Overview
- This article dives into the key question – is class sensitivity in a classification problem model-dependent?
- The authors analyze four popular deep learning architectures to perform two key experiments for class sensitivity
Introduction
Class sensitivity – a topic we don’t see a lot of machine learning folks focus on. And yet the problem persists in this domain.
The success of a classification project in machine learning depends a lot on how well-separated classes are. The least “grey areas”, the better. Clearly differentiated classes don’t leave a lot of opportunities for any model to mix things up.
One of the primary reasons we decided to write on the topic of class sensitivity is that we realized that there was no good framework to identify how well separated two classes were, or how suitable a dataset was to learn how to differentiate examples from two different classes.
We have divided our experiments and findings into three articles. The first one, which we will discuss briefly soon, is already live.
In this second article of this series, we discuss a key question – is class sensitivity model-dependent? We will explore this key area through two experiments we performed.
Table of Contents
- Quick Summary of the Class Sensitivity Experiments So Far
- Is Class Sensitivity Model Dependent?
- Experiment #1: Labeling Noise Induction
- Experiment #2: Data Reduction
Quick Summary of the Class Sensitivity Experiments So Far
We encourage you to go through the first article of this series but we’ll quickly summarize the key findings in this section.
We focused on trying to understand how particular classes could be more or less sensitive to the induction of noise in their labels, and to variations on the volume of the training data used.
If some classes were more ‘similar’ to each other, it would be easier for a model to make mistakes between instances from look-alike classes than between examples pulled from entirely different ones. We felt that this relative sensitivity was an understudied topic in Machine Learning, especially considering the potential gain research in this area could yield. For instance:
- If not all classes, and eventually all records, are equally sensitive to bad labels, then shouldn’t we spend more effort getting those ones labeled properly?
- If two classes were too similar to each other, wouldn’t that be an indication that the data is not well adapted to the number of classes we choose? That the machine learning scientist’s best bet would be to merge those two classes?
- Could class sensitivity be “fixed” by increasing the size of our training dataset? Or would such sensitivity remain, regardless of the volume of data used?
- Is class sensitivity model-dependent, or is it a property intrinsic to the data itself?

In order to attempt to answer some of these questions, we performed a series of “stress-testing” experiments using an easy and intuitive classification problem from which we modified the training set.
We ran two different experiments:
- In the first one focused on labeling noise induction, we gradually injected noise in the training labels of the original version of the CIFAR-10 dataset and observed its effect on the accuracy and interclass confusion
- In the second one, we studied the impact of data volume reduction by gradually decreasing the size of training CIFAR-10 data and observing its effect on the accuracy and interclass confusion
We found that the ‘cat’ class within the CIFAR-10 dataset was the most sensitive for both the experiments we ran followed by the ‘bird’ and ‘dog’ classes.
Is Class Sensitivity Model Dependent?
After starting out with a small (shallow) custom deep neural network in these experiments, we naturally started wondering if class sensitivity was model-dependent?
In other terms, would it be a wise investment in time for a data scientist to optimize his/her model if such effects were observed, or would their time be better spent on getting more data or better labels? If we used a deeper network, would the same classes be affected the most?
Taking the last article’s experiments one step further, we studied the effect of labeling noise induction and data volume reduction on different models.
We sampled a few models that are well-known to most machine learning scientists for the purpose of repeating our study and tested class sensitivity:
- ResNet18
- UnResNet18 (ResNet18 without the skip connections)
- GoogLeNet
- LeNet
At this point, we have focused solely on Deep Learning models. But we did choose relatively diverse architectures in order to get closer to an answer to the questions asked earlier.
If you haven’t read the details about our earlier work, fear not: we will explain the protocol in detail.
Prior to running our series of experiments, we train baseline versions for each one of the models cited above, so that we can study the discrepancies obtained when inducing noise or reducing data volume. In Figure 1 below, we show the baseline results for each model.
Every time, the model is trained using the full (50K-example) training set, which we refer to as S0% to say that 0% noise has been injected in the training set.
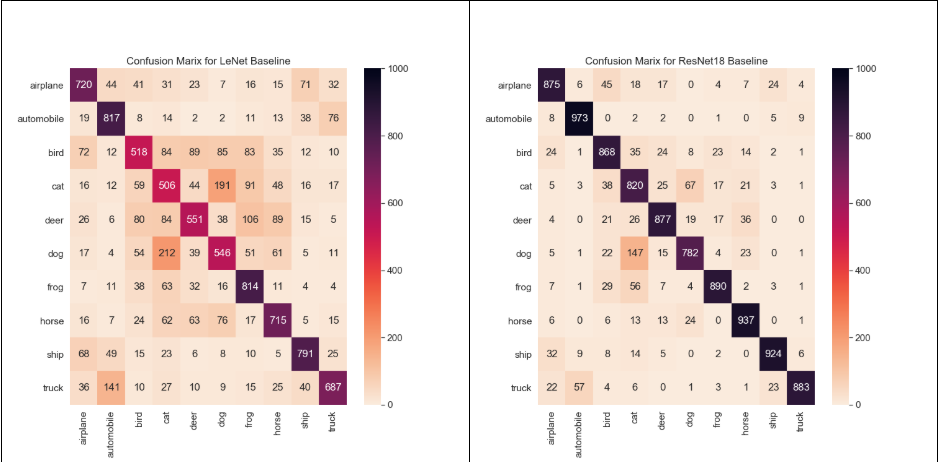

