Overview
- Neural fake news (fake news generated by AI) can be a huge issue for our society
- This article discusses different Natural Language Processing methods to develop robust defense against Neural Fake News, including using the GPT-2 detector model and Grover (AllenNLP)
- Every data science professional should be aware of what neural fake news is and how to combat it
Introduction
Fake news is a major concern in our society right now. It has gone hand-in-hand with the rise of the data-driven era – not a coincidence when you consider the sheer volume of data we are generating every second!
Fake news is such a widespread issue that even the world’s leading dictionaries are trying to combat it in their own way. Here are two leading lights in that space taking a stance in recent years:
- Dictionary.com listed ‘misinformation’ as their Word of the Year in 2018
- Oxford Dictionary picked ‘post-truth’ as their Word of the Year a few years ago

So what role has Machine Learning played in this? I’m sure you must have heard about a machine learning technique that generates fake videos mimicking famous personalities. Similarly, Natural Language Processing (NLP ) techniques are being used to generate fake articles – a concept called “Neural Fake News”.
I’ve been working in the Natural Language Processing (NLP) space for the last few years and while I love the pace at which breakthroughs are happening, I’m also deeply concerned about the way these NLP frameworks are being used to create and spread false information.
Advanced pre-trained NLP models like BERT, GPT-2, XLNet, etc. are easily available for anyone to download and play around with. This aggravates the risk of them being exploited for spreading propaganda and chaos in society.
In this article, I will be taking a comprehensive look at Neural Fake News – from defining what it is, to understanding certain ways of identifying such misinformation. We’ll also learn in detail about the internal workings of these State-of-the-Art language models themselves.
Table of Contents
- What is Neural Fake News?
- How can Large Language Models be Misused to Generate Neural Fake News?
- How to Detect Neural Fake News?
- Fact-Checking
- Statistical Analysis using GLTR (HarvardNLP)
- Using a Model to Detect Neural Fake News
- GPT-2 Detector Model
- Grover (AllenNLP)
- Limitations of Current Detection Techniques and Future Directions of Research
What is Neural Fake News?
I’m sure you’ve heard the term “Fake News” recently. It’s almost ubiquitously used on every social media platform. It has become synonymous with the menace in society and politics in recent years. But what is Fake News?
Here is Wikipedia’s definition:
“Fake news (also known as junk news, pseudo-news, or hoax news) is a form of news consisting of deliberate disinformation or hoaxes spread via traditional news media (print and broadcast) or online social media.”
Fake News is any news that is either factually wrong, misrepresents the facts, and that spreads virally (or maybe to a targeted audience). It can be spread both through regular news mediums or on social media platforms like Facebook, Twitter, WhatsApp, etc.
What truly differentiates Fake News from simple hoaxes like “Moon landing was fake”, etc. is the fact that it carefully mimics the “style” and “patterns” that real news usually follows. That’s what makes it so hard to distinguish for the untrained human eye.
Additionally, it is interesting to note that Fake News has been around for a long, long time (throughout our history, actually).
Neural Fake News
Neural Fake News is any piece of fake news that has been generated using a Neural Network based model. Or to define it more formally:
Neural fake news is targeted propaganda that closely mimics the style of real news generated by a neural network.
Here is an example of Neural Fake News generated by OpenAI’s GPT-2 model:

The “system prompt” is the input that was given to the model by a human and the “model completion” is the text that the GPT-2 model came up with.
Did you intuitively guess that the latter part was written by a machine? Notice how connivingly the model is able to extend the prompt into a coherent piece of the story that looks incredibly convincing on first look.
Now, what if I tell you that the GPT-2 model is freely available for anyone to download and run? This is exactly what concerns the research community and the reason I decided to write this article.
How can Large Language Models be Misused to Generate Neural Fake News?
Language Modeling is an NLP technique where models learn to predict either the next word or a missing word in a sentence by understanding the context from the sentence itself. Take Google Search for example:

This is an example of a language model in action. By making the model predict either the next word in a sentence or a missing word, we make the model learn the intricacies of the language itself.
The model is able to understand how the grammar works, the different writing styles, etc. And that’s how the model is able to generate a piece of text that appears credible to the untrained eye. The issue happens when these very same models are used to generate targeted propaganda to confuse people.
Here are some incredibly powerful state-of-the-art language models that are really good at generating text.
1. BERT by Google
BERT is a language model designed by Google that broke state-of-the-art records. This framework is the reason behind the recent spurt in training and researching large language models by various research labs and companies.
BERT and its counterparts like RoBERTa by Facebook, XLM, XLNet, DistilBERT etc. have performed extremely well on the task of generating text.
2. GPT-2 Models by OpenAI
The series of language models from OpenAI like GPT, GPT-2, and GPT-Large have created a sensation in the media for their text generation abilities. These are some of the language models we should definitely know about.
3. Grover by AllenNLP
Grover is an interesting new language model by AllenNLP that has shown great ability to not only generate text but also identify the fake text generated by other models.
We will be learning more about Grover later in the article.
How to Detect Neural Fake News?
How can we detect or figure out if a piece of news is fake? Currently, there are three primary ways of dealing with Neural Fake News that have shown good results.
I. Fact-Checking
What’s the most basic way of checking whether a piece of news that’s spreading online is fake or genuine? We can simply Google it, refer to trustworthy news websites, and fact-check whether they have the same or similar story.

Even though this step feels like common sense, it is actually one of the most effective ways of being sure about the genuineness of a piece of news.
But this step deals with only one kind of fake news: the one that isn’t viral or is from a single source. What if we want to deal with the news that has gone viral and is churned out by the media all around us?
This is usually the kind of news generated by a neural network because the news looks so convincingly similar in “style” and “structure” to real news.
Let’s learn some ways to deal with “machine-generated” text.
II. Statistical Analysis using GLTR (HarvardNLP)
Giant Language model Test Room or GLTR is a tool designed by the great folks at HarvardNLP and the MIT-IBM Watson lab.
The main approach GLTR uses to identify machine-generated text is through a neat combination of statistical analysis and visualizations that are made for a given piece of text.
Here is how the GLTR interface looks:

GLTR’s central idea to detect generated text is to use the same (or similar) model that was used to generate that piece of text in the first place.
The simple reason for this is that the words that a language model generates directly come from the probability distribution that it has learnt from the training data itself.
Here is an illustrative example, notice how the language model generated a probability distribution as output having different probabilities for all the possible words:

And since we already know the techniques that are used to sample words from a given probability distribution like max sampling, k-max sampling, beam search, nucleus sampling etc. we can easily cross-check whether a word in a given text follows a particular distribution.
And if it does, and there are multiple such words in the given text, then that will essentially confirm that it’s machine-generated.
Let’s run GLTR on an example to understand this concept!
Installing GLTR
Before we can use GLTR, we need to install it on our system. Start by cloning the GitHub repository of the project:
git clone https://github.com/HendrikStrobelt/detecting-fake-text.git
Once you have cloned the repository, cd into it and do pip install:
cd detecting-fake-text && pip install -r requirements.txt
Next, download the pre-trained language model. You can do it by running the server:
python server.py
GLTR currently supports two models – BERT and GPT-2. You can choose between the two; if no option is given then GPT-2 is used:
python server.py --model BERT
This will start downloading the respective pre-trained model on your machine. Give it some time if you have a slow internet connection.
When everything is ready, the server will start at port 5001 and you can directly go to http://localhost:5001 to access it:

How does GLTR work?
Let’s say we have the following piece of text. We want to check whether it is generated by a language model like GPT-2:
How much wood would a woodchuck chuck if a woodchuck could chuck wood?
GLTR will take this input and analyze what GPT-2 would have predicted for each position of the input.
Remember, the output of a language model is a ranking of all the words that the model knows. Hence, we will quickly be able to see what rank each word of the input text holds according to GPT-2.
And if we color-code each word based on the fact whether it’s rank was in top-10 as green, top-100 as yellow and top-1000 as red, we will get this output:
![]()
Now, we can visually see just how probable each word was according to GPT-2. The greens and yellows are highly probable while the red ones are unexpected words according to the model, meaning they were most likely written by a human. This is exactly what you’ll see on the GLTR interface!
And if you need more information, you can hover over a word like “wood”. You will see a small box with the top 5 predicted words for this position and their probabilities:

I urge you to try different texts both human-generated and machine-generated with GLTR at this point. A few samples are already provided in the tool itself:

You will notice that the number of red and purple words, i.e. unlikely or rare predictions, increases when you move to the real texts.
Additionally, GLTR shows three different histograms with aggregated information over the whole text (check out the image below for reference):
- The first one shows how many words of each category (top 10, top 100 and top 1000) appear in the text
- The second one illustrates the ratio between the probabilities of the top predicted word and the following word
- The third histogram displays the distribution over the entropies of the predictions. A low uncertainty means that the model was very confident of each prediction, whereas a high uncertainty implies low confidence
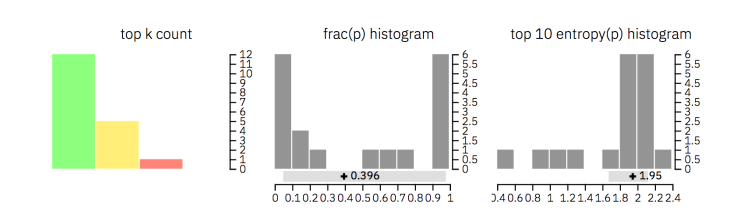
Here is how these histograms help:
- The first two histograms help understand whether the words in the input text are sampled from the top of the distribution (which will be true for a machine-generated text)
- The last histogram illustrates whether the context of words is well-known to the detection system because of which it is (very) sure of its next prediction
Smart, right? By combining these multiple visualizations and the knowledge of probability distributions, the GLTR model can be used as an effective forensic tool to understand and identify machine-generated text.
Here is what the authors reported about the success of GLTR:
“In a human-subjects study, we show that the annotation scheme provided by GLTR improves the human detection-rate of fake text from 54% to 72% without any prior training.” – Gehrmann et. al
You can read more about GLTR in the original research paper.
III. Using a Model to detect Neural Fake News
GLTR is pretty impressive as it uses simple knowledge of probability distributions and visualizations to detect Neural Fake News. But what if we can do better?
What if we can train a large model to predict whether a piece of text is Neural Fake News or not?
Well, that’s exactly what we will be learning in this section!
a) GPT-2 Detector Model
The GPT-2 detector model is a RoBERTa (a variant of BERT) model that has been fine-tuned to predict whether a given piece of text has been generated by using GPT-2 or not (as a simple classification problem).
RoBERTa is a large language model developed by Facebook AI Research as an improvement over Google’s BERT. That’s why there are large similarities between the two frameworks.
An interesting point to note here is that even though the model architecture of RoBERTa is very different from that of GPT-2 as the former is a masked language model (like BERT) that is not generative in nature unlike GPT-2; it has still shown around 95% accuracy in identifying Neural Fake News generated by it.
Another good thing about this model is that it’s incredibly fast in making predictions as compared to other methods that we are discussing in this article.
Let’s see it in action!
Installing the GPT-2 Detector Model
The installation steps for this detector model are quite straightforward, just like GLTR.
We first need to clone the repository:
git clone https://github.com/openai/gpt-2-output-dataset.git
Again, cd into it and do pip install:
cd gpt-2-output-dataset/ && pip install -r requirements.txt
Next, we need to download the pre-trained language model. Do this by running the below command:
wget https://storage.googleapis.com/gpt-2/detector-models/v1/detector-base.pt
This step might take some time. Once it’s done, you can start the detector:
python -m detector.server detector-base.pt --port 8000
When everything is ready, the server will start at port 8000 and you can directly go to http://localhost:8000 to access it!

