This article was published as a part of the Data Science Blogathon.
Introduction
Machine learning in Data Science involves constructing predictive models using historical data to forecast outcomes for new data without known answers. Evaluating predictions is crucial, typically focusing on minimizing errors between actual and predicted values for improved accuracy. Supervised learning, with labeled data like classification, contrasts with unsupervised learning, which lacks labels, as in clustering. Clustering, a form of unsupervised learning, partitions data into groups based on similarities, aiding in data exploration and pattern identification.
Evaluation measures such as the rand index, calinski-harabasz Index, and mutual information gauge clustering quality, while scatter plots visualize data distribution. Popular algorithms like k-means and agglomerative clustering, available in libraries like scikit-learn (sklearn), facilitate segmentation and analysis. Understanding clustering models, dimensionality, and entropy enhances model interpretation and selection, making this tutorial essential for mastering machine learning techniques.
Learning Objectives
This post explores popular evaluation metrics for classification, regression, and clustering:
- Understand terms related to confusion matrices and associated metrics.
- Learn evaluation metrics like RMSE, MAE, and R-squared for regression.
- Explore clustering metrics like the Silhouette coefficient and Dunn’s Index.
These metrics have implementations in various platforms like Python, R, etc., facilitating quick revision for machine learning evaluation.
This article was published as a part of the Data Science Blogathon.
Understanding Clustering Algorithms
Clustering algorithms are pivotal tools in data analysis, enabling the identification of natural groupings within datasets. Key algorithms such as K-means, hierarchical, and DBSCAN offer distinct approaches to clustering.
K-means, a widely-used centroid-based algorithm, partition data into K clusters by iteratively optimizing cluster centroids to minimize intra-cluster variance. Hierarchical clustering, conversely, constructs a tree-like hierarchy of clusters, either agglomeratively or divisively, allowing for the exploration of nested clusters. Meanwhile, DBSCAN, a density-based algorithm, groups together data points based on their proximity and density, distinguishing between core points, border points, and noise.
Each algorithm operates differently, suited to different data structures and objectives. K-means is efficient for large datasets with well-defined clusters, while hierarchical clustering is flexible and suitable for datasets with varying cluster sizes. DBSCAN, adept at handling noise and irregular cluster shapes, excels in identifying clusters of varying densities.
Selecting the appropriate clustering algorithm is paramount to obtaining meaningful insights from data. Considerations such as data distribution, cluster shape, and noise levels guide the selection process, ensuring that the chosen algorithm aligns with the dataset’s characteristics and analysis goals. The right clustering algorithm lays the foundation for accurate and insightful data clustering, driving informed decision-making and problem-solving.
Classification Performance Evaluation Metrics
Classification problems are ubiquitous in machine learning, categorizing observations into classes or labels. This entails learning a function mapping input variables (X) to discrete output variables (Y). For instance, classifying emails as spam or not spam exemplifies this. Handling binary or multi-class classification is common, and occasionally, observations may belong to multiple classes, constituting a multi-label classification challenge. To assess a classification model, understanding the confusion matrix is fundamental, allowing evaluation of clustering results and hierarchical clustering, if applicable. It provides insights into the model’s performance across different classes and aids in selecting appropriate evaluation metrics.
When you are dealing with two classes it’s a binary classification problem and when there are more than two classes it becomes a multi-class classification problem. Sometimes the observation can also be assigned multiple classes and that’s a multi-label classification problem. To evaluate a classification machine-learning model you have to first understand what a confusion matrix is.
Confusion Matrix