Figure 1: Confusion matrix for baseline i.e. 50K data samples and zero noise for LeNet, ResNet18, UnResNet18 and GoogLeNet models.
Important note: The ground truth labels are read at the bottom and the predicted labels on the left (so that on the baseline, there are 82 real cats that were predicted as frogs). We will use the same convention for the rest of the article.
Here are the details of the baseline results for all models:
| Model | Epochs | Batch Size | Accuracy |
| Custom (Keras with TF backend) | 125 | 64 | 88.94 |
| LeNet (Pytorch) | 125 | 64 | 66.6 |
| ResNet18 (Pytorch) | 25 | 64 | 88.29 |
| UnResNet18 (Pytorch) | 25 | 64 | 85.77 |
| GoogLeNet (Pytorch) | 25 | 64 | 88.6 |
Table 1: Baseline results for all models
A first look at the baseline confusion matrices across different models shows (unsurprisingly) that not all models perform equally even though the training set is the same.
- LeNet does very poorly compared to the other (deeper) models, even without any noise-induced
- The ‘bird’ class, which was particularly sensitive to noise in our original study, is problematic even when using a perfectly clean training set
- The ‘dog’ class appears to be the least accurate in both ResNet18 and UnResNet18
- LeNet shows the ‘cat’ class as being the most problematic, just like in the case of our original custom (and shallow) model
- The ‘cat’ and ‘dog’ classes are equally inaccurate in the case of the GoogLeNet model
Yet, while lots of differences can be noted when comparing the confusion matrices, we also observe a lot of commonalities. For instance, cats are always mostly confused for dogs and, to a lesser degree, for frogs. This is a strong indication that class similarity is, in fact, intrinsic to the data, and hence that some sensitivity will pre-dominate regardless of the model that is used.
After all, it isn’t hard to see how cats are more easily mistaken for dogs than they would be for planes. This is an important result since it clearly shows the existence of intrinsic weaknesses in a training set that models.
We can also observe that across the different model baselines, cross-class confusion is directional (i.e., the confusion matrix is not symmetrical), just like we observed in the analysis from the previous article.
Conclusions:
|
Experiment #1: Labeling Noise Induction
We will follow the same protocol that we used in our previous study. And we will repeat the following steps for adding labeling noise to the clean CIFAR-10 training dataset:
- Randomly select x% of the training set,
- Randomly shuffle the labels for those select records, call this sample Sx,
- Train all different models on Sx,
- Analyze the confusion matrix across all models
Again, as we did for our custom model to take into account the variance from selecting such a sample randomly, we re-ran the same experiment 5 times and averaged the results.
Below, we show the results for the average confusion matrix for S10%, i, 1≤i≤5 across different models:

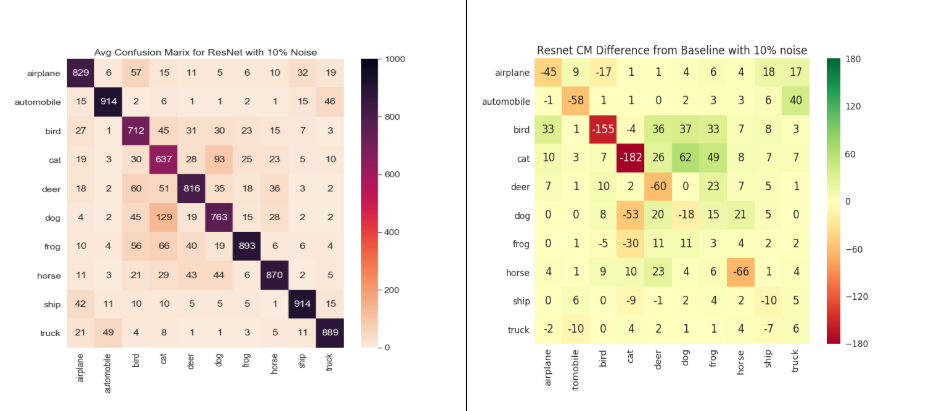
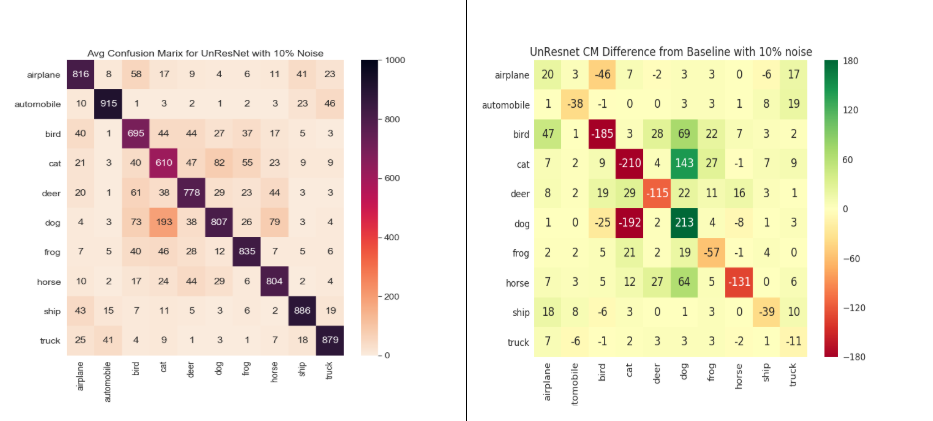

