When working with categorical data in machine learning, it’s crucial to convert these variables into a numerical format that algorithms can understand. Two commonly used techniques for encoding categorical variables are one-hot encoding (OHE) and label encoding. Choosing the appropriate encoding method can significantly impact the performance of a machine learning model. In this article, we will explore the differences between one one hot encoding and label encoding, their use cases, and how to implement them using the Pandas and Scikit-Learn libraries in Python.
In this article, you will learn when to use one hot encoding and label encoding, the differences between them, and how to choose the right method for your data. We’ll explore what label encoding is, the distinctions between one hot encoding and label encoding, and provide insights into one hot encoder vs labelencoder. By the end, you’ll understand the importance of selecting the appropriate encoding technique for your categorical variables in machine learning.
Learning Objectives:
- Understand categorical encoding techniques for machine learning
- Learn how to implement label encoding and one-hot encoding in Python
- Recognize when to use label encoding vs. one-hot encoding
Table of contents
What is Categorical Encoding?
A structured dataset typically includes a mix of numerical and categorical variables. Machine learning algorithms can only process numerical data, not text. This is where categorical encoding comes into play.

Categorical encoding converts categorical columns into numerical columns, allowing machine learning algorithms to interpret and process the data effectively.
Different Approaches to Categorical Encoding
So, how should we handle categorical variables? There are several methods, but this article will focus on the two most widely used techniques:
- Label Encoding
- One-Hot Encoding (OHE)
These techniques are essential for preparing your categorical data for machine learning models, ensuring they can learn and make predictions accurately.
Checkout our course on Applied Machine Learning – Beginner to Professional to know everything about ML functions!
What is Label Encoding?
Label Encoding is a common technique for converting categorical variables into numerical values. Each unique category value is assigned a unique integer based on alphabetical or numerical ordering.
Let’s walk through how to implement label encoding using both Pandas and the Scikit-Learn libraries in Python:
Implementing Label Encoding using Pandas
Step1: Import the Required Libraries and Dataset
#importing the libraries
import pandas as pd
import numpy as np
#reading the dataset
df=pd.read_csv("Salary.csv")Output:

Understanding the datatypes of features:
#Checking the data types of all columns
df.info()Output:

From the output, we see that the first column, Country, is a categorical feature represented by the object data type, while the remaining columns are numerical features represented by float.
Step 2: Implement Label Encoding
Now that we have already imported the dataset earlier, let’s go ahead and implement Label encoder using scikit-learn.
# Import label encoder
from sklearn import preprocessing
# Create a label encoder object
label_encoder = preprocessing.LabelEncoder()
# Encode labels in the 'Country' column
df['Country'] = label_encoder.fit_transform(df['Country'])
print(df.head())Output:

Again, Country values are transformed into integers.
Challenges with Label Encoding
Label encoding imposes an arbitrary order on categorical data, which can be misleading. In the given example, the countries have no inherent order, but one hot encoding and label encoding introduces an ordinal relationship based on the encoded integers (e.g., France < Germany < Spain). This can cause the model to falsely interpret these categories as having a meaningful order, potentially leading to incorrect inferences.
By understanding and implementing one hot encoding vs label encoding with both Pandas and Scikit-Learn, you can efficiently convert categorical data for machine learning models while being aware of its limitations and the potential for misinterpretation.
Checkout this article about the Pandas Functions for Data Analysis and Manipulation
What is One Hot Encoding?
One-Hot Encoding is another popular technique for treating categorical variables. It simply creates additional features based on the number of unique values in the categorical feature. Every unique value in the category will be added as a feature. One-Hot Encoding is the process of creating dummy variables.
Implementing One-Hot Encoding in Python using Scikit-Learn
Here’s how you can implement one-hot encoding using Scikit-Learn in Python:
Import the Necessary Libraries
from sklearn.preprocessing import OneHotEncoder
import pandas as pdCreate a OneHotEncoder Object and Transform the Categorical Data
# creating one hot encoder object
onehotencoder = OneHotEncoder()
# reshape the 1-D country array to 2-D as fit_transform expects 2-D and fit the encoder
X = onehotencoder.fit_transform(df.Country.values.reshape(-1, 1)).toarray()
Convert the Transformed Data into a DataFrame and Concatenate it with the Original DataFrame
# Creating a DataFrame with the encoded data
dfOneHot = pd.DataFrame(X, columns=["Country_" + str(int(i)) for i in range(X.shape[1])])
# Concatenating the original DataFrame with the encoded DataFrame
df = pd.concat([df, dfOneHot], axis=1)
# Dropping the original 'Country' column
df = df.drop(['Country'], axis=1)
# Displaying the first few rows of the updated DataFrame
print(df.head())Output:

