Introduction
I had the pleasure of volunteering for ICLR 2020 last week. ICLR, short for International Conference on Learning Representations, is one of the most notable conferences in the research community for Machine Learning and Deep Learning.
ICLR 2020 was originally planned to be in Addis Ababa, Ethiopia. But due to the recent COVID-19 induced lockdowns around the world, the conference was shifted to a fully virtual format. While this took away the networking aspect of the event, the fully online conference allowed budding researchers and machine learning enthusiasts to join in as well.
In this article, I will share my key takeaways from ICLR 2020. I will also share a data-based survey (that I personally undertook) to find the preferred tools among the research community, with an emphasis on tools for performing cutting-edge Deep Learning research, aka PyTorch and TensorFlow.
Key Takeaways from ICLR 2020
To start off, here’s the link to the ICLR 2020 website and a summary of the key numbers as shared by the organizers:

Now, let’s dig in!
1. Fully virtual conference structure
ICLR 2020 was held between 26th April and 1st May, and it was a fully virtual conference. All the interactions from participants, presenters and organizers was online through their website.
The first day consisted entirely of really interesting workshop sessions, and it was followed by keynote talks, paper presentations/poster sessions, and socials/expos for each day for the rest of the day. The entire day was action-packed!

There were, in total, 650+ research papers accepted, and each of the papers involved a 5-min video presentation and live Q&A sessions by the authors on the paper itself (marked in green in the schedule). The video was more or less the highlights/summary of the paper where the authors presented their approach and key findings/contributions. The videos were mostly self-paced, while the live Q&A sessions were organized keeping in mind the various time zones of the attendees – a really thoughtful gesture, which I am sure involved a lot of effort.
There were keynote talks too (marked in blue), involving highly influential researchers with the likes of Yoshua Bengio and Yann LeCun; and expos from the industry giants and even leading AI startups. Note the specific timings of Keynote talks, which were kept in the specific time to accommodate as many people from diverse time zones as possible.
ICLR adopted a very engaging approach when it came to the informal session. There were numerous socials (aka video conferences) organized and you could attend the one pertaining to your topic of interest. Additionally, depending on the demand, there were more than one zoom calls for certain topics.
For example, Reinforcement Learning had 10 parallel sessions going on – since it is a very popular domain. Also, there were separate channels for beginners as well and ones for mentoring. In these sessions, whether it be through chat or video conference, you could interact and discuss the topic without any specific pre-defined agenda. For example, in mentoring sessions, you could ask an experienced researcher what it’s like to do research in the XYZ domain, and he/she was more than happy to answer!
Another impressive, fun, and novel approach I would like to give kudos to was the ICLR Town. Think of it as a Virtual Reality session that involved discussions in the backdrop of VR locations – like beaches, the outdoors, etc. The best part? Mario avatars for the users in a meeting!
Now we are at a #beachparty #iclrparty pic.twitter.com/ODeXLYRsr8
— Shagun Sodhani (@shagunsodhani) April 28, 2020
The ICLR Town took Twitter by storm and thus, was really popular amongst the conference attendees. Needless to say, most of the key learnings from this fully virtual conference will be used by upcoming conference organizers.
2. Notable influencers from the research community and distinguished sponsors from the industry
Being the premier research conference in AI and Deep Learning, ICLR has always attracted leading personalities and thought leaders in this domain, and this year was no different. Despite the lockdown restrictions and the entire conference being conducted online, notable speakers included:
- Andrew Ng
- Yann LeCun
- Yoshua Bengio
- Richard Sutton
- Shakir Mohamed
and many more influencers.
Similarly, many sponsors were equally enthusiastic about the online ICLR conference:

This impressive list highlights the standard ICLR sets each year and the level of research that is presented in the Sponsor Booths as well.
3. Open Review – an open peer review process to promote openness in scientific communication
One key aspect of ICLR 2020 that I would like to draw your attention to is Open Review. We are quite familiar with the usual review processes of research conferences. These reviews are closed and thus, the lack of transparency has been a bone of contention amongst researchers.