A confusion matrix is a table that describes the performance of a classification model, or a classifier, on a set of observations for which the true values are known (supervised). Each row of the matrix represents the instances in the actual class, while each column represents the instances in the predicted class (or vice versa). For example, here is a dummy confusion matrix for a binary classification problem predicting yes or no (1 or 0) from a classifier :
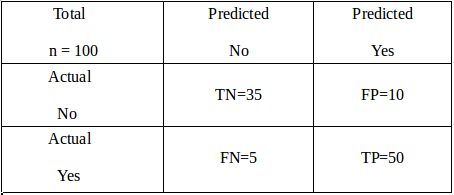
Let’s try to understand this matrix in the context of an example. Imagine you are trying to build a model to predict whether a reader will be interested in reading this article, and let’s say you are trying to classify 100 potential readers. Out of those 100 readers, the classifier predicted “Yes” 60 times and “No” 40 times. While in reality, 55 readers eventually ended up reading this article and hence were marked “Yes,” and 45 readers did not read and hence were marked as “No.”
From the given information, the following terms could be defined :
True Positives (TP): These are cases in which you predicted Yes (the reader will read the article) and were labeled Yes (the reader will read the article).
True Negatives (TN): You predicted No (the reader will not read the article), and they were labeled No (the reader did not read the article).
False Positives (FP): You predicted Yes, but they were labeled as No (also known as a Type I error)
False Negatives (FN): You predicted No, but they were labeled Yes (also known as a Type II error)
- Accuracy: The most commonly used metric is accuracy. Mathematically defined as (TP+TN)/Total. It tells you how often the classifier is correct in making the predictions. In this example accuracy = 50+35/100 = 0.85.Generally, it is not advised to judge your model on accuracy in case of imbalanced class datasets, as you can get high accuracy just by predicting all the observations as the dominant class.
- Precision: It answers the question: When the classifier predicts yes, how often is it correct? Mathematically calculated as TP/predicted Yes. In this example, precision = 50/(50+10) = 0.83.
- Recall: It answers the question: When it’s actually Yes, how often does the classifier predict yes? Mathematically calculated as TP/actual Yes. In this example, recall = 50/(50+5) = 0.90.
- False Positive Rate (FPR): It answers the question: When it’s no, how often does the classifier predict Yes? Mathematically calculated as FP/actual No. In this example, precision = 10/(35+10) = 0.22.
- F1 Score: This is a harmonic mean of the Recall and Precision. Mathematically, it is calculated as (2 x precision x recall)/(precision+recall). There is also a general form of the F1 score called the F-beta score, wherein you can provide weights to precision and recall based on your requirements. In this example, F1 score = 2×0.83×0.9/(0.83+0.9) = 0.86
Of course, there are various other metrics you can choose to judge your model’s performance, like Misclassification rate, Specificity, etc. Still, they are more or less related to the abovementioned metrics and can be examined in conjunction. Try to keep things simple, don’t get confused with these terms, and most importantly, try to understand the meaning of the metrics rather than cramming them up.
Receiver Operator Characteristic (ROC) Curve
Whenever you apply a classifier to assign a label against an observation, the classifier generates a probability against the observation, not the label. The probability indicates how confidently you can assign a label against the observation. Then, after comparing it with a preset threshold value, you assign the label to it. If you relax your threshold to a lower value, your test observations will have more readers labeled Yes. The controlling threshold depends on the use case. For example, in the advertisement industry, your goal is to capture the maximum number of people who will click on the ad. Therefore, you can relax your threshold while predicting to target more people.
- The ROC or Receiver Operator Characteristic curve plots the Recall (True Positive Rate) (on the y-axis) versus the False Positive Rate (on the x-axis) for every possible classification threshold.
- You should check the ROC curve to evaluate a classifier instead of a simpler metric such as accuracy because a ROC curve visualizes all possible classification thresholds. In contrast, accuracy only represents performance for a single threshold. A typical ROC curve looks like the image shown below:

- You would want to try to build a model that produces a ROC curve close to the upper left corner or, in other words, which has a maximum Area Under the Curve (AUC). Also, if your AUC is less than 0.5, i.e., the ROC curve falls below the red line, your model is even worse than a model based on random guesses.
- One important thing to know before understanding ROC curves is the threshold concept.
All the metrics discussed above can also be extended to a multi-class classification problem by using a one-versus-all approach wherein you club all the other classes except one as a separate class and repeat this process for clustering evaluation.
Precision-Recall (PR) Curve
- Another curve used to evaluate the classifier’s performance as an alternative to an ROC curve is a precision-recall curve (PRC), particularly in the case of imbalanced class distribution problems. It is a curve between precision and recall and typically looks like :

A good classifier will produce a PR curve close to the upper right corner.
Logarithmic Loss
- Logarithmic Loss, or Log Loss, tells you how confident the model is in assigning a class to an observation. If you use Log Loss as your performance metric, you must assign a probability to each class for all the samples. For any given problem, a lower log-loss value means better predictions. One important point about log loss is that it heavily penalizes classifiers’ confidence about an incorrect classification. For example, suppose you predicted a probability of 0.8 for a reader who read). In that case, your log-loss will be small as your model predicts a high probability for this article (1) positive class (1). But if you predict a lower probability, say 0.1, for a reader who reads this article (1), then log-loss will be greater.
- Suppose N samples are belonging to M classes; then the Log Loss is calculated as below:

where,
- 𝑦𝑖𝑗 indicates whether sample i belongs to class j or not
- 𝑝𝑖𝑗 indicates the probability of sample i belonging to class j
- The range of Log Loss is [0, ∞).
Regression Performance Evaluation Metrics
Another common type of machine learning problem is regression problems. Here, instead of predicting a discrete label/class for an observation, you predict a continuous value. For example, predicting the selling price of a house is a regression problem. A regression problem can be linear or non-linear.
The following metrics are most commonly used to evaluate a regression model:
Mean Absolute Error (MAE)
Mean Absolute Error is the average difference between the original and predicted values. It measures how far the predictions are from the actual output; obviously, you would want to minimize it. However, it doesn’t give you an idea of the direction of the error since you are taking only the absolute values. It doesn’t penalize large errors as much as compared to RMSE. Mathematically, it is represented as:

where,
- n is the number of observations
- 𝑦𝑗 is the actual value for sample j
- 𝑦̂ 𝑗 is the predicted value for sample j
For example, let’s pick a regression problem where you are trying to predict the number of readers of this article, and let’s say your test set has two observations only, meaning n= 2. If actual number of readers, 𝑦𝑗 = [10,5] and your model predicts, 𝑦̂ 𝑗 = [8,6] readers then MAE = (½) * (|10-8| + |5-6|) = 1.5.

- Root Mean Squared Error (RMSE)
For the example discussed in the MAE section (IMAGE OF THE FORMULA)
RMSE = ((½) * ( (10-8)^2 + (5-6)^2))^(½) = 1.581.
Perhaps the most popular evaluation metric used to evaluate regression problems is RMSE. Mean Squared Error (MSE) is similar to MAE, the only difference being that MSE takes the average of the square of the difference between the original values and the predicted values, which eases the process of gradient calculation, penalizes the error terms more, and is unbiased towards the direction of error (since you are squaring). However, this makes it more sensitive to outliers. Mathematically, it is represented as:
- R Squared / Coefficient of Determination
Often used in the case of Linear Regression problems, R squared determines how much of the total variation in Y (dependent variable) is explained by the variation in X (independent variable).
Mathematically, it can be written as:

For the example described above, Yactual = 𝑦𝑗 = [10,5] ; Ypredicted = 𝑦̂ 𝑗 = [8,6] and Ymean = 10+5/2 = 7.5. You can plug these values inside the formula, and you will notice your R squared = 0.6
A higher R-squared is preferable while doing linear regression. The range of R-square is (- ∞,1] (don’t get confused by the name, r-squared, it can be negative as well!). While a high r-square value gives you a sense of the model’s goodness of fit, it shouldn’t be used as the only metric to pick the best model. If you care about the absolute predictions, then it’s probably better to check RMSE/MAE.
Adjusted R Square

