Introduction
Survival analysis is a statistical method essential for analyzing time-to-event data, widely employed in medical research, economics, and various scientific disciplines. At the core of survival analysis is the Kaplan-Meier estimator, a powerful tool for estimating survival probabilities over time. This article provides a concise introduction to survival analysis, unraveling its significance and applications. We delve into the fundamentals of the Kaplan-Meier estimator, exploring its role in handling censored data and creating survival curves. Whether you’re new to survival analysis or seeking a refresher, this guide navigates through the key concepts, making this statistical approach accessible and comprehensible.
This article was published as a part of the Data Science Blogathon.
Table of contents
- Introduction
- What is Survival Analysis?
- Censoring/ Censored Observation
- Kaplan Meier Estimator
- Assumptions of Kaplan Meier Survival
- Important things to consider for Kaplan Meier Estimator Analysis
- Let us take the example in Python
- Advantages & Dis-Advantages of Kaplan Meier Estimator
- Conclusion
- Frequently Asked Questions
What is Survival Analysis?
Survival analysis explores the time until an event occurs, answering questions about failure rates, disease progression, or recovery duration. It’s a crucial statistical field, involving terms like event, time, censoring, and various methods like Kaplan-Meier curves, Cox regression models, and log-rank tests for group comparisons. This branch delves into modeling time-to-event data, offering insights into diverse scenarios, from medical diagnoses to mechanical system failures. Understanding survival analysis requires defining a specific time frame and employing various statistical tools to analyze and interpret data effectively.
Event, when we talk about, is the activity which is going on or is going to happen in the survival analysis study like the Death of a Person from a particular disease, time to get cure by a medical diagnose, time to get cured by vaccines, time of occurrence of failure of machines in the manufacturing shop floor, time for diseases occurrence, etc.
Time
in survival analysis case study is the time from the beginning of the survival analysis observation on the subject matter till the time when the event is going to occur. Like in the case of Mechanical Machine to a failure we need to know the
(a) time of an event when the machine will start
(b) when the machine will fail
(c) loss of machine or the shutdown of the machine from the survival analysis study.
Censoring/ Censored Observation
This terminology is defined as if the subject matter on which we are doing the study of survival analysis doesn’t get affected by the defined event of study, then they are described as censored. The censored subject might also not have an event after the end of the survival analysis observation. The subject is called censored in the sense that nothing was observed out of the subject after the time of censoring.
Censoring Observation are also of 3 types-
1. Right Censored
Right censoring is used in many problems. It happens when we are not certain what happened to people after a certain point in time.
It occurs when the true event time is greater than the censored time when c < t. This happens if either some people cannot be followed the entire time because they died or were lost to follow up or withdrew from the study.
2. Left Censored
Left censoring is when we are not certain what happened to people before some point in time. Left censoring is the opposite, occurring when the true event time is less than the censored time when c > t.
3. Interval Censored
Interval censoring is when we know something has happened in an interval (not before starting time and not after ending time of the study) but we do not know exactly when in the interval it happened.
Interval censoring is a concatenation of the left and right censoring when the time is known to have occurred between two-time points
Survival Function S (t): This is a probability function that depends on the time of the study. The subject survives more than time t. The Survivor function gives the probability that the random variable T exceeds the specified time t.
Here, we will discuss the Kaplan Meier Estimator.
Kaplan Meier Estimator
Kaplan Meier Estimator is used to estimate the survival function for lifetime data. It is a non-parametric statistics technique. It is also known as the product-limit estimator, and the concept lies in estimating the survival time for a certain time of like a major medical trial event, a certain time of death, failure of the machine, or any major significant event.
There are lots of examples like
- Failure of machine parts after several hours of operation.
- How much time it will take for COVID 19 vaccine to cure the patient.
- How much time is required to get a cure from a medical diagnosis etc.
- To estimate how many employees will leave the company in a specific period of time.
- How many patients will get cured by lung cancer
To Estimate the Kaplan Meier Survival we first need to estimate the Survival Function S (t) is the probability of event time t
Where (d) are the number of death events at the time (t), and (n) is the number of subjects at risk of death just prior to the time (t).
Assumptions of Kaplan Meier Survival
In real-life cases, we do not have an idea of the true survival rate function. So in Kaplan Meier Estimator we estimate and approximate the true survival function from the study data. There are 3 assumptions of Kaplan Meier Survival
- Survival Probabilities are the same for all the samples who joined late in the study and those who have joined early. The Survival analysis which can affect is not assumed to change.
- Occurrence of Event are done at a specified time.
- Censoring of the study does not depend on the outcome. The Kaplan Meier method doesn’t depend on the outcome of interest.