ICLR follows the Open Review process, in which the papers are available for reading online openly. You can comment on it and check reviews of other researchers. This peer-review process was well-received and I hope this creates a mark for other future conferences as well to introduce transparency among the research community.
4. The most explored topic by the researchers – Deep Learning
Deep learning is a hot topic right now, and ICLR 2020 just cemented that notion. There was an unofficial survey to find the most explored topics by researchers, and here’s what they came up with:
Understandably, the most covered topics included Deep Learning applied both in a supervised and an unsupervised manner, Reinforcement Learning, and Representation Learning. Other significant topics included attention mechanisms for supervision and Generative Adversarial Networks (GANs).
As far as the domains are concerned, Computer Vision and Natural Language Processing (NLP) were the prevalent topics, though topics like Game Playing and Numerical Optimization had many submissions as well.
There was so much to learn from the conference, which at times seemed overwhelming. This thought is perfectly summarized in this tweet:
Exhausted! Can't believe how much I learned in one day! All thanks to the organizers and this mind-blowing virtual format #ICLR2020 pic.twitter.com/oqLblIxp7q
— Servando (@vandotorres) April 26, 2020
5. Simplistic but accessible website interface
Being a completely virtual and online conference, I would particularly like to highlight the great website Interface for the attendees and the volunteers.
The sessions were easily accessible and the website was easy to use. I could search and explore the papers without any hassle and there were many additional features available to fully leverage the research presented. I especially liked the availability of a single visualization for all the paper/posters on the conference webpage – a scatter plot based on topic similarity was easy to understand and made foraging through the research papers much easier:
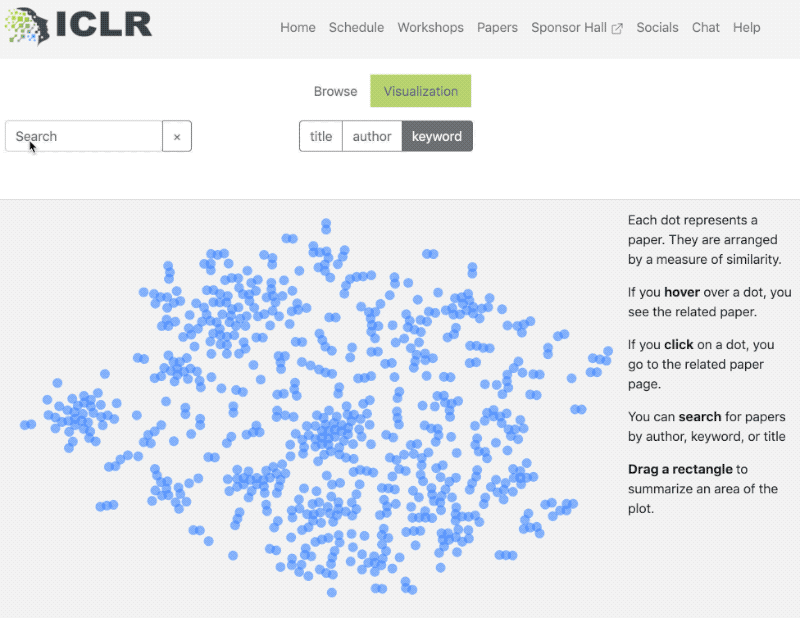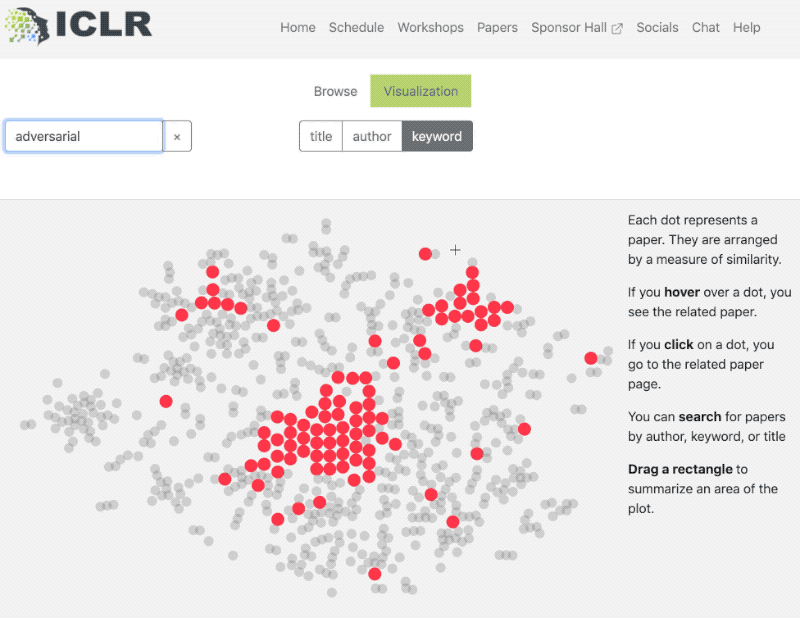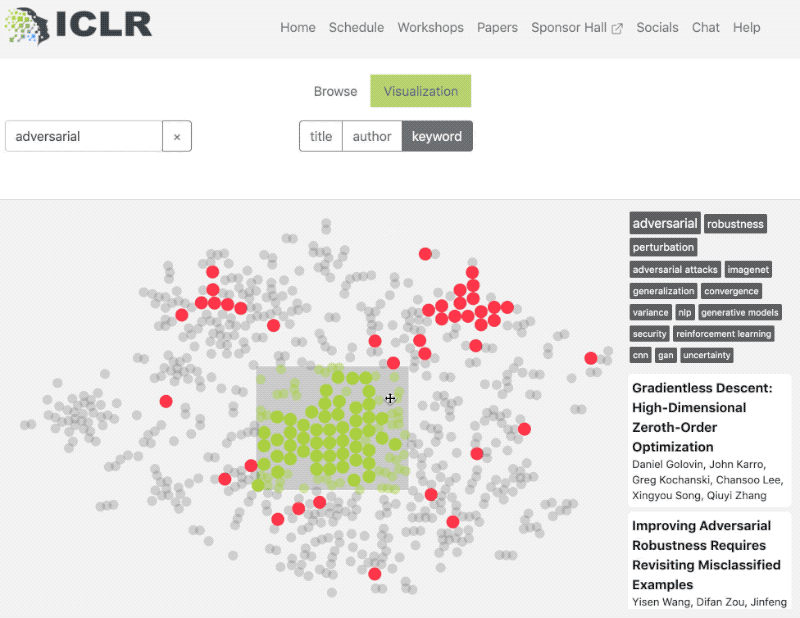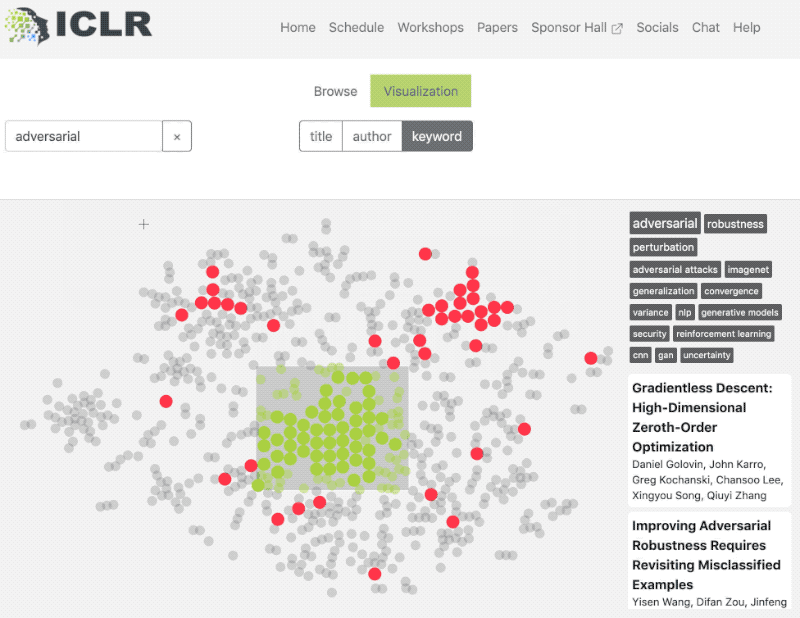
Even Andrew Ng had good things to say on how great the website was:
I'm really enjoying the new #ICLR2020 website, and am having fun browsing the workshop & poster talks. Congrats to the organizers and speakers on what's happening so far in this all-virtual conference! Great job! @srush_nlp @shakir_za @kchonyc @dawnsongtweets @syhw et al. pic.twitter.com/e4e5MfYh6W
— Andrew Ng (@AndrewYNg) April 27, 2020
Along with the website, the live videos and slides used were hosted via SlidesLive while Zoom was used for Q&A sessions. The chat interface was RocketChat and the Sponsor Booths were hosted via 6Connex.
