“The greater the obstacle, the more glory in overcoming it.”
– Moliere
Machine learning can be intimidating for people with a non-technical background. All machine learning jobs require a healthy understanding of Python or R.
So, how do non-programmers gain coding experience? It’s not a cakewalk!

Here’s the good news – plenty of tools out there let us perform machine learning tasks without having to code. You can easily build algorithms like decision trees from scratch in a beautiful graphical interface. Isn’t that the dream? These tools, such as Weka, help us primarily deal with two things:
- Quickly build a machine learning model, like a decision tree, and understand how the algorithm performs. This can later be modified and built upon
- This is ideal for showing the client/your leadership team what you’re working with
This article will show you how to solve classification and regression problems using Decision Trees in Weka without prior programming knowledge!
But if you are passionate about getting your hands dirty with programming and machine learning, I suggest going through the following wonderfully curated courses:
Table of contents
- Classification vs. Regression in Machine Learning
- Understanding Decision Trees
- What is Weka? Why Should You Use Weka for Machine Learning?
- Exploring the Dataset in Weka
- Classification using the Decision Tree in Weka
- Decision Tree Parameters in Weka
- Visualizing your Decision Tree in Weka
- Regression using the Decision Tree in Weka
- Conclusion
- Frequently Asked Questions
Classification vs. Regression in Machine Learning
Let me first quickly summarize what classification and regression are in machine learning. It’s important to know these concepts before you dive into decision trees.
A classification problem teaches your machine learning model how to categorize a data value into one of many classes. It does this by learning the characteristics of each type of class. For example, to predict whether an image is of a cat or dog, the model learns the characteristics of the dog and cat on training data.
A regression problem involves teaching your machine learning model how to predict the future value of a continuous quantity. It does this by learning the pattern of the quantity in the past affected by different variables. For example, a model trying to predict a company’s future share price is a regression problem.
You can find both these problems in abundance on our DataHack platform.
Now, let’s learn about an algorithm that solves both problems – decision trees!
Understanding Decision Trees
Decision trees are also known as Classification And Regression Trees (CART). They work by learning answers to a hierarchy of if/else questions that lead to a decision. These questions form a tree-like structure, hence the name.
For example, let’s say we want to predict whether a person will order food. We can visualize the following decision tree for this:
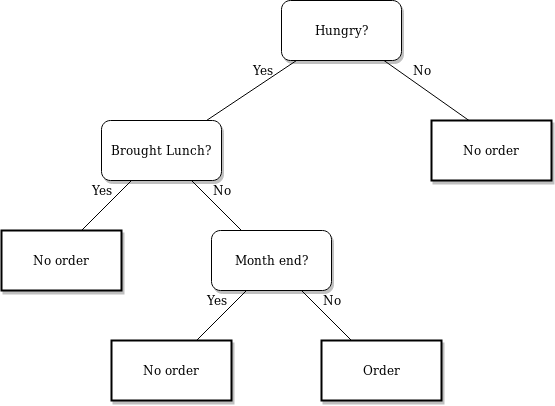
Each node in the tree represents a question derived from the features present in your dataset. Your dataset is split based on these questions until the maximum depth of the tree is reached. The last node does not ask a question but represents which class the value belongs to.