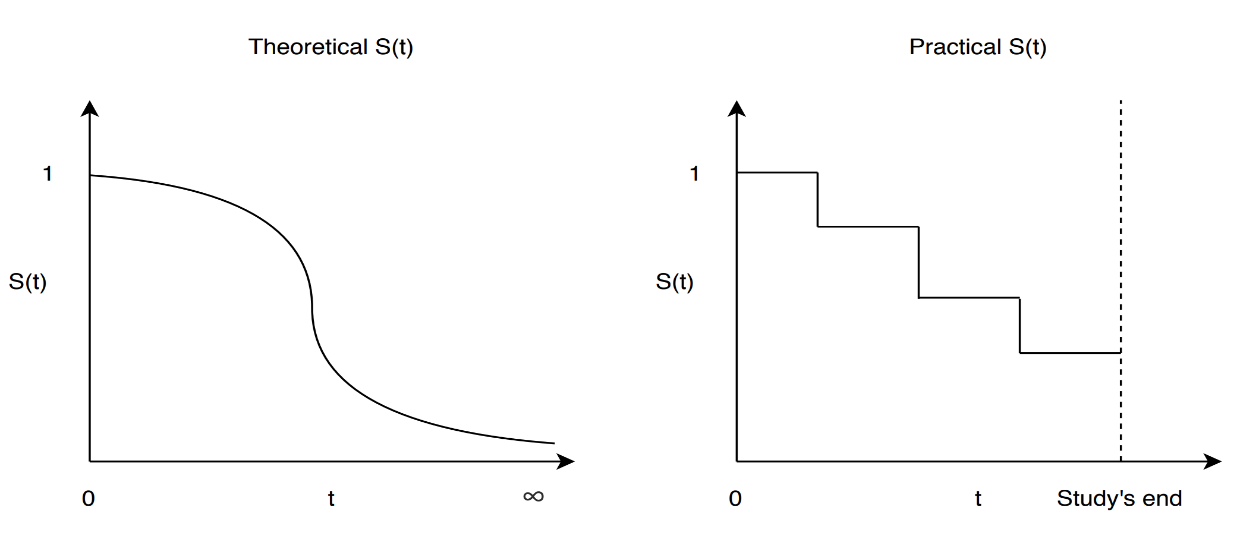
Interpretation of Survival Analysis is Y-axis shows the probability of subject which has not come under the case study. The X-axis shows the representation of the subject’s interest after surviving up to time. Each drop in the survival function (approximated by the Kaplan-Meier estimator) is caused by the event of interest happening for at least one observation.
The plot is often accompanied by confidence intervals, to describe the uncertainty about the point estimates-wider confidence intervals show high uncertainty, this happens when we have a few participants- occurs in both observations dying and being censored.
Important things to consider for Kaplan Meier Estimator Analysis
- We need to perform the Log Rank Test to make any kind of inferences.
- Kaplan Meier’s results can be easily biased. The Kaplan Meier is a univariate approach to solving the problem
- Removal of Censored Data will cause to change in the shape of the curve. This will create biases in model fit-up
- Statistical tests and observations become mislead if the Dichotomizing of Continuous Variable is performed.
- By dichotomizing means we take statistical measures such as median to create groups but this may lead to problems in the data set.
Let us take the example in Python
Link to Notebook- (https://drive.google.com/file/d/1VGKZNViDbx4rx_7lGMCA6dgU3XuMKGVU/view?usp=sharing)
Let us import the important library required to work in python
First, we are importing different python libraries for our work. Here, we are taking the lung-cancer data set. After the libraries and load, we will read the data using the pandas library. The data set contains different information
Treatment 1=standard, 2=test, Cell type 1=squamous, 2=small
cell, 3=adeno, 4=large, Survival in days, Status 1=dead, 0=censored, Karnofsky score (a measure of general performance, 100=best), Months from Diagnosis, Age in years Prior therapy 0=no, 10=yes, etc.
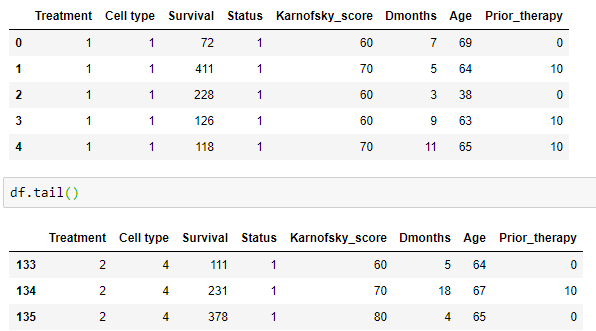
Here we see the Head &tail.
