Introduction
By 2025, the world’s data will grow to 175 Zettabytes – IDC
The overall amount of data is growing and so is the unstructured data. It is estimated that about 80% of data in the universe constitutes unstructured data. Unstructured data is the data that doesn’t fit into any data model. They are as diverse as they can be – be it an image, audio, text, and many more. Industries makes effort to leverage these unstructured data as they can contain a vast amount of information. This information can be used for extensive analysis and effective decision making.
Web scraping is a method by which we can automate the information gathering over the internet. While it can be a go-to approach for gathering the text data and converting it into a tabular meaningful bundle, it can come with its own challenges as well. Two major challenges are variety and durability. Also, we should be respectful while scraping the data as some sites may not allow scraping. Make sure to not violate any terms of services! We can web scrape in Python using several methods. We will discuss how we can use selenium for web scraping effectively, to crawl a website and get the data in a tabular representation.
Selenium Overview
Selenium is a powerful browser automation tool. It supports various browsers like Firefox, Chrome, Internet Explorer, Edge, Safari. Webdriver is the heart of Selenium Python. It can be used to perform various operations like automating testing, perform operations on-webpage elements like close, back, get_cookie, get_screenshot_as_png, get_window_size to name a few. Some common use-cases of using selenium for web scraping are automating a login, submitting form elements, handling alert prompts, adding/deleting cookies, and much more. It can handle exceptions as well. For more details on Selenium, we can refer to the official documentation
Let’s deep dive into the world of selenium right away!
Installation
Assuming that Python is installed in the system, we can install the below library using pip/conda
pip install selenium
OR
conda install selenium
We will be using a Google Chrome driver. We can download it from this site: https://chromedriver.chromium.org/downloads
Implementation
1. Import packages
We need selenium webdriver, time and pandas Python packages
from selenium import webdriver import time import pandas as pd
2. Declare Variables
We need to define variables to make it easier for later use. We will use actual paths. The below paths are shown only as a reference
FILE_PATH_FOLDER = 'F:....Blogathon'
search_query = 'https://www.indeed.com/q-data-scientist-jobs.html'
driver = webdriver.Chrome(executable_path='C:/.../chromedriver_win32/chromedriver.exe')
job_details = []
3. Hit the required URL to get the necessary information
We need to get the specific web element tags for getting the correct information. You can obtain this by doing a right-click on the page and click on inspect. We can click on the arrow in the top left corner or Ctrl+Shift+C to inspect a particular element and get the necessary HTML tag. A good or professional HTML site contains a unique identifier for almost all the tags associated with the information. We will leverage this property to scrape the web page
driver.get(search_query)
time.sleep(5)
job_list = driver.find_elements_by_xpath("//div[@data-tn-component='organicJob']")
4. Get job info from the job list
