Object Detection is a computer vision task in which you build ML models to quickly detect various objects in images, and predict a class for them
For example, if I upload a picture of my pet dog to the model, it should output the probability that it detected a dog in the image, and a good model would show something along the lines of 99% Object Detection is a rapidly evolving field with research teams and scientists publishing thousands of interesting and intuitive research papers per year – each new paper improving upon its predecessor with increased accuracy and faster detection times.
But hey, we gotta start somewhere, right? In this article, I’ll show you how you can quickly start detecting objects in images of your own, using the YOLO v1 architecture on the Google Colab platform, in no time.
Did I mention you have free access to fast GPU computing power? Okay so let’s talk about the YOLO v1 model.
In 2014, Joseph Redmon and his team brought out the YOLO model for object detection in front of the world. Moreover, YOLO was designed to be a unified architecture in that. Unlike its predecessors, it would perform all the operations required in object detection (extracting features using CNNs, predicting bounding boxes around objects, scoring those bounding boxes using SVMs, etc.) using a single CNN model.
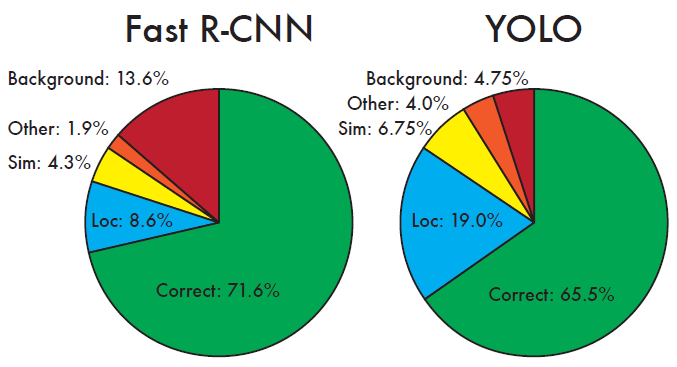
In addition, it would do this in real-time too. Models before YOLO didn’t have a high real-time detection speed. For example, Fast R-CNN, which claimed to be an improvement over the famous R-CNN model, only had a meager speed of 0.5 FPS (frames per second)
YOLO v1 not only has a speed of 45 FPS (90x faster than Fast R-CNN), it improves upon Fast R-CNN by making much less background false positive errors
Comparison of YOLO v1 and Fast R-CNN on various error types (credits)
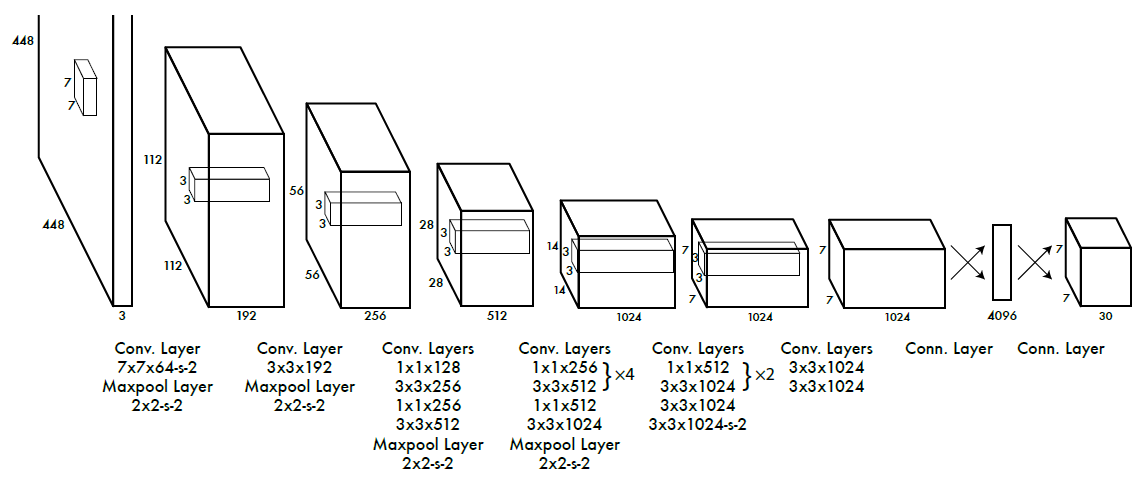
The following is the architecture of the YOLO v1 model-
💡 The model has 24 convolutional layers followed by 2 fully connected layers.
It takes in an input image of dimensions 224 x 224 and resizes it to 448 x 448 for the detection task. The output is a 7 x 7 x 30 tensor containing predictions which the model makes on the input image
Also, introduced in the same paper, Fast YOLO boasts of a blazingly quick real-time performance of 155 FPS. Even faster and more accurate versions of YOLO exist — YOLO 9000, YOLO v3, and the very recent YOLO v4
We’ll talk about the performance statistics of YOLO and its variants in future posts, let’s now get our hands dirty with YOLO v1 using Colab!
Playing with YOLO on Colab
The following steps illustrate using if YOLO-
1. Installing Darknet
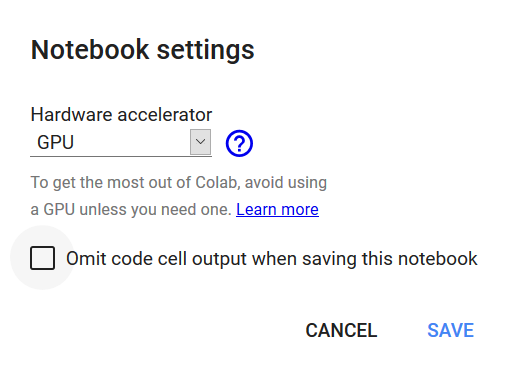
Firstly, let’s set our Colab runtime to use a GPU. You can do this by clicking on “Runtime”, then “Change Runtime type”, and choosing a GPU runtime
Darknet is a library created by Joseph Redmon which eases the process of implementing YOLO and other object detection models online, or on a computer system.