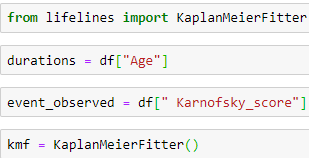
Now, Here we import the python code for performing the Kaplan Meier Estimator
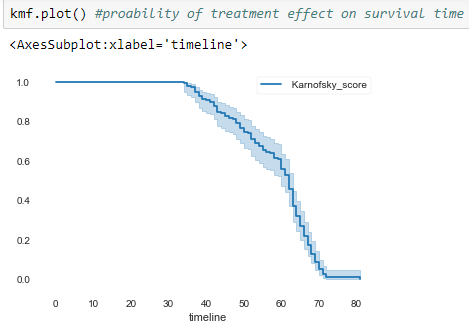
Here, we perform the analysis on the Karnofsky score it x-axis depicts the timeline and the y-axis shows the score. The best score is 1 it means the subject is fit, a score of 0 means the worst score.
Then we apply the code for Survival, Prior Therapy, the treatment here we will do the Kaplan Meier Estimator Analysis.
Then, we fit up kmf1 = KaplanMeierFitter() for fitting up the Kaplan Meier function and we run the following code for different data related to the lung cancer problems.

Kaplan Meier estimator after running the code shows the plot between Treatment test standard &Treatment test.
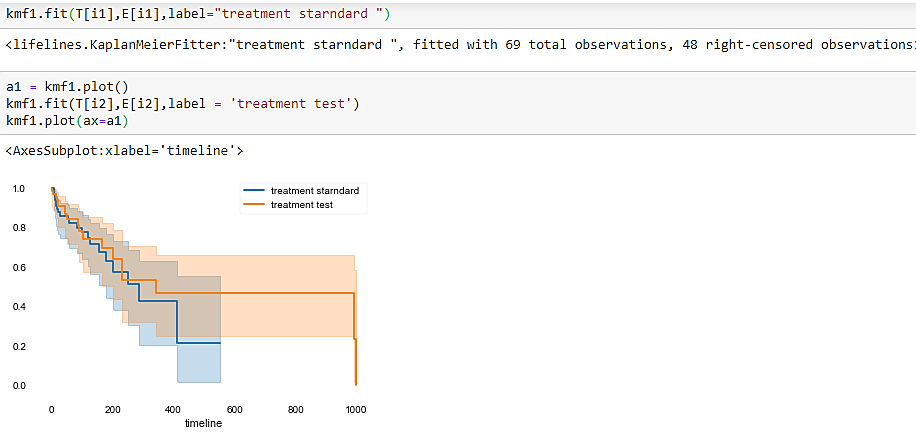
In this paper, my key objective was to explain the Survival Analysis with Kaplan Meier Estimator. The things related to it and a problem description in real life.
Advantages & Dis-Advantages of Kaplan Meier Estimator
Advantages
- Does not require too many features- time to the survival analysis event is only required.
- Provides an average overview related to the event.
Disadvantages
- Lots of variables cannot be correlated and monitor simultaneously.
- If censoring data is removed the model will get biased at the time of fitting.
- The proper estimation of the magnitude of change in the event cannot be predicted.
Conclusion
In conclusion, understanding survival analysis and the Kaplan-Meier estimator opens a gateway to nuanced insights in time-to-event data. The significance of this statistical method transcends disciplines, providing invaluable tools for researchers and analysts. The Kaplan-Meier estimator, with its ability to handle censored data and generate survival curves, stands as a cornerstone in unraveling temporal patterns. As we navigate the diverse applications and implications of survival analysis, this brief guide serves as a stepping stone for both beginners and seasoned analysts, fostering a deeper appreciation for the intricacies of time-dependent phenomena in various fields. Embrace the power of survival analysis and the Kaplan-Meier estimator to decipher the narratives hidden within temporal data.
Frequently Asked Questions
Q1. What are the assumptions of Kaplan-Meier test?
A. The assumptions of Kaplan-Meier test include non-informative censoring, independence of survival times, and no competing risks, ensuring accurate survival estimates in the presence of censored data.
Q2. What are the assumptions for survival analysis?
A. Survival analysis assumes censoring is non-informative, survival times are independent, and the hazard function is constant over time, ensuring reliable results in analyzing time-to-event data.
Q3. What are the requirements for Kaplan-Meier analysis?
A. Kaplan-Meier analysis requires time-to-event data, information on event occurrence, and censored observations. It is suitable for analyzing survival or failure times in medical or experimental studies.
Q4. What are the limitations of Kaplan-Meier survival analysis?
A. Limitations include the inability to handle time-varying covariates, assuming proportional hazards, and sensitivity to the timing of events, affecting its applicability in certain scenarios