As you can see, three new features are added because the Country column contains three unique values – France, Spain, and Germany. This method avoids the problem of ranking inherent in one hot encoding and label encoding, as each category is represented by a separate binary vector.
Implementing One-Hot Encoding using Pandas
Here’s how you can implement one-hot encoding using Pandas.
Import the Necessary Library
import pandas as pdUse the get_dummies Method to Perform One-hot Encoding
# One-Hot Encoding using Pandas
df = pd.get_dummies(df, columns=['Country'], dtype='int')
# Displaying the first few rows of the updated DataFrame
df.head()Output:

Using Pandas’ get_dummies method, you can achieve the same result with fewer steps. This method automatically handles the conversion of the categorical Country column into multiple binary columns.
Also, specifying the data type as int is important because, by default, get_dummies will return boolean values (True or False). Setting dtype='int' ensures the new columns contain integer values instead.
Can you see any drawbacks with this approach? Think about it before reading on.
Challenges of One-Hot Encoding: Dummy Variable Trap
One-Hot Encoding results in a Dummy Variable Trap as the outcome of one variable can easily be predicted with the help of the remaining variables. Dummy Variable Trap is a scenario in which variables are highly correlated to each other.
The Dummy Variable Trap leads to the problem known as multicollinearity. Multicollinearity occurs where there is a dependency between the independent features. Multicollinearity is a serious issue in machine learning models like Linear Regression and Logistic Regression.
So, in order to overcome the problem of multicollinearity, one of the dummy variables has to be dropped. Here, I will practically demonstrate how the problem of multicollinearity is introduced after carrying out the one-hot encoding.
One of the common ways to check for multicollinearity is the Variance Inflation Factor (VIF):
- VIF=1, Very Less Multicollinearity
- VIF<5, Moderate Multicollinearity
- VIF>5, Extreme Multicollinearity (This is what we have to avoid)
Compute the VIF scores:
# Function to calculate VIF
def calculate_vif(data):
vif_df = pd.DataFrame(columns = ['Var', 'Vif'])
x_var_names = data.columns
for i in range(0, x_var_names.shape[0]):
y = data[x_var_names[i]]
x = data[x_var_names.drop([x_var_names[i]])]
r_squared = sm.OLS(y,x).fit().rsquared
vif = round(1/(1-r_squared),2)
vif_df.loc[i] = [x_var_names[i], vif]
return vif_df.sort_values(by = 'Vif', axis = 0, ascending=False, inplace=False)
X=df.drop(['Salary'],axis=1)
calculate_vif(X)Output:
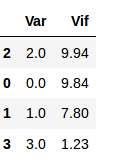
From the output, we can see that the dummy variables which are created using one-hot encoding have VIF above 5. We have a multicollinearity problem.
Now, let us drop one of the dummy variables to solve the multicollinearity issue:
df = df.drop(df.columns[[0]], axis=1)
calculate_vif(df)Output:
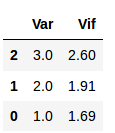
Wow! VIF has decreased. We solved the problem of multicollinearity. Now, the dataset is ready for building the model.
We recommend you to go through Going Deeper into Regression Analysis with Assumptions, Plots & Solutions for understanding the assumptions of linear regression.
When to Use a Label Encoding vs. One Hot Encoding
This question generally depends on your dataset and the model which you wish to apply. But still, a few points to note before choosing the right encoding technique for your model:
We apply One-Hot Encoding when:
- The categorical feature is not ordinal (like the countries above)
- The number of categorical features is less so one-hot encoding can be effectively applied
We apply Label Encoding when:
- The categorical feature is ordinal (like Jr. kg, Sr. kg, Primary school, high school)