To conclude, here are a few interesting resources I would like to share with you so that you can get a sense of how well-organized and comprehensive ICLR 2020 was:
- The videos and slides for most of the research papers are supposed to be SlidesLive, and they can be viewed by the general public
- The mentoring channel was particularly useful for research students and the answers by the professors/experienced researchers to their questions were compiled in a single document: [ICLR 2020] Tips for prospective and early-stage Ph.D. students
- A non-comprehensive list of the popular Open-Source Tools that are being used across research domains: 10 open-source tools in 10 minutes
- The Virtual ICLR conference caused quite a stir on Twitter. Here’s how you can scour through the tweets: #ICLR2020
Case Study on the Preferred Tools at ICLR 2020 – PyTorch or TensorFlow?
Now we come to my favorite part of the article!
Just to give you a brief background, the idea was brought about in the discussions of an informal session on “Open source tools and practices in state-of-the-art DL research” (i.e, social_OSS). The original question was:
“Which tool is actually preferred by the researchers at ICLR – is it PyTorch or TensorFlow?”
This question can be rethought as:
“What are the open-source tools used by the researchers who shared their codes at ICLR 2020 pertaining to Deep Learning research?
And from this, can we make an educated guess on which tools will be relevant in the near future and will probably be adopted in some way by the industry?”
But what is the motivation behind doing this case study?
- A typical question that people who are getting started with Deep Learning, whether it be experienced industry professionals or just students/freshers, ask me is – which deep learning library should I start with? Even now, my recommendation would be to start with easy to use high-level libraries like Keras or Fastai, but it’s good to know the trends in the usage of tools by the research community
- Generally, the industry plays catch up to cutting-edge research that happens in leading research labs, from following up with the ideas published in research papers to making the implementations of these ideas production-friendly. For this reason, it is important to know which tools can actually help to create these implementations
- Also, ICLR is the best place to get acquainted with cutting-edge research. It is one of the most renowned tier-one conferences for machine learning and deep learning and has a well-established research community
Summary of Key Findings
Let’s get down to business – I’ll quickly summarize my findings here, and then I will walk you through the code that I used to reach these findings. For the impatient folks, here’s the link to the code and the data using which you can explore the patterns yourself.
1. Main tools for Deep Learning

Of the 237 codes shared by the researchers that I could successfully parse, 154 of them used PyTorch for their implementation, in comparison to 95 for TensorFlow, and 23 for Keras.
This clearly depicts that PyTorch is becoming more and more accepted by the research community, although TensorFlow is not far behind. Researchers still use Keras in their codes, but the number is quite less. This might be because, in terms of flexibility, both PyTorch and TensorFlow provide more flexibility than its counterpart.
Note: You can start learning all about PyTorch here.
Also, it is worth mentioning that a few tools like HuggingFace’s Transformers, OpenAI’s Gym framework, or networkX, which have proven to be useful in their niche domain such as NLP, Reinforcement Learning and Graph Networks respectively, are getting accepted by the community. Along with that, TensorBoard is getting accepted as a norm for visualizing the training of Deep Neural Networks:

2. Preferred tools overall
2.1 Top 10 usage of tools/packages
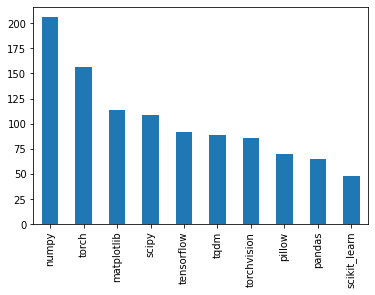
Here, we can see that the usual data science/machine learning tools such as NumPy, SciPy, matplotlib, Pandas, and scikit_learn are still relevant, even in the research community. Emerging tools like tqdm and torchvision are being used much more by the researchers.