- The topmost node in the Decision tree is called the Root node
- The bottom-most node is called the Leaf node
- A node divided into sub-nodes is called a Parent node. The sub-nodes are called Child nodes
If you want to understand decision trees in detail, I suggest going through the resources below:
- Getting Started with Decision Trees (Free Course)
- Tree-Based Algorithms: A Complete Tutorial from Scratch
What is Weka? Why Should You Use Weka for Machine Learning?
” Weka is a free open-source software with a range of built-in machine learning algorithms that you can access through a graphical user interface! “
WEKA stands for Waikato Environment for Knowledge Analysis and was developed at the University of Waikato, New Zealand.
Weka has multiple built-in functions for implementing various machine learning algorithms, from linear regression to neural networks. This allows you to deploy the most complex of algorithms on your dataset at just a click of a button! Additionally, Weka supports accessing some of the most common machine learning library algorithms of Python and R!
With Weka, you can preprocess the data, classify it, cluster it, and even visualize it! You can do this with different formats of data files like ARFF, CSV, C4.5, and JSON. Weka even allows you to add filters to your dataset, through which you can normalize your data, standardize it, interchange features between nominal and numeric values, and more!
I could go on about the wonder that Weka is, but for this article’s scope, let’s explore Weka practically by creating a decision tree. Now go ahead and download Weka from their official website!
Exploring the Dataset in Weka
I will take the Breast Cancer dataset from the UCI Machine Learning Repository. Before proceeding, I recommend that you read about the problem.
First, let us load the dataset in Weka. To do that, follow the below steps:
- Open Weka GUI
- Select the “Explorer” option.
- Select “Open file” and choose your dataset.
Your Weka window should now look like this:
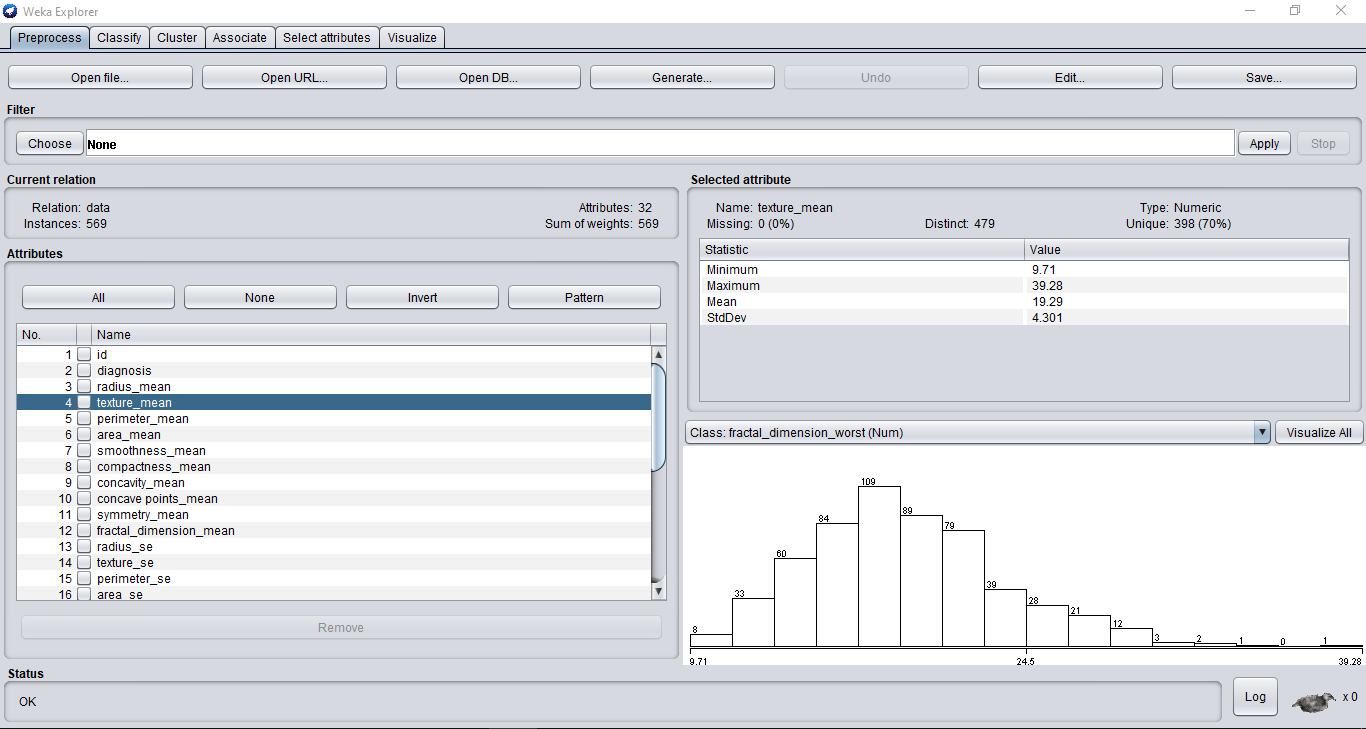
You can view all the features in your dataset on the left-hand side. Weka automatically creates plots for your features, which you will notice as you navigate them.
You can even view all the plots together by clicking the “Visualize All” button.
Now let’s train our classification model!
Classification using the Decision Tree in Weka
Implementing a decision tree in Weka is pretty straightforward. Just complete the following steps:
- Click on the “Classify” tab on the top
- Click the “Choose” button
- From the drop-down list, select “trees”, which will open all the tree algorithms.
- Finally, select the “RepTree” decision tree.
” Reduced Error Pruning Tree (RepTree) is a fast decision tree learner that builds a decision/regression tree using information gain as the splitting criterion, and prunes it using reduced error pruning algorithm.”
You can read about the reduced error pruning technique in this research paper.