The drawback of R-Square is that if you add new predictors (X) to your model, the R-Square value only increases or remains constant. Still, it never decreases because you cannot judge that by increasing the complexity of your model. Are you making it more accurate? That is where Adjusted R-squared comes in; it increases only if the new predictor improves model accuracy. (Python users might have to code this explicitly as of now!)
Clustering Performance Evaluation Metrics
Clustering is the most common form of unsupervised learning. In clustering, you don’t have any labels, just a set of features for observation. You aim to create clusters with similar observations clubbed together and dissimilar observations kept as far as possible. Clustering evaluation is not as trivial as counting the number of errors or the precision and recalls like supervised learning algorithms.
Here, cluster validation is based on similarity or dissimilarity measures, such as the distance between cluster points. If the clustering algorithm separates dissimilar observations apart and similar observations together, then it has performed well. The two most popular evaluation metrics for clustering algorithms are the Silhouette coefficient and Dunn’s Index, which you will explore next.
Silhouette Coefficient

- The Silhouette Coefficient is defined for each sample and is composed of two scores:
- a: The mean distance between a sample and all other points in the same cluster.
- b: The mean distance between a sample and all other points in the next nearest cluster.
- The Silhouette Coefficient for a set of samples is given as the mean of the Silhouette Coefficient for each sample. The score is between -1 for incorrect clustering and +1 for highly dense clustering. Scores around zero indicate overlapping clusters. The score is higher when clusters are dense and well separated, which relates to a standard cluster concept.
Dunn’s Index
- Dunn’s Index (DI) is another metric for clustering algorithm evaluation. Dunn’s Index equals the minimum inter-cluster distance divided by the maximum cluster size. Large inter-cluster distances (better separation) and smaller cluster sizes (more compact clusters) lead to a higher DI value. A higher DI implies better clustering. It assumes that better clustering means that clusters are compact and well-separated from other clusters.
Conclusion
This comprehensive article discusses fundamental machine learning and clustering techniques, evaluation metrics, and clustering methods, elucidating their significance. It aimed to empower readers to select an appropriate number of clusters, discuss different clusters and their evaluation methods for their use cases, and accurately assess the efficacy of machine learning models.
Unlock the secrets to accurate machine learning evaluations! Join our ‘Quick Guide to Evaluation Metrics‘ course to master confusion matrices, regression metrics, and clustering evaluations. Enroll now and elevate your data science skills!
Key Takeaways
- Understanding the significance of evaluation metrics in machine learning, including classification, regression, and clustering.
- Familiarity with essential evaluation metrics such as accuracy, precision, recall, F1 score, ROC curve, and PR curve.
- This paper provides insight into clustering evaluation methods like the Silhouette coefficient and Dunn’s Index, aiding in assessing the quality of clustering algorithms.
Frequently Asked Questions
Q1.What Is Cluster Analysis In Data Mining?
Cluster analysis in data mining is grouping data points into clusters based on similarity, aiming to uncover patterns and structures within the data.
Q2.How do the Clustering Algorithms Differ?
Clustering algorithms differ based on their approach to defining similarity, handling noise, scalability, and cluster shape assumptions, impacting their suitability for different data types and applications.
Q3.How do we measure elapsed time in Python?
Elapsed time in Python can be measured using the time module’s functions time() for the current time in seconds since epoch and time_ns() for nanoseconds.
Q4.What metrics can be used to assess the quality of a clustering algorithm’s output?
Common metrics for clustering algorithm assessment include silhouette score, Davies–Bouldin index, and inter-cluster distance measures such as cohesion and separation, evaluating cluster compactness and separation.
Q5.How do you validate clustering algorithms?
Clustering algorithms can be validated using metrics such as silhouette score, Davies–Bouldin index, visual inspection of cluster separation and compactness, or by comparing clusters with ground truth labels.






EXCELLENT WORK... The beauty of the article can be reflected by the style of presenting it.. Really mind-blowing, super, awesome, keep it up.