Introduction

Sentiment Analysis or opinion mining is the analysis of emotions behind the words by using Natural Language Processing and Machine Learning. With everything shifting online, brands and businesses giving utmost importance to customer reviews, and due to this sentiment analysis has been an active area of research for the past 10 years. Businesses are investing hugely to come up with an efficient sentiment classifier.
Why Fine-Grained Sentiment Analysis?
On exploring I mostly found those classifiers which use binary classification(just positive and negative sentiment), one good reason as faced by myself is that fine-grained classifiers are a bit more challenging, and also there are not many resources available for this.

It’s attention to detail that makes the difference between average and stunning. If you need more precise results, you can use fine-grained analysis. Simply put, you can not only identify who talks about a product but also what exactly is talked about in their feedback. For example, for comparative expressions like “Scam 1992 was way better than Mirzapur 2.” — a fine-grained sentiment analysis can provide much more precise information than a normal binary sentiment classifier. In addition to the above advantage, dual-polarity reviews like The location was truly bad… but the people there were glorious.” can confuse binary sentiment classifiers giving incorrect predictions.
I think the above advantage will give enough motivation to go for fine-grained sentiment analysis.
How to conduct fine-grained sentiment analysis: Approaches and Tools
Data collection and preparation. For data collection, we scraped the top 100 smartphone reviews from Amazon using python, selenium, and beautifulsoup library. If you don’t know how to use python and beautifulsoup and request a library for web-scraping here is a quick tutorial. Selenium Python bindings provide a simple API to write functional/acceptance tests using Selenium WebDriver.
Let’s begin coding now!!
import requests from fake_useragent import UserAgent import csv import re from selenium import webdriver from bs4 import BeautifulSoupfrom selenium import webdriver
We begin by importing some libraries. the requests library is used to sent requests to the URL and receive the content of the webpage. BeautifulSoup is used to format the content of the webpage in a more readable format. selenium is used to automate the process of scraping web-page without selenium you have to send the headers and cookies and I found that process more tedious.
Searching for products and getting the ASIN(Amazon Standard Identification Number)
Now we will create helper functions that are based on the searched query gets the ASIN number of all the products. These ASIN numbers will help us to create the URL of each product later. We created two functions searching() and asin() which searches for the webpage and stores all the ASIN numbers in a list. We found that when we search for a particular product on amazon. in then its URL can be broken into three parts.
“https://www.amazon.in/s?k=” + search query+ page number. So we searched for a smartphone and till 7pages, you can extend this to any number of pages as you like it.
def searching(url,query,page_no): """ This is a function which searches for the page based on the url and the query Parameters : url = main site from which the data to be parsed query = product/word that to be searches returns : page if found or else error """ path = url + query +"&page=" + str(page_no) page = requests.get(path, headers =header) if page.status_code == 200: return page.content else: return "Error"def asin(url,query,page_no): """ Get the ASIN(Amzon Standard Identification Number for the products) Parameters: url = main url from where the asin needs to be scraped query = product category from which the asins to be scraped returns : list of asins of the products """ product_asin = [] response = searching(url,query,page_no) soup = BeautifulSoup(response,'html.parser') for i in soup.find_all("div",{"class":"sg-col-20-of-24 s-result-item s-asin sg-col-0-of-12 sg-col-28-of-32 sg-col-16-of-20 sg-col sg-col-32-of-36 sg-col-12-of-16 sg-col-24-of-28"}): product_asin.append(i['data-asin']) return product_asin
Getting product details
Now the next step is to create a URL for each product and go to that URL and scrape all the necessary details we need for that page. For this, we use selenium to automate the process of extracting details. For amazon. in the URL for each product can be broken down as
“https://www.amazon.in/dp/”+asin
We then created a function to go to each of the URLs made using asin numbers and get the reviews, ratings, names of each of the products. Then we store these values as a CSV file using the CSV module in python.
Pre-processing and Exploratory Data Analysis.
Loading the saved CSV file using the pandas library and some EDA like distribution of ratings, count of words in reviews and which words are more dominant in positive reviews and negative reviews are done and then preprocessing like cleaning of reviews and title, etc is done.
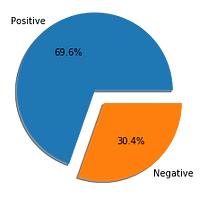
Distribution of positive and negative scores in the dataset.
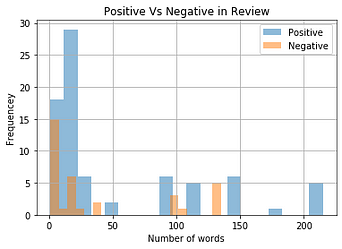
The above graph shows the distribution of the number of words in positive and negative reviews. We can see that the frequency of the number of words is greater in positive reviews than that of negative reviews and also negative reviews are generally shorter in comparison to positive reviews.

Positive Reviews
We can’t make much out of this maybe because of the smaller dataset but we can notice that the word “good” which can be positive is one of the dominant words in positive reviews.

Negative Review
In the above word cloud “don’t, buy, phone” are dominant words here.
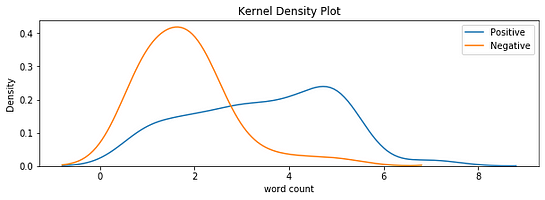
Word Count
For negative word count, a normal distribution graph is clearly visible but for a positive review, there is no clear pattern.
Textblob for fine-grained sentiment analysis:
TextBlob is a python library for Natural Language Processing (NLP). TextBlob actively uses Natural Language ToolKit (NLTK) to accomplish its tasks. NLTK is a library that gives easy access to a lot of lexical resources and allows users to work with categorization, classification, and many other tasks. TextBlob is a simple library that supports complex analysis and operations on textual data.
We will create a function that returns the polarity score of sentiment and then use this function to predict the sentiment score from 1–5.
from textblob import TextBlob
def textblob_score(sentence):
return TextBlob(sentence).sentiment.polarity
Pass each review to the above function and store the score returned and save it to the dataframe.
You can check my GitHub code for complete code and data.
About the Author
Akshay Patel
A life long learner and gamer, Akshay spends most of his time learning new skills and enhancing existing skills. A self-taught data scientist.




{kind=link}
{kind=link}