“Decision tree splits the nodes on all available variables and then selects the split which results in the most homogeneous sub-nodes.”
Information Gain is used to calculate the homogeneity of the sample at a split.
You can select your target feature from the drop-down above the “Start” button. If you don’t do that, WEKA automatically selects the last feature as your target.
The “Percentage split” specifies how much of the data you want to keep for training the classifier. The rest of the data is used during the testing phase to calculate the model’s accuracy.
With “Cross-validation Fold”, you can create multiple samples (or folds) from the training dataset. If you create N folds, the model is iteratively run N times. Each time, one of the folds is held back for validation while the remaining N-1 folds are used to train the model. The result of all the folds is averaged to give the result of cross-validation.
The greater the number of cross-validation folds you use, the better your model will become. This makes the model train on randomly selected data which makes it more robust.
Finally, press the “Start” button for the classifier to do its magic!

Our classifier has an accuracy of 92.4%. Weka even prints the Confusion matrix, which gives different metrics. You can study the Confusion matrix and other metrics in detail here.
Decision Tree Parameters in Weka
Decision trees have many parameters. We can tune these to improve our model’s overall performance. This is where a working knowledge of decision trees plays a crucial role.
You can access these parameters by clicking on your decision tree algorithm on top:

Let’s briefly talk about the main parameters:
- maxDepth: It determines the maximum depth of your decision tree. By default, it is -1, meaning the algorithm will automatically control the depth. But you can manually tweak this value to get the best results on your data.
- noPruning: Pruning means automatically cutting back on a leaf node that does not contain much information. This keeps the decision tree simple and easy to interpret.
- numFolds: The specified number of folds of data will be used to prune the decision tree. The rest will be used to develop the rules.
- minNum: Minimum number of instances per leaf. If not mentioned, the tree will keep splitting until all leaf nodes have only one associated class.
You can always experiment with different values for these parameters to get the best accuracy on your dataset.
Visualizing your Decision Tree in Weka
Weka even allows you to visualize the decision tree built on your dataset easily:
- Go to the “Result list” section and right-click on your trained algorithm
- Choose the “Visualise tree” option

Your decision tree will look like the following:

Interpreting these values can be intimidating, but it’s pretty easy once you get the hang of it.
- The values on the lines joining nodes represent the splitting criteria based on the values in the parent node feature
- In the leaf node:
- The value before the parenthesis denotes the classification value
- The first value in the parenthesis is the total number of instances from the training set in that leaf. The second value is the number of instances incorrectly classified in that leaf.
- The first value in the second parenthesis is the total number of instances from the pruning set in that leaf. The second value is the number of instances incorrectly classified in that leaf.
Regression using the Decision Tree in Weka
As I said before, Decision trees are so versatile that they can work on classification and regression problems. For this, I will use the “Predict the number of upvotes” problem from Analytics Vidhya’s DataHack platform.
Here, we need to predict the rating of a question asked by a user on a question-and-answer platform.
As usual, we’ll start by loading the data file. But this time, the data also contains an “ID” column for each user in the dataset. This would not be useful in the prediction. So, we will remove this column by selecting the “Remove” option underneath the column names:

We can make predictions on the dataset as we did for the Breast Cancer problem. RepTree will automatically detect the regression problem:

The evaluation metric provided in the hackathon is the RMSE score. Without any feature engineering, the model has a very poor RMSE. This is where you step in—go ahead, experiment, and boost the final model!
Conclusion
This article has introduced how non-programmers can easily dive into machine learning using Weka, a powerful yet accessible tool for building decision trees without coding. With Weka, you can quickly create and evaluate models, explore decision tree parameters, and visualize results—all through an intuitive interface. By mastering Weka’s features, you can confidently work with classification and regression problems, making it an excellent starting point for those new to machine learning. Embrace this opportunity to expand your skills, and let Weka be your first step into the exciting world of machine learning!
Frequently Asked Questions
Q1. How to use Weka for decision tree?
A. To use Weka for decision trees:
1. Load your dataset (ARFF format).
2. Choose “Explorer” interface.
3. Select “Classify” tab, pick “J48” (C4.5 algorithm).
4. Load data, set target attribute.
5. Click “Start” to build tree.
6. Evaluate results using “Classifier output.”
Tweak settings like pruning, confidence factor, etc. for better results. Weka simplifies decision tree creation and analysis for data mining tasks.
Q2. What is J48 decision tree in Weka?
A. J48, implemented in Weka, is a popular decision tree algorithm based on the C4.5 algorithm. It creates decision trees by recursively partitioning data based on attribute values. J48 employs information gain or gain ratio to select the best attribute for splitting. It handles categorical and numeric attributes, supports pruning to prevent overfitting, and is widely used for classification tasks due to its simplicity and effectiveness.
Q3. What is C4.5 Decision Tree in WEKA?
A. C4.5 is a decision tree algorithm in WEKA, known as “J48,” used for classification tasks. It builds decision trees by recursively splitting data based on information gain or gain ratio. C4.5 handles both categorical and numerical attributes, supports pruning to avoid overfitting, and is widely used in data mining.
Q4. How Do You Draw a Decision Tree?
A. To draw a decision tree, start with the root node representing the main decision point. Add branches for possible outcomes or decisions, connecting to new nodes representing further splits. Continue branching until leaf nodes are reached, which indicates outcomes. Tools like WEKA or diagramming software simplify this process.
Q5. How Do You Write a Decision Tree Algorithm?
A. Writing a decision tree algorithm involves defining a recursive function that selects the best feature for splitting data, usually based on criteria like information gain. Based on this feature, split the dataset, create child nodes, and repeat until reaching a stopping condition, such as maximum depth or homogeneity in leaf nodes.
I am on a journey to becoming a data scientist. I love to unravel trends in data, visualize it and predict the future with ML algorithms! But the most satisfying part of this journey is sharing my learnings, from the challenges that I face, with the community to make the world a better place!






I am not sure the explanation (data used is randomly selected) given for Cross fold Validation is entirely correct. Below is what I found for WEKA with a Google search: "What is cross validation in Weka? Cross-validation. Cross-validation, a standard evaluation technique, is a systematic way of running repeated percentage splits. Divide a dataset into 10 pieces (“folds”), then hold out each piece in turn for testing and train on the remaining 9 together. This gives 10 evaluation results, which are averaged."
Hi Ron Thank you for pointing it out. I guess my statement was a bit ambiguous and I did not explain myself there. I have made relevant and recommended changes. I hope it is clear now. Your comment was much appreciated.
Good job!
Thanks James!
Thanks for you for this post. I have installed Weka but but my Tree classifier is empty. Kindly assist to overcome this challenge.