Introduction
The Python and NumPy indexing operators [] and attribute operator ‘.’ (dot) provide quick and easy access to pandas data structures across a wide range of use cases. The index is like an address, that’s how any data point across the data frame or series can be accessed. Rows and columns both have indexes.

The axis labeling information in pandas objects serves many purposes:
- Identifies data (i.e. provides metadata) using known indicators, important for analysis, visualization, and interactive console display.
- Enables automatic and explicit data alignment.
- Allows intuitive getting and setting of subsets of the data set.
Different Choices for indexing and selecting data
Object selection has had several user-requested additions to support more explicit location-based indexing. Pandas now support three types of multi-axis indexing for selecting data.
.locis primarily label based, but may also be used with a boolean arrayWe are creating a Data frame with the help of pandas and NumPy. In the data frame, we are generating random numbers with the help of random functions. Here the index is given with label names of small alphabet and column names given with capital alphabets. The index contains six alphabet means we want rows and three columns, also mentioned in the ‘randn’ function.If these two values mismatch with index, column labels, and in ‘randn’ function, then it will give an error.
# import the pandas library and aliasing as pd
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.randn(6, 3),index = ['a','b','c','d','e','f'], columns=['A', 'B', 'C'])
print (df.loc['a':'f'])How to check the values is positive or negative in a particular row. For that we are giving condition to row values with zeros, the output is a boolean expression in terms of False and True. False means the value is below zero and True means the value is above zero.
# for getting values with a boolean array print (df.loc['a']>0)
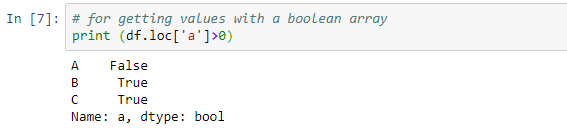
As we see in the above code that with .loc we are checking the value is positive or negative with boolean data. In row index ‘a’ the value of the first column is negative and the other two columns are positive so, the boolean value is False, True, True for these values of columns.
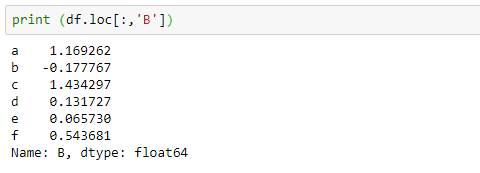
Then, if we want to just access the only one column then, we can do with the colon. The colon in the square bracket tells the all rows because we did not mention any slicing number and the value after the comma is B means, we want to see the values of column B.
print df.loc[:,'B']
.ilocis primarily integer position based (from0tolength-1of the axis), but may also be used with a boolean array. Pandas provide various methods to get purely integer based indexing.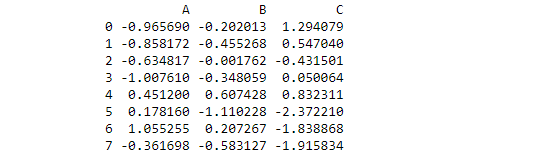 In the above small program, the
In the above small program, the .ilocgives the integer index and we can access the values of row and column by index values. To know the particular rows and columns we do slicing and the index is integer based so we use.iloc. The first line is to want the output of the first four rows and the second line is to find the output of two to three rows and column indexing of B and C.# Integer slicing print (df1.iloc[:4]) print (df1.iloc[2:4, 1:3])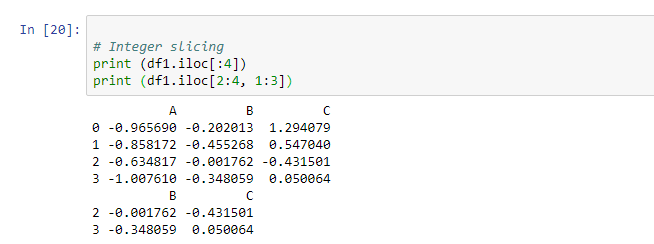
.ixis used for both labels and integer-based. Besides pure label based and integer-based, Pandas provides a hybrid method for selections and subsetting the object using the .ix() operator.import pandas as pd import numpy as npdf2 = pd.DataFrame(np.random.randn(8, 3), columns = [‘A’, ‘B’, ‘C’])# Integer slicing print (df2.ix[:4])
The query() Method
DataFrame objects have a query() method that allows selection using an expression. You can get the value of the frame where column b has values between the values of columns a and c.
For example:
#creating dataframe of 10 rows and 3 columns
df4 = pd.DataFrame(np.random.rand(10, 3), columns=list('abc'))
df4

The condition given in the below code is to check that x is smaller than b and b is smaller than c. If both the condition is true then print the output. With this condition, only one row passed the condition.

Give the same conditions to the query function. If we compare these two condition the query syntax is simple than data frame syntax.
#with query()
df4.query('(x < b) & (b < c)')

Duplicate Data
If you want to identify and remove duplicate rows in a Data Frame, two methods will help: duplicated and drop_duplicates.
- duplicated: returns a boolean vector whose length is the number of rows, and which indicates whether a row is duplicated.
- drop_duplicates: removes duplicate rows.
Creating a data frame in rows and columns with integer-based index and label based column names.
df5 = pd.DataFrame({'a': ['one', 'one', 'two', 'two', 'two'],
'b': ['x', 'y', 'x', 'y', 'x'],
'c': np.random.randn(5)})
df5

We generated a data frame in pandas and the values in the index are integer based. and three columns a,b, and c are generated. here we checked the boolean value that the rows are repeated or not. For every first time of the new object, the boolean becomes False and if it repeats after then, it becomes True that this object is repeated.
df5.duplicated('a')

The difference between the output of two functions, one is giving the output with boolean and the other is removing the duplicate labels in the dataset.
df5.drop_duplicates('a')

Conclusion:
There are a lot of ways to pull the elements, rows, and columns from a DataFrame. There is some indexing method in Pandas which helps in selecting data from a DataFrame. These are by far the most common ways to index data. The .loc and .iloc indexers use the indexing operator to make selections
About the Author

Amit Chauhan
I am a Research Scholar and a technical person with 4-year experience in R&D Electronics. Data Science enthusiastic