2.2 Word cloud of top 100 tools
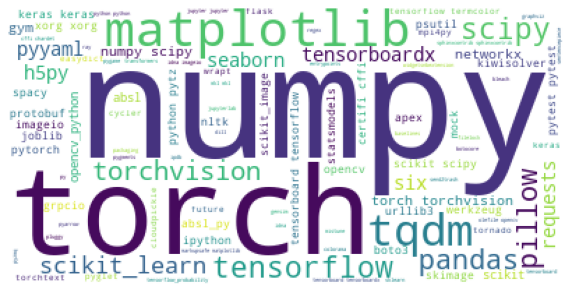
Here, we can better visualize the relevant tools or packages used by the researchers in the form of a word cloud. Looks cool, right?
Methodology Behind the Case Study
For those of you interested to know how I came up with these findings, I will now describe the steps I followed, and explain in detail the code you can use to reproduce the steps. Note that I used Google Colab for implementation as it has most of the data science libraries preinstalled. If you don’t know how to use Colab, you can refer to this guide. Otherwise, if you prefer using your own machine, you would have to set up the system with the below libraries:
- Data science tools/packages generally found in Anaconda distribution such as NumPy, Pandas, matplotlib
- OpenReview API
- pipreqs
- word_cloud
Code Walkthrough
These were the steps I followed for the case study:
- Setting up the system
- Get code links from OpenReview API for ICLR 2020
- Brute force downloading codes from GitHub
- Based on requirements.txt, find all the tools used and create a data file
- Data Analysis for finding tool usage
I will focus mainly on the data analysis part because most of the readers would find it helpful. If you want me to explain how the data is generated, do let me know in the comments below and I will add it in this article itself.
Step 1 – Setting up the System
The first thing we do is install libraries in Colab, namely OpenReview API and pipreqs:
After this, we will import all the necessary libraries/packages we will be using throughout the notebook:
Steps 2 to 4 – Data Creation
Here, as I mentioned, we follow these steps:
- Get code links from OpenReview API for ICLR 2020
- Brute force downloading codes from GitHub
- Based on requirements.txt, find all the tools used and create a data file
To summarize, in terms of numbers, there are 687 papers accepted in total, of which 344 researchers have shared their implementations for the respective papers. Of these, 268 are GitHub repositories on which I have primarily focused. Out of these 268, I could successfully parse 237 GitHub repositories based on their requirements.txt file and summarized the tools used on the basis of this requirements.txt.
After running the code, we get a file called “all_tools.csv”. If you want to follow along with me, you can download the data file from this link.
Step 5 – Data Analysis for finding tool usage
In this section, we will be asking two main questions to the data:
- How many research papers use a specific tool, such as PyTorch or TensorFlow?
- Which tool/package is most used by the researchers?
Let us read the data file:
Let’s see the first five rows of the all_tools dataframe and we will see that our data is very unclean:
Python Code:
import os
import re
import sys
import requests
import openreview
import pandas as pd
import matplotlib.pyplot as plt
from random import choice
from wordcloud import WordCloud
from urllib.parse import urlparse
all_tools = pd.read_csv("all_tools.csv")
print(all_tools.head())If you run this, the output comes out to be (237, 2), specifying that we have 237 rows, i.e. we are analyzing 237 GitHub repositories.