We aim to fetch job title, job company, job location, job summary, and job publishes date. We will iterate the job list element and extract the required information using find_elements_by_xpath attribute of the selenium web driver. Once the iteration is over, we will quit the driver to close the browser
for each_job in job_list:
# Getting job info
job_title = each_job.find_elements_by_xpath(".//h2[@class='title']/a")[0]
job_company = each_job.find_elements_by_xpath(".//span[@class='company']")[0]
job_location = each_job.find_elements_by_xpath(".//span[@class='location accessible-contrast-color-location']")[0]
job_summary = each_job.find_elements_by_xpath(".//div[@class='summary']")[0]
job_publish_date = each_job.find_elements_by_xpath(".//span[@class='date ']")[0]
# Saving job info
job_info = [job_title.text, job_company.text, job_location.text, job_summary.text, job_publish_date.text]
# Saving into job_details
job_details.append(job_info)
driver.quit()
5. Save the data in a CSV file
We will add proper columns to the dataframe and use the to_csv attribute of the dataframe to save it as CSV
job_details_df = pd.DataFrame(job_details)
job_details_df.columns = ['title', 'company', 'location', 'summary', 'publish_date']
job_details_df.to_csv('job_details.csv', index=False)
Output
The following CSV file will be downloaded in FILE_PATH_FOLDER variable and it will look like this-
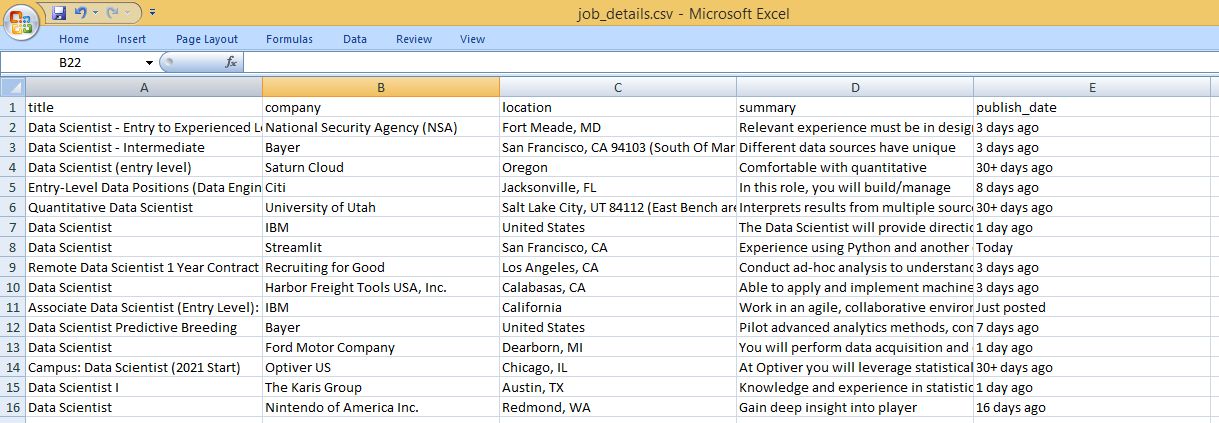
Conclusion
So, this is one of the ways by which we can scrape the data. There are numerous other packages/libraries for web scraping other than selenium and umpteen number of methods/ways by which we can achieve the desired objective. Hope that this article helped you in exploring something new. Do share your thoughts and ways by which it helped you. Open to suggestions for improvement as well.







What would be the pros/cons of using this over Beautiful Soup?
Thanks for your question. While there are other libraries for web-scraping like Scrapy and BeautifulSoup, here is my bit of pros/cons - Pros 1. Selenium can scrape dynamic contents. BeautifulSoup can scrape static contents only. 2. Selenium can be used stand alone. BeautifulSoup, however, depends on other libraries to work. Example: depends on requests module, html parser etc. 3. Selenium is faster than BeautifulSoup Cons 1. BeautifulSoup is a beginner friendly tool. Easy to use than selenium 2. For smaller projects, BeautifulSoup is a go-to choice. For complex projects however, selenium or scrapy will be a good option Also, would like to mention that no library alone always has pros only or cons only. It depends on project requirements and use-cases to make a choice of any particular tool or library.
Hi Adil, Thanks for your question. While there are other libraries for web-scraping like Scrapy and BeautifulSoup, here is my bit of pros/cons - Pros 1. Selenium can scrape dynamic contents. BeautifulSoup can scrape static contents only. 2. Selenium can be used stand alone. BeautifulSoup, however, depends on other libraries to work. Example: depends on requests module, html parser etc. 3. Selenium is faster than BeautifulSoup Cons 1. BeautifulSoup is a beginner friendly tool. Easy to use than selenium 2. For smaller projects, BeautifulSoup is a go-to choice. For complex projects however, selenium or scrapy will be a good option Also, would like to mention that no library alone always has pros only or cons only. It depends on project requirements and use-cases to make a choice of any particular tool or library.
Thank you for the article. It is quite informative.
Thank you for the detailed information