ROC curve metric between the predicted probability and the observed target.
Winners of the AmExpert 2019 Hackathon
Participating in a hackathon is the first step. But winning it, or even finishing in the top echelons of the leaderboard, is quite a herculean task. I have personally participated in tons of hackathons and can vouch for the level of difficulty and ingenuity it takes to top the leaderboard.
So, hats off to the winners of the AmExpert 2019 hackathon. Before we go through their winning approaches, let’s congratulate the winners:
- Rank 1: Sourabh Jha
- Rank 2: Mohsin Khan aka Tezdhar
- Rank 3: Sahil Verma
- Rank 4: Pradeep Pathak
- Rank 5: Mudit Tiwari
You can check out the final rankings of all the participants on the hackathon leaderboard.
The top five finishers have shared their detailed approach from the competition. I am sure you are eager to know their secrets so let’s begin.
Note: All the approaches we’ve provided below are in the winners’ own words.
Rank 5: Mudit Tiwari
“My major focus in this competition was on feature engineering.”
- Since there were 5-6 tables to join, I decided to take juices from all the tables to make feature-rich datasets. I made 4 kinds of datasets upon the aggregation of transaction data that captured customer, item as well as coupon behaviour. I tested and finalized my validation strategy. I tried with Group k-fold and normal k-fold and got better results with the latter. Upon development of datasets, I finalized 6 models. These 6 models were then used for stacking and ensembling, giving approximately 96.2 CV and ~94.46 on the public leaderboard
- Feature Engineering:
- I found the most interesting table to be the Customer Transaction Table. Aggregation of Customer Transaction table indeed helped in my model’s performance
- Proper usage of transaction data was required to leave behind the possibilities of any leakage (I used the transaction data for aggregation only till the start date of every campaign ID)
- I made many new logical features in transaction data, such as total discount, discount percentage, etc.
- I performed various aggregations corresponding to different numerical (mean, min, max, standard deviation, etc.) as well as categorical features (modes, nunique, etc.)
- Every coupon contained few item ids. So, I decided to look at the number of items purchased by every customer corresponding to every campaign. Eventually, this feature came out to be the most important one
- Using the idea from the last point, I made two different sets of variables:
- For every campaign & coupon ID, go to the respective transaction table and look for trends in the item (called as an item-level aggregation)
- For every campaign & coupon ID, look at the coupon’s past trends, like the number of unique customers under this coupon from transaction table, or their similar trends (called as a coupon-level aggregation)
- After an initial round of model development, I came to know that coupon-level aggregations were not as important as item-level aggregations
- This diverse variety of variables and trends was captured from transaction data along with other tables. I was able to create 4 different & diverse datasets upon merging them
“I decided to go with 3 different boosting techniques – CatBoost, LightGBM and XGBoost.”
- Final Model: Different datasets along with a bunch of different varieties of models gave me a good idea about the modelling process. I used k-fold and also tried with group k-fold, but OOT results with k-fold were better. Boosting was working fine while bagging (random forest) was not giving par results. I decided to go with 3 different boosting techniques – CatBoost, LightGBM and XGBoost. I performed repeated experiments on these three models and the 4 datasets and chose 6 models after manual parameter tuning and feature selection. I have provided the overall schematic flow diagram below. Among the final six models, all but one XGBoost model was used for two types of stacking – one with simple Logistic Regression and the other with artificial neural network
- Check out the solution here

Rank 4: Pradeep Pathak
“I created a dataset with around 124 features, built different models and took ensemble mean of predictions from all the models as the final submission. Having a reliable cross validation strategy was the key to finishing top in the competition.”
- Feature Engineering:
- As the problem statement was to predict whether the user would redeem the coupon or not depending on past transactions, features created from them (historical transactions) turned out to be really important
- The key here was to also subset the transactions to avoid leakage. So, for each row, I used only the transactions before the start date to create features for the same
- I created aggregation features for the below-mentioned groups. The idea was to create valuable features at a different level and angle that could lead to customers redeeming the coupon:
- Customer and StartDate Group
- Coupon and StartDate Group
- Customer, Coupon and StartDate Group
- Daily-level aggregation for Customer and Coupons was also used
- Brands (extracted from the Coupon) and StartDate Group
- I also tried many other levels of aggregated features with the same intuition but they didn’t turn out to be useful so I dropped them in the final dataset
- Creating features without any leakage was key to finishing top in the competition
- Final Model: Mean predictions from LightGBM, XGBoost and CatBoost models on a dataset with around 124 features
- Key Takeaways: Creating valuable features was the key to finishing top in the competition. Avoiding leakage in the feature when using historical data was important for models to not overfit
- Check out the solution here
Rank 3: Sahil Verma
“The crux of the problem lay in creating features such that you don’t introduce leaks in them. Most of the participants were struggling with this.”