Now, let’s clean our data. Here’s a rough pseudo code of what this code block does:
- For each row in the column “all_tool_names”:
- We split the string on comma to get a list of tools
- Then, for each tool in this list of tools,
- we perform cleaning on the basis of regular expression “^\w+”, which separates the name of the tool from the rest of the string
- After this, we again make a single string from these list of names of tools, and
- Return that string
After cleaning, if we print the head of the all_tools dataframe again, we get an output like this:

Now, let’s see how many repositories contain PyTorch. We can use the “str.contains” function of Pandas to find this:
This gives us a count of 154, which tells us that there are 154 repositories in total that use PyTorch in some way or other.
Let’s write a formal function which we can use to replicate this for other tools:
Notice that we are using an offset variable to add the count. We do this to make the function flexible enough to add repositories that haven’t been parsed, but we can assume there’s a high chance the specific tool is present in that repository.
Let’s run this function for three specific deep learning tools, namely PyTorch, TensorFlow, and Keras:
We get an output like this:

This clearly expresses that PyTorch is fairly popular among the research community in comparison to TensorFlow or Keras.
Here, you can see that I’ve used an offset of 12 for TensorFlow – this is because there are a few instances where the GitHub repositories are not parsed, but they are from either Google-research GitHub username or TensorFlow’s original repository, which clearly indicate that they might be built on TensorFlow.
You can follow similar steps for a different tool/package/framework. Here I’ve done this for HuggingFace’s Transformers, TensorBoard, OpenAI’s Gym, and networkX:

Next, let see how many unique tools are present in our data:
This code gives us an output of (687,) indicating that there are 687 unique tools used in total.
Let’s print the top 50 most frequent tools that occur in the data:
We get an output like this:
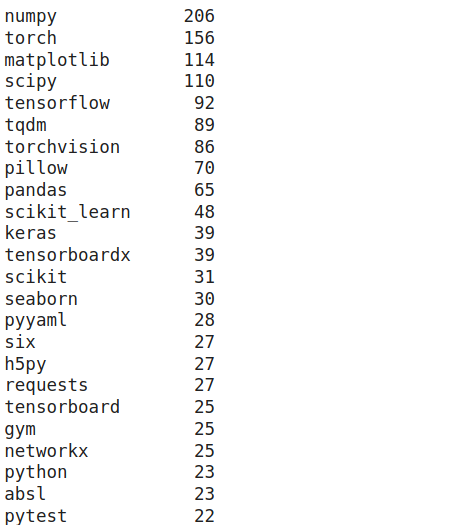
As expected, most of the repositories use common data science tools/libraries such as NumPy, SciPy, matplotlib, and Pandas.
Let’s plot this in a more visual way. For this, we can either use a bar plot or a word cloud. The below code is for creating a bar plot:
We get a plot like this:
We can instead visualize this as a word cloud:
This gives us an output like this:
In the interest of time, this is the extent of the data exploration I’ve done. We can perhaps do more than this, and I’ve mentioned in the next section some of the ideas that can be explored.
Final Thoughts on ICLR 2020
In this article, I have summarized my key takeaways from ICLR 2020. I have also explained a case study to understand the usage of tools in the research community.
As an acknowledgement, I would like to thank ICLR 2020 organizers for hosting this wonderful conference, and also for giving me the opportunity to be a part of the event as a volunteer. In addition, I would like to especially mention Sasha Rush, Patryk Mizuila and the Analytics Vidhya team who helped me through the case study.
What I’ve done in this article is a simple exploration of the data. There are a few more ideas that can be explored, such as:
- We can find which domain does the code belong to, i.e. is it more of an NLP related research, or is it more related to Computer Vision or Reinforcement Learning? Accordingly, we can find the corresponding tools and do a comparative study of tools based on the domain
- We can find the affiliations of the researchers and their respective lines of work. Then, based on this, we can summarize the work done by either a specific company or a university, or even by demographics
- Based on the previous iterations of ICLR, we can find the trends over time of the usage of tools in the research community
- We can make the code that I’ve written more efficient, either in terms of how much time it takes to run the code or the resources (network speed or computational power) it takes to successfully complete it.
Alas! There’s so much I can do with my time, right?

Faizan is a Data Science enthusiast and a Deep learning rookie. A recent Comp. Sc. undergrad, he aims to utilize his skills to push the boundaries of AI research.