Figure 2: Left column shows Confusion matrix for S10% and right column shows relative confusion matrices for 10% noise for LeNet, ResNet18, UnResNet18 and GoogLeNet models
We can see from the above figure that LeNet reacts very badly to the labeling pollution (something which was kind of expected looking at its baseline confusion matrix. As the model is failing to perform well on the clean CIFAR-10 dataset, we can very well anticipate that it will perform very badly with pollution.
‘cat’ and ‘bird’ are the weakest classes in both ResNet18 and UnResNet18. Looking at the relative confusion matrix across models, we can see that GoogLeNet is very stable to labeling pollution compared to other models. Even in GoogLeNet, ‘cat’ and ‘bird’ are the weakest classes.
Figure 3 below shows the top 4 least accurate classes across models. Here, we can see that ‘cat’ is almost unequivocally the weakest class. And the models are somewhat biased about the second weakest class between ‘bird’ and ‘dog’.
It is worth noting that ‘cat’ is the least accurate across all models except LeNet and ‘bird’ and ‘cat’ turn out to be the most sensitive classes with labeling noise pollution. This probably tells us that classes that are sensitive remain sensitive regardless of the model used on them.
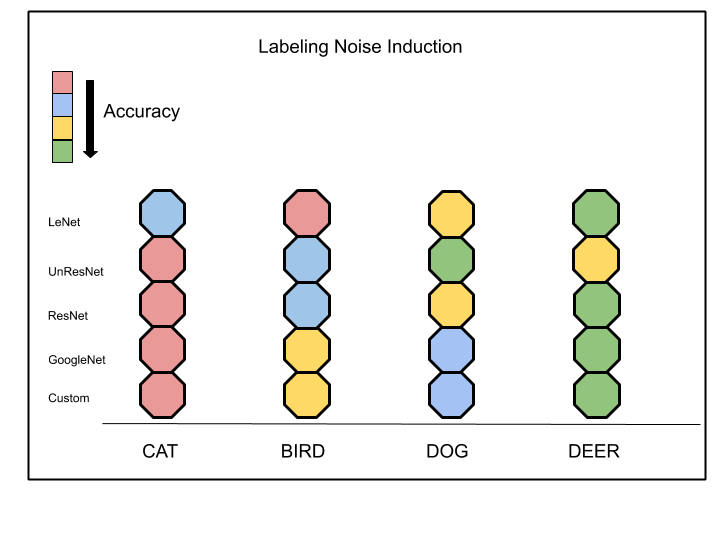
Figure 3: Weakest classes for 30% random labeling noise induction across models
This figure shows the classes that are least accurate across different models. We can infer that ‘cat’, ‘bird’ and ‘dog’ are the most affected with the labeling noise induction. After observing the results across different neural networks of varying depth and distinct architectures, we see that they tend to find the same classes confusing or hard to learn.
Conclusions:
|
Experiment #2: Data Reduction
The next experiment we performed was based on changing the data volume and observing effects on accuracy as well as the class sensitivity. This is because when increasing the amount of labeling noise, we also automatically reduce the amount of ‘good’ data available to the model, and hence the results of experiment 1 show a combination of both effects (less good data + more bad data), which we are trying to decouple.
In this experiment, we chose to reduce the size of the training set (without inducing any voluntary noise) and see the effects on the confusion matrix. Note that this data reduction experiment was performed on the clean CIFAR-10, i.e. without any labeling pollution.