With this, you are ready to try out the GPT-2 detector model!
Identifying Neural Fake News
The interface of the detector model is very straightforward. We just copy-paste a piece of text and it will tell us whether it is “Real” or “Fake” depending on whether it was generated by a machine (GPT-2 model) or not.
Here is a text that I generated from GPT-2 using the Transformers 2.0 library:

As you can see, even though the text looks pretty convincing and coherent, the model straightaway classified it as “Fake” with a 99.97% accuracy.
This is a very fun tool to use and I suggest you go ahead and try different examples of generated and non-generated text to see how it performs!
In my case, I generally noticed that this model only works well in identifying text generated by the GPT-2 model. This is quite unlike Grover, another framework that we will be learning about in the next section. Grover can identify text generated by a variety of Language Models.
You can read more about RoBERTa’s architecture and training methods on Facebook’s blog post about it. And if you are curious about how the detector model is implemented, you can check the code on GitHub.
b) Grover (AllenNLP)
Grover by AllenNLP is my favorite tool out of all the options that we have discussed in this article. It is able to identify a piece of text as fake that has been generated by a plethora of Language Models of multiple kinds, unlike GLTR and GPT-2 detector models that were limited to particular models.
According to the authors, the best way to detect a piece of text as neural fake news is to use a model that itself is a generator that can generate such text. In their own words:
“The generator is most familiar with its own habits, quirks, and traits, as well as those from similar AI models, especially those trained on similar data, i.e. publicly available news.” – Zellers et. al
Sounds counterintuitive at first sight, doesn’t it? In order to create a model that can detect neural fake news, they went ahead and developed a model that is really good at generating such fake news in the first place!
As crazy as it sounds, there is a scientific logic behind it.
So how does Grover work?
Problem Definition
Grover defines the task of detecting neural fake news as an adversarial game with two models as players. This is what it means:
- There are two models in the setup to detect generated text
- The adversarial model’s goal is to generate fake news that can be viral or is persuasive enough to both humans and to the verifier model
- The verifier classifies whether a given text is real or fake:

- The training data for the verifier consists of unlimited real news stories, but only a few fake news stories from a specific adversary
- This is done to replicate the real-world scenario, where the amount of fake news that is available from an adversary is fairly less as compared to real news
The dual objectives of these two models mean that the attackers and defenders are “competing” between themselves to both generate fake news and also detect it at the same time. As the verifier model gets better, so does the adversarial model.
Conditional Generation of Neural Fake News
One of the most evident properties of neural Fake News is that it’s usually “targeted” content like clickbait or propaganda. Most language models like BERT, etc. do not let us create controlled generations. Welcome – Grover.
Grover supports “controlled” text generation. This simply means that apart from the input text to the model, we can provide additional parameters during the generation phase. These parameters will then guide the model to generate specific text.
But what are those parameters? Consider news articles – what are the structural parameters that help define a news article? Here are some parameters that Grover’s authors deem necessary for generating an article:
- Domain: Where the article is published, which indirectly affects the style
- Date: Date of publication
- Authors: Names of authors
- Headline: Headline of the article, this affects the generation of the body
- Body: The body of the article
Combining all these parameters, we can model an article by the joint probability distribution:

Now, I won’t be going too much into the underlying mathematics of how this is implemented as that is beyond the scope of this article. But just to give you an idea of how the entire generation process looks like, here is an illustrative diagram:

Here is what is happening:
- In row a), the body is generated from partial context (the author’s field is missing)
- In b), the model generates the authors
- And in c), the model uses the new generations to regenerate the provided headline to a more realistic one
Architecture and Dataset
Grover uses the same architecture as GPT2:
- There are three model sizes. The smallest model, Grover-Base, has 12 layers and 124 million parameters, on par with GPT and BERT-Base
- The next model, Grover-Large, has 24 layers and 355 million parameters, on par with BERT-Large
- And the largest model, Grover-Mega, has 48 layers and 1.5 billion parameters, on par with GPT2
The RealNews dataset that has been used to train Grover is created by the authors of Grover themselves. The dataset and the code to create it has been open-sourced so you can either download it and use it as it is or generate your own dataset following Grover’s specifications.
Installing Grover
You can follow the Installation Instructions to install Grover and run it’s generator and detector tool on your own machine. Keep in mind that the size of the model is HUGE (46.2G compressed!) so installing it on your system could be a challenge.
That’s why we will be using the online detector and generator tool that is available.
Using Grover for Generation and Detection
You can access the tool at this link:
https://grover.allenai.org/

You can play around with the Generate option and see how well Grover is able to generate Neural Fake News. Since we are interested in checking the detection ability of Grover, let’s head to the “Detect” tab (or go to the following link):
https://grover.allenai.org/detect
Case Study 1:
The piece of text we want to test is the same GPT-2 generated text that we saw earlier:
When you click on the “Detect Fake News” button, you will notice that Grover very easily identified this as machine-generated:

Case Study 2:
The next article that we’ll test is from the New York Times:
And you’ll see that Grover is indeed able to identify it as written by a human:

Case Study 3:
These were easy examples. What if I give it a technical piece of text? Like an explanation from one of the articles at Analytics Vidhya?
For the above text, Grover fails as it is not trained on these kinds of technical articles:
But it’s here that the GPT-2 detector model shines since it’s trained on a wide variety of webpages (8 million!).

This just goes to show that no tool is perfect and you will have to choose which one to use based on the kind of generated text you are trying to detect.
Case Study 4:
Her’s the last experiment we will do. We will test machine-generated news that is not “fake” but just an example of automated news generation. This post is taken from The Washington Post that generates automated score updates using a program:
Now, the interesting thing here is that the GPT-2 detector model says that it isn’t machine-generated news at all:

But at the same time, Grover is able to identify that it is machine written text with a slightly low probability (but still, it does figure it out!):

Now, whether you consider this as “fake” news or not, the fact is that it’s generated by a machine. How you will classify this category of text will be based on what your goals are and what your project is trying to achieve.
In short, the best way for detecting neural fake news is to use a combination of all these tools and reach a comparative conclusion.
Limitations of Current Fake News Detection Techniques and Future Research Direction
It is conspicuous that current detection techniques aren’t perfect and they have room to grow. MIT’s Computer Science & Artificial Intelligence Laboratory (CSAIL) recently conducted a study on existing methods to detect neural fake news and some of their findings are eye-opening.
Limitations of existing techniques to detect Neural Fake News
The main upshot of the study is that the existing approach that methods like GLTR, Grover etc. use to detect neural fake news is incomplete.
This is because just finding whether a piece of text is “machine-generated” or not is not enough, there can be a legitimate piece of news that’s machine-generated with the help of tools like auto-completion, text summarization etc.
For example, the famous writing app Grammarly uses some form of GPT-2 to help correct grammatical mistakes in the text.
Another example of such a case is case study #4 from the previous section of this article, where a program was used to automatically generate sport updates by the Washington Post.
Vice-versa, there can be human written text that is slightly corrupted/modified by the attackers which will be classified as not being neural fake news by the existing methods.
Here is an illustration that summarizes the above dilemma of the detector model:

You can clearly notice in the above figure that since the feature space of generated neural fake news and real news is very far, it’s incredibly easy for a model to classify which one is fake.
Additionally, when the model has to classify between true generated news and neural fake news like as in case study #4 that we saw previously the model isn’t able to detect as the feature space is very close for the two.
The same behavior is seen when the model has to differentiate between actual human-written news and the same news that’s modified a bit and is now fake.
I wouldn’t get into specifics but the authors conducted multiple experiments to come to these conclusions, you can read their very interesting paper to know more.
These outcomes made the authors conclude that in order to define/detect neural fake news we have to consider the veracity (truthfulness) rather than provenance (source, whether machine-written or human-written).
And that I think is an eye-opening revelation that we came to.
What can be the Future Directions of Research
One step in the direction of dealing with the issue of neural fake news was when Cambridge University and Amazon released FEVER last year, which is the world’s largest dataset for fact-checking and can be used to train neural networks to detect fake news.