- Feature Engineering:
- For a given customer coupon pair, the aim was to find all the items for that coupon and find the propensity of the customer to buy that product using past transactions. We can apply similar logic at a brand and category level. Apart from propensity, we can also calculate a bunch of other variables, for example, what is the total amount spent, total discount availed, etc.
- Apart from the customer coupon level, I tried similar approaches at only coupon and only campaign levels. For example, what is the probability that items under one coupon code use a coupon discount? We can get this by filtering historical transactions for the items belonging to one coupon
- To avoid leakage, it was important to filter the historical data prior to the campaign date at row-level
- These variables were the most powerful ones for this problem and I got a clue from reading the problem statement page multiple times. If you had read the last four lines of the problem statement, wherein the entire process was described in the points, the ideas would have clicked!
- Final Model: My final model was a linear blend of Catboost, LightGBM and XGBoost built over two datasets. The only difference between the two datasets was the number of features each had (hence, one had more statistics being calculated from the historical data)
- Key Takeaways: Feature Creation is the key. Read the problem statement multiple times (I got the idea of features from here). Try and avoid leakage, people generally feel rising on the public leaderboard is good but it will bite back. Try to build a robust validation strategy
- Check out the solution here
Rank 2: Mohsin Khan aka Tezdhar
- Observations:
- I initially looked at the campaign dates which suggested train and test campaigns were split in time. So, I decided to use the last three campaigns (sorted by campaign start date) from train data as validation data
- Another important thing was to observe how the problem was set. For each campaign, there were certain coupons. We would want to know, given a set of customers, which coupons they would redeem. The standard way to treat this would be to convert it into a classification problem which can be done by pairing all customers in the dataset with all coupons
- Suppose there are N customers and M coupons – this would lead to N*M rows. This would lead to a large number of rows even for a small number of N and M. So, to efficiently solve this problem, we needed to resample the rows (one way would be to sample rows in the train data where a user didn’t redeem a coupon, so that the dataset became slightly more balanced). It can be observed that for each customer, the average number of coupons is around 16-20
- In this context, it was highly likely that a customer would interact with at least one coupon from the ones paired with him. So, the first thing we needed to do is get the ranking of coupons for each customer. Further, we can rank customers based on their propensity to redeem coupons (based on customers train data)
- Now, the important question – how do you rank coupons for a customer? Well, we have customer transactions, wherein we know which items customers generally redeem coupons on. If a coupon paired with a customer has more of those items, it is likely that he/she will redeem that particular coupon
- So let’s rank (customer, coupon) pairs based on items common with his/her historically transacted items. Similarly, we can also rank customers by their ‘coupon redemption mean’ in the train data
- Check out the solution here
Rank 1: Sourabh Jha
“Local cross-validation was a bit difficult to trust and avoiding any sort of leakage was key to getting a good score.”
- Feature Engineering:
- I created 300+ features including aggregate features for customer and coupon. I also created a coupon pair from the customer transaction data for each campaign by using the subset of transaction data before the given campaign
- I created multiple latent vectors for customer and coupon using singular value decomposition (SVD) and different time-weighted tf-idf matrices. For example, (customer X item), (customer X brand), (customer X coupon), etc.
- I also calculated Category and Brand type-wise total spend, total saving, coupon savings and transaction counts
- I created 5-fold cross-validation by randomly splitting the data based on IDs
- Final Model: I used the LightGBM algorithm to train the models
- System Configuration: 16GB RAM, 4 Cores
- Key Takeaways: Local cross-validation was a bit difficult to trust and avoiding any sort of leakage was key to getting a good score. Since the transaction data was provided at item and brand level, using latent features helped me abstract these features and use at customer and coupon level. I also used permutation feature importance to make sure only good features remained in the final model. This helped reduce the feature set from 300+ to 107 features
- Check out the solution here
End Notes
The most important takeaways from the contest were defining the correct cross-validation strategy, proper exploration of the data, and feature engineering. I think there are no surprises here as these are some of the things which are repeatedly being mentioned by the winners in each hackathon. However, a lot of beginners also got a taste of working on multiple table data and acquired skills in creating aggregated features from historical data.
I encourage you to head over to the DataHack platform TODAY and participate in the ongoing hackathons. You can also try out the wide variety of practice problems we have there and hone your skills.
If you have any questions, feel free to post them in the comments section below.
IIT Bombay Graduate with a Masters and Bachelors in Electrical Engineering. I have previously worked as a lead decision scientist for Indian National Congress deploying statistical models (Segmentation, K-Nearest Neighbours) to help party leadership/Team make data-driven decisions. My interest lies in putting data in heart of business for data-driven decision making.






Have the winners used some kind of AutoML at some stage or is all the feature generation manual?
Have the winners used some kind of autoML for feature generation or is it manual or a combination of them?
Is the data set available for practicing?