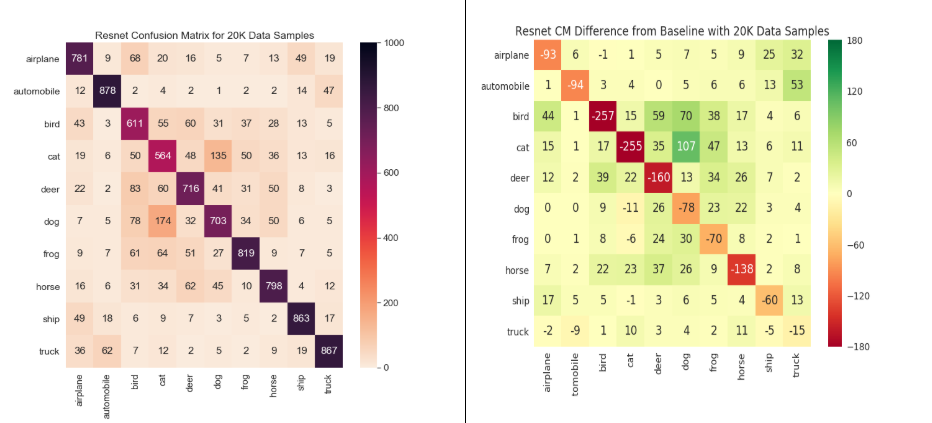

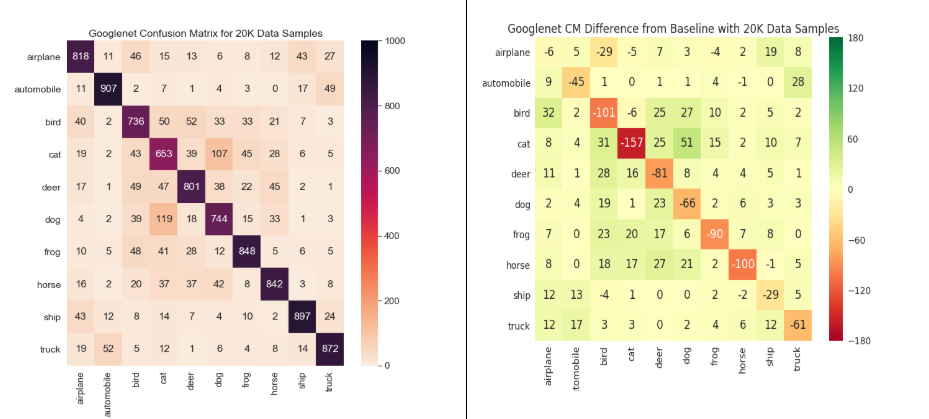
Figure 4: Left column shows the confusion matrix for 40% i.e. 20K data samples and the right column shows relative confusion matrices for 40% data samples for LeNet, ResNet18, UnResNet18, and GoogleNet models

Figure 5: Weakest classes for 90% (5K data samples) data reduction across models
We can see that the ‘cat’ and ‘bird’ classes are the most affected with data volume reduction throughout (across different models). The classes impacted by volume reduction are overall the same ones as those impacted by pollution.
This begs the question: is labeling noise causing issues only because it reduces the volume of good training data? Or are bad labels themselves confusing the model? ( Note: we will answer this question in depth in our third and last article on the topic).
Conclusions:
|
End Notes
This study brought us to an interesting observation: that the same classes were consistently affected both by the reduction of the size of the training set and by the injection of wrong labels regardless of the model we chose. This supports the hypothesis that class sensitivity is in fact not model-independent, but rather a data-intrinsic property.
If that is true, it is strong evidence that data scientists would be better advised to spend time curating their data as opposed to tuning their models.
But our study also brought us to some follow-up questions. Since the same classes were sensitive to noise injection and volume reduction, and since every noise injection experiment also caused the reduction of good (correctly labeled) data, it is fair to ask:
- If labeling noise would have an impact on a significantly large training set (i.e., does labeling quality matter as much for large datasets?), and,
- If the effect of bad labels could be compensated by the volume of data
These are the questions we will cover in the last article of this series.
Jennifer Prendki – Founder and CEO, Alectio

Jennifer is the founder and CEO of Alectio and has spent a large part of her career promoting the importance of creating a better approach to Machine Learning Lifecycle Management. Her current focus is on helping ML teams curate their data so that they can build better models with fewer resources.
Prior to founding Alectio, she was the VP of Machine Learning at Figure Eight, one of the industry leaders in data labeling (recently acquired by Appen).
She also headed Machine Learning at Atlassian and various Data Science initiatives on the Search team at Walmart Labs. She is known for her active support of women in STEM and Technology.
Akanksha Devkar – Machine Learning Engineer, Alectio

Akanksha is a Machine Learning Engineer at Alectio focusing on developing Active Learning strategies and other Data Curation algorithms. When not training neural networks on the machine, she is mostly firing her neurons in having thought experiments. She lives to eat and loves to star-gaze.
Need help curating your dataset or diagnosing your model? Contact us at Alectio! 🙂






After reading your article I was amazed. I know that you explain it very well. And I hope that other readers will also experience how I feel after reading your article.
Article looks fine, but please make sure that conclusion statements are not confusing. Complete article supports the statement "Class sensitivity is not model dependent,but it is data intrinsic property" Conclusion given : "Class sensitivity is not model independent" - very confusing. I request to change. Even it the previous article also: Cross confusion is directional & non directional (differently in 2 different statements).Please correct them