This article was published as a part of the Data Science Blogathon.
Introduction
This article outlines the motivation behind MLOps, its relation to DevOps, and the different components that comprise an MLOps framework. The article is arranged as follows:
- MLOps motivation
- MLOps challenges similar to DevOps
- MLOps challenges different from DevOps
- MLOps components
1. MLOps Motivation
Machine Learning (ML) models built by data scientists represent a small fraction of the components that comprise an enterprise production deployment workflow, as illustrated in Fig. 1 [1]. To operationalize ML models, data scientists are required to work closely with multiple other teams such as business, engineering, and operations. This represents organizational challenges in terms of communication, collaboration, and coordination. The goal of MLOps is to streamline such challenges with well-established practices. Additionally, MLOps brings about agility and speed that is a cornerstone in today’s digital world.
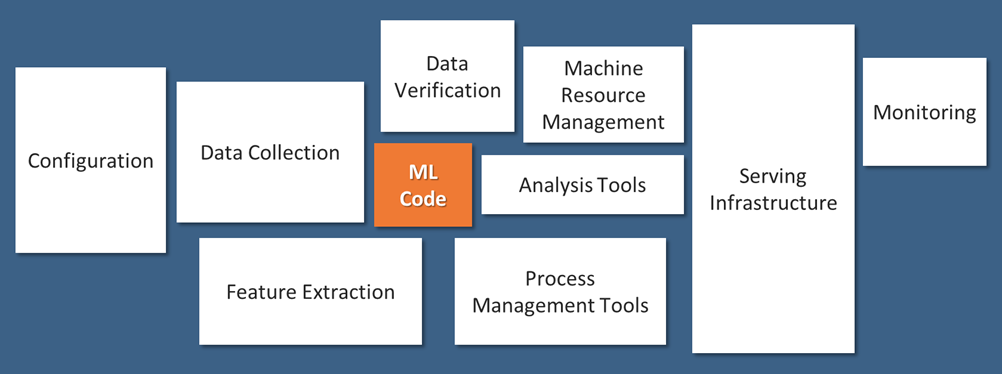
Fig. 1: Only a small fraction of real-world ML systems are composed of the ML code, as shown by the small box in the middle. The required surrounding infrastructure is vast and complex.
2. MLOps challenges similar to DevOps
The challenges of ML model operationalization have a lot in common with software production, where DevOps has proven itself. Therefore, adopting the best practices from DevOps is a prudent approach to help data scientists overcome challenges common to software production. For example, the use of agile methodology promoted by DevOps in contrast to waterfall methodology is an efficiency boost. Additional DevOps practices used in MLOps are listed in Table 1.
Table 1: MLOps leveraging DevOps

3. MLOps challenges different from DevOps
According to industry parlance, MLOps is DevOps for ML. While it is true to some extent, there are challenges typical to ML that need to be addressed by MLOps platforms.
An example of such a challenge is the role of data. In traditional software engineering (i.e., software 1.0), developers write logic/rules (as code) that are well defined in the program space, as demonstrated in Fig. 2 [2]. However, in machine learning (i.e., software 2.0), data scientists write code
that defines how to use parameters to solve a business problem. The parameter values are found using data (with techniques such as gradient descent). These values may change with different versions of the data, thereby changing the code behavior. In other words, data plays an equally important role as the written code in defining the output. And both can change, independent of each other. This adds a layer of data complexity in addition to the model code as an intrinsic part of the software that needs to be defined and tracked.
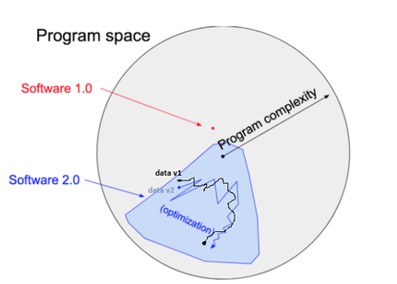