Further, on Colab, we install Darknet by first cloning the Darknet repository on Git, and changing our working directory to ‘darknet’ as follows
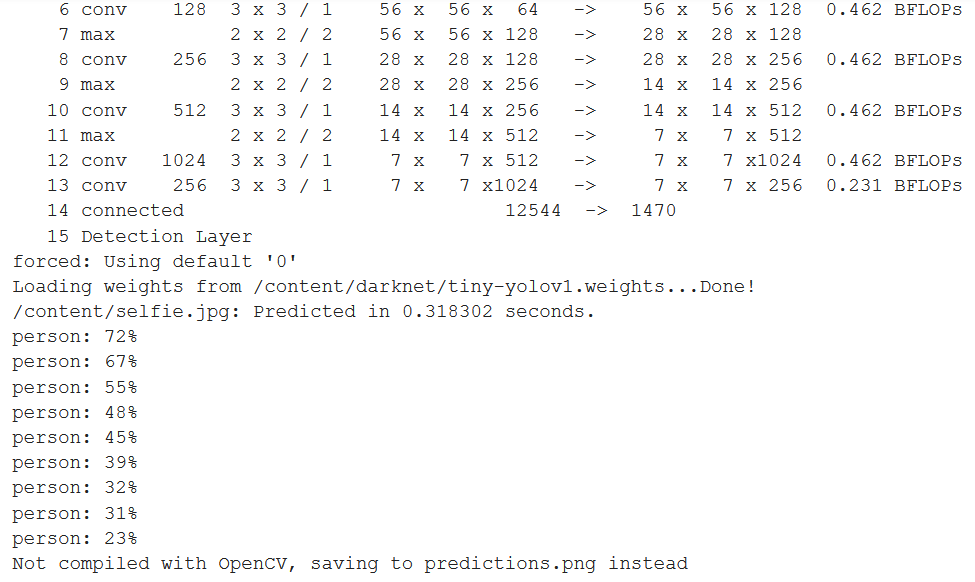
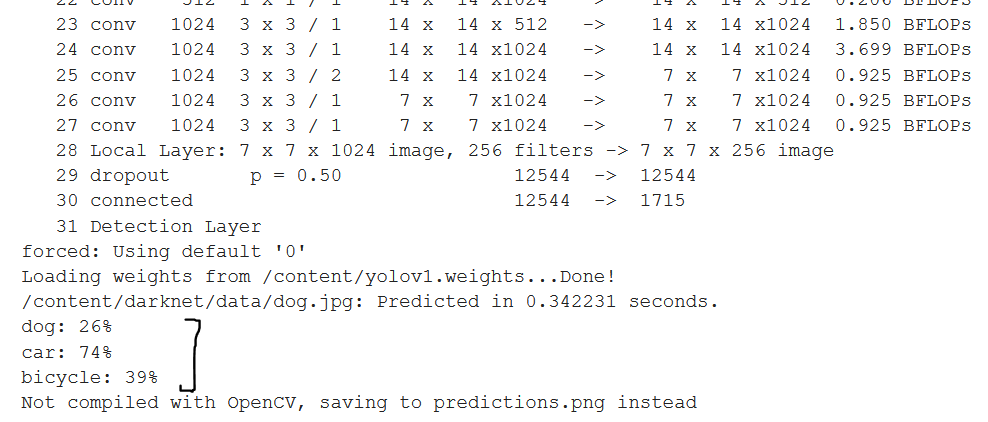
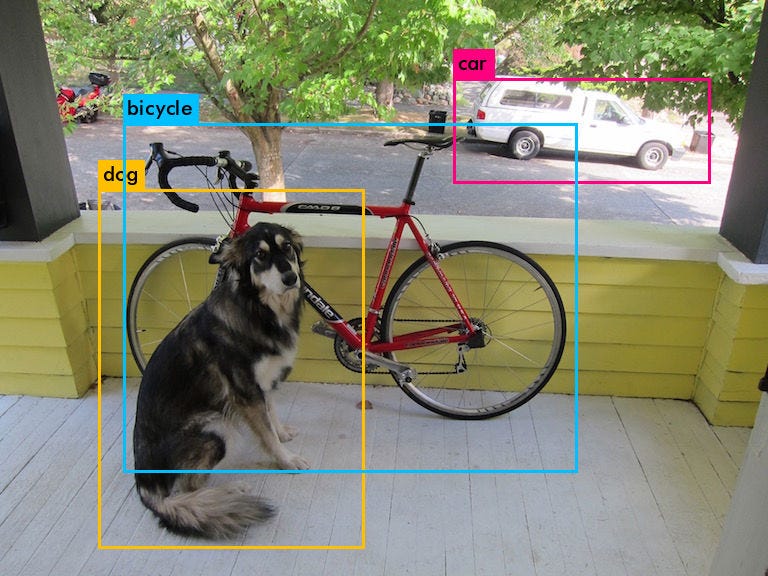
And finally, when running on this image, we get the following output
os.chdir("/content/darknet/")!./darknet yolo test /content/darknet/cfg/yolov1-tiny.cfg /content/darknet/tiny-yolov1.weights /content/selfie.jpg
So we see, our model has identified 9 people from this image. Let’s view the detections
Thank You for reading this article. As a bonus, you can try running the above codes on Colab yourself, using this notebook. Thus, we saw how we can detect objects in our images, using the state-of-the-art YOLO model, on the cloud using Google Colab.
In conclusion, I hope you learned useful stuff from this article. For more articles (coming soon), follow me on LinkedIn and Medium!

 (
(






 (
(