Although when FEVER was analyzed by the same MIT team (Schuster et. al), they found that the FEVER dataset has certain biases in it that makes it easier for a neural network to detect fake text by just using patterns in the text. When they corrected some of these biases in the dataset, they saw that the accuracy of the models plunged as expected.
They then open-sourced the corrected dataset Fever Symmetric on GitHub as a benchmark for other researchers to test their models against which I think is a good move for the research community at large that is actively trying to solve the problem of neural fake news.
If you are interested in finding more about their approach and experiments, feel free to read their original paper Towards Debiasing Fact Verification Models.
So creating large scale unbiased datasets I think is a good first step in the direction of future research on how to deal with neural fake news because as the datasets will increase so will the interest of researchers and organizations to build models to better the existing benchmarks.
This is the same thing that we have seen happen in NLP (GLUE, SQUAD) and CV (ImageNet) in the last few years.
Apart from that, when I think inclusively taking into account most of the research that we have come across, here are some directions that we can explore further:
- I personally believe that tools like Grover and GLTR are a good starting point to detect neural fake news, they set examples on how can we creatively use our current knowledge to build systems capable of detecting fake news. So we need to pursue further research in this direction, improve existing tools and validate them more not just against datasets but in real-world settings.
- The release of FEVER dataset is a welcome move and it’d benefit us in exploring and building more such datasets with fake news in a variety of settings as this will directly fuel further research.
- Finding veracity of text through a model is a challenging problem, yet we need to somehow structure it in such a way that it is easier to create datasets that are helpful in training models capable of authenticating a text on its factualness. Hence, further research in this direction is welcome.
- As rightly mentioned by the authors of both Grover and GLTR, we need to continue the openness in the research community by releasing large language models in future like GPT-2, Grover etc. responsibly did because we can only build strong defenses if we know how capable our adversary is.
Have you dealt with the problem of Fake News before? Have you tried building a model to identify Neural Fake News? Do you think there are other areas that we need to look when considering future directions? Let me know in the comments below!
A computer science graduate, I have previously worked as a Research Assistant at the University of Southern California(USC-ICT) where I employed NLP and ML to make better virtual STEM mentors. My research interests include using AI and its allied fields of NLP and Computer Vision for tackling real-world problems.








Hello :) Great article. Recently I hit tonns of spam sites on google and other search engines. I wonder if NLP methods could not be used for data mining, f.e. to classify search results basing on their "style". Unfortunatelly i realize it is just quick temporary hack, because spammers are not just malicious script kiddies but military sponsored experts - so they will adopt new cyber attack methods, like introducing new levels of semantic noise on each layer of the model to make it "stealth", or to mimic existing sources. Still even as temporary solution this allows classification of data generated -to-date- , so even if the disinformation era just begins, we can at least rush to petrify current knowledge. Those models also have potential of training them to detect autorship and plagiarism. assume you get article or artwork composed of copy&pasted fragments. Works of Guy Debord are good working model - here he deliberately obscured sources to derail original meaning, wchich was shocking in his cultural timeframe. Not so much for modern era scholars though - they simply cannot detect wchich -style- he imitates. but not to digress - while not bulletproof against properly done plagiarism (like re-generated after copy&paste mosaic is composed) , simple and naive attempts csn be easily detected! Even more usefull would be code analysis but this requires special models. Imagine being able to tell authors of mysterious libraries and git commits! even more in historical code like linux kernel archives! Greetings