Fig. 2: Software 1.0 vs Software 2.0
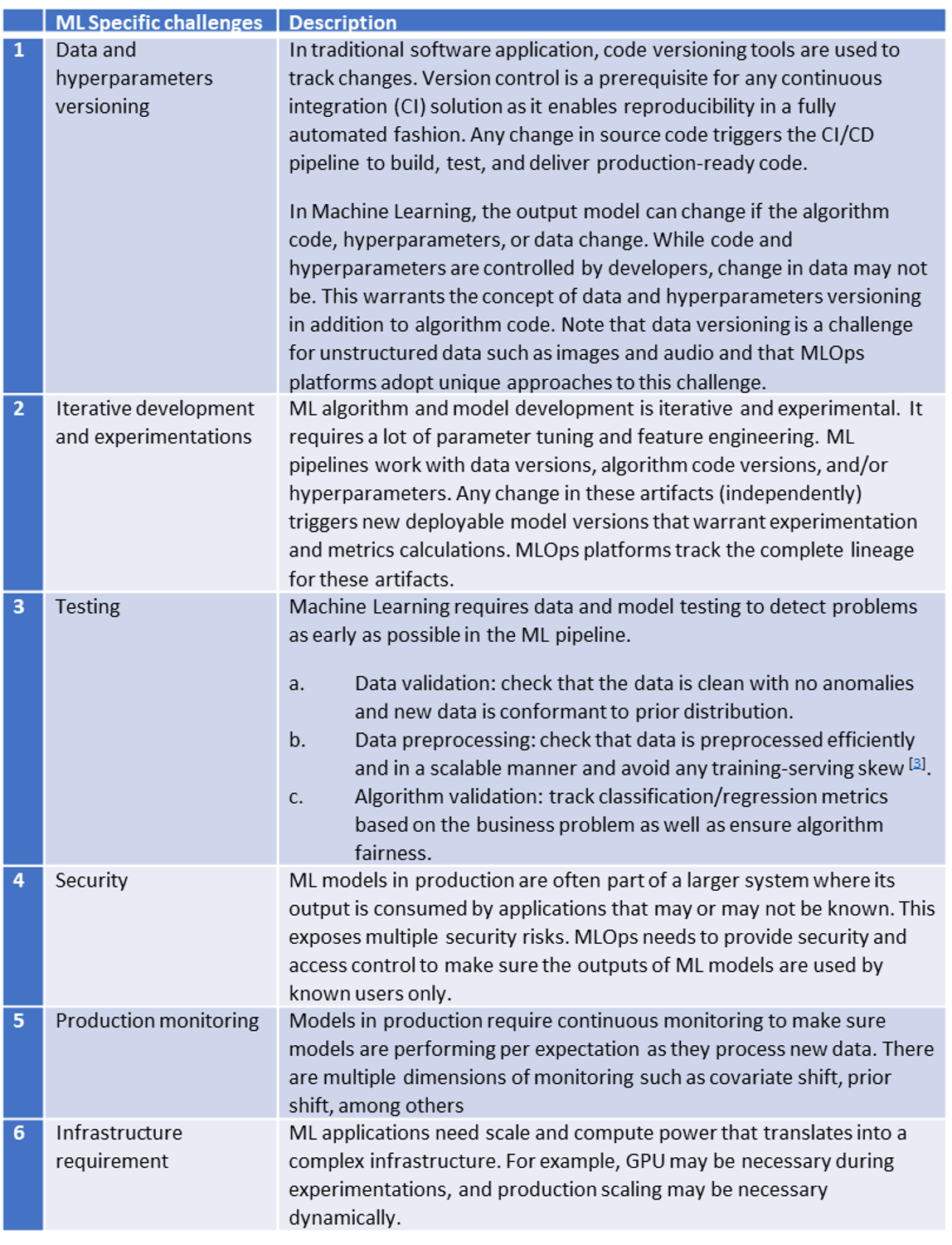
The various challenges that need to be taken care of by the MLOps platform are listed in Table 2.
Table 2: ML specific challenges
4. MLOps Components
With the background in MLOps, its similarity to, and the difference from DevOps, the following describes different components that comprise an MLOps framework, as shown in Fig. 3. The underlying theme of the workflow is an agile methodology, as indicated in Section 2.
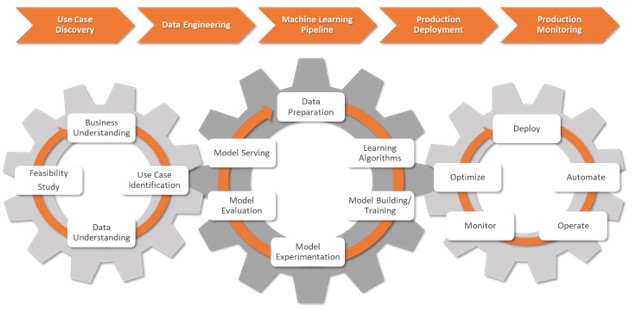
Fig. 3: MLOps Framework
- Use case discovery: This stage involves collaboration between business and data scientists to define a business problem and translate that into a problem statement and objectives solvable by ML with associated relevant KPIs (Key Performance Indicator).
- Data Engineering: This stage involves collaboration between data engineers and data scientists to acquire data from various sources and prepare the data (processing/validation) for modeling.
- Machine Learning pipeline: This stage is designing and deploying a pipeline integrated with CI/CD. Data scientists use pipelines for multiple experimentation and testing. The platform keeps track of data and model lineage and associated KPIs across the experiments.
- Production deployment: This stage accounts for secure and seamless deployment into a production server of choice, be it public cloud, on-premise, or hybrid.
- Production monitoring: This stage includes both model and infrastructure monitoring. Models are continuously monitored using configured KPIs like changes in input data distribution or changes in model performance. Triggers are set for more experimentations with new algorithms, data, and/or hyperparameters that generate a new version of the ML pipeline. Infrastructure is monitored as per memory and compute requirements and is to be scaled as needed.
References
- D. Sculley, G. Holt, D. Golovin, E. Davydov, T. Phillips, D. Ebner, V. Chaudhary, M. Young, J. Crespo, and D. Dennison, “Hidden technical debt in machine learning systems”, in Advances in Neural Information Processing Systems 28: Annual Conference on Neural Information Processing Systems 2015, December 7-12, 2015, Montreal, Quebec, Canada, 2015, pp. 2503–2511. [Online]. Available: http://papers.nips.cc/paper/5656-hidden-technical-debt-in-machine-learning-systems
- A. Karpathy, “Software 2.0”, November 12, 2017 [Online]. Available: https://medium.com/@karpathy/software-2-0-a64152b37c35
- E. Breck, M. Zinkevich, N. Polyzotis, S. Whang and S. Roy, “Data validation for machine learning”, in Proceedings of the 2nd SysML Conference, Palo Alto, CA, USA, 2019. Available: https://mlsys.org/Conferences/2019/doc/2019/167.pdf
Author
Arnab Bose, Chief Scientific Officer, Abzooba
Aditya Aggarwal, Advanced Analytics Practice Lead, Abzooba