- The number of categories is quite large as one-hot encoding can lead to high memory consumptionLabel Encoding vs One Hot Encoding vs Ordinal Encoding
One-Hot Encoding vs Label Encoding
| Column Names | One-Hot Encoding | Label Encoding |
|---|---|---|
| Description | Converts each unique category value into a new binary column. | Assigns each unique category value an integer. |
| Example | “India” -> [1, 0, 0] “Japan” -> [0, 1, 0] “USA” -> [0, 0, 1] | “India” -> 0 “Japan” -> 1 “USA” -> 2 |
| When to Use | Non-ordinal categorical features. Manageable number of unique categories. | Ordinal categorical features. Large number of unique categories. |
| Advantages | Prevents the model from assuming any inherent order. | Simple and efficient for ordinal data. Does not increase dimensionality. |
| Disadvantages | Can lead to high dimensionality with many unique categories. | Imposes an arbitrary order on non-ordinal data. Model might assume false relationships. |
Conclusion
Understanding the differences between one-hot encoding vs label encoding is crucial for effectively handling categorical data in machine learning projects. By mastering these encoding methods and implementing Scikit-Learn, data scientists can enhance their skills and deliver more robust and accurate ML solutions.
One way to master all the data science skills is with our Blackbelt program. It offers comprehensive training in data science, including topics like feature engineering, encoding techniques, and more. Explore the program to know more!
Key Takeaways:
- Label encoding assigns integers to categories, but can imply false ordinal relationships
- One-hot encoding creates binary columns for each category, avoiding implied ordering
- Choose encoding method based on data type (ordinal vs. nominal) and number of categories
Also Read:
- 15+ Github Machine Learning Repositories for Data Scientists
- Top 10 GitHub Data Science projects and Machine Learning Projects
Frequently Asked Questions
Q1. What’s the difference between label encoding and one-hot encoding?
A. Label encoding assigns a unique numerical value to each category, while one-hot encoding creates binary columns for each category, with only one column being “1” and the rest “0” for each observation.
Q2. What is the difference between one-hot encoding and label encoding in random forest?
A. Random forests handle label encoding well by treating numerical labels as ordinal. One-hot encoding is used to avoid implying ordinal relationships between categories, which can mislead the model.
Q3. When should we use one-hot encoding?
A. One-hot encoding is used when categorical variables do not have an ordinal relationship, ensuring that the model does not assume any unintended hierarchy among the categories.
Q4. What is an example of one-hot encoding?
A. For a color feature with categories [“red”, “blue”, “green”], one-hot encoding creates three binary columns: “red” [1, 0, 0], “blue” [0, 1, 0], and “green” [0, 0, 1].
Aspiring Data Scientist with a passion to play and wrangle with data and get insights from it to help the community know the upcoming trends and products for their better future.With an ambition to develop product used by millions which makes their life easier and better.







Hi Alakh, Wanted to ask about the case where variable is not ordinal but number of categories is very large. How to treat those categorical variables.
For decision tree algorithms like random forest, even if the categorical variable is nominal, it doesn't seem to have a problem with being represented as ordinal using label or ordinal encoder. Seems unintuitive. Can someone please explain? H20 infact says that they use enum encoding where the categories are given a numerical value , but the numbers themselves are irrelevant(hence not imposing ordinality on nominal variables). But their classification performance doesn't seem to be much different from sklearn's random forest classifier using ordinal encoder)
Thank you.