This article was published as a part of the Data Science Blogathon.
Overview:
- Feature engineering is one of the most critical steps of the data science life cycle.
- We’ll discuss how pandas make it easier to perform feature engineering with just one-liner functions.
Introduction:
Pandas is an open-source, high-level data analysis and manipulation library for Python programming language. With pandas, it is effortless to load, prepare, manipulate, and analyze data. It is one of the most preferred and widely used libraries for data analysis operations. Pandas have easy syntax and fast operations. It can handle data up to 10,00,000 rows with ease. With pandas Dataframe, it is effortless to add/delete columns, slice, indexing, and dealing with null values.
Now, that we got the basic intuition behind pandas, moving forward, we will be focusing on pandas functioning specifically for feature engineering.

Feature Engineering, as the name suggests, is a technique to create new features from the existing data that could help to gain more insight into the data. One of the principal reasons why it is recommended to perform EDA exhaustively is that we could have a proper understanding of data and the scope to create new features.
There are mainly two reasons for feature engineering:
- Preparing and processing the available data based on the requirement of the machine learning algorithm. Most machine learning algorithms are not compatible with categorical data. So, we need to convert that column to numeric in such a way that all the valid information could be feed to the algorithm.
- Improving the performance of the machine learning models. The end goal of every predictive model is to get the best possible performance. Some of the ways to improve performance are to use the right algorithm and tune the parameters correctly. But personally, I feel creating new features helps the most in improving the performance as we try to give new signals to the algorithm which wasn’t present earlier.
Note: In this article, we will only understand the basic intuition behind each engineering method and function to perform the same. The scope of the functions mentioned is not limited to performing these tasks only but could be used for other data analysis and preprocessing techniques.
Table of Content:
- Getting to know the data
- replace() for Label Encoding
- get_dummies() for One Hot Encoding
- cut() and qcut() for Binning
- apply() for Text Extraction
- value_counts() and apply() for Frequency Encoding
- groupby() and transform() for Aggregation features
- Series.dt() for date and time based features
Getting to know the data:
To understand the concept better, we will be working on the Big Mart Sales Prediction data. The problem is to predict the sales of the products present at different stores in different cities given certain variables. The problem contains data mostly related to the store and the products.
Let’s import the data and the libraries and check the first few rows to understand it better.
The data has 8,523 rows and 12 columns. The target variable is Item_Outlet_Sales.
Note: There are some missing values in variables like Item_weight and Outlet_Size. Imputing these missing values is out of the scope, and will only be focusing on engineering some new features using pandas functions for this blog.
replace() for Label Encoding:
The replace function in pandas dynamically replaces current values with the given values. The new values can be passed as a list, dictionary, series, str, float, and int.
Note: Label encoding should always be performed on ordinal data to maintain the algorithms’ pattern to learn during the modeling phase.
The advantage of using replace() for label encoding is that we can manually specify each group’s rank/order in the category.
Here, we are going to perform label encoding on Outlet_Loaction_Tier that has three unique groups.
Python Code:
#Importing libraries
import pandas as pd
import numpy as np
#Importing and printing data
data = pd.read_csv('train.csv')
print(data.head())
data['Outlet_Location_Type_Encoded'] = data['Outlet_Location_Type'].replace({'Tier 1': 1, 'Tier 2': 2, 'Tier 3': 3})
print(data[['Outlet_Location_Type', 'Outlet_Location_Type_Encoded']].head())Here, we successfully converted the column to a label encoded column and in the right order.
get_dummies() for One Hot Encoding
Get dummies is a function in pandas that helps to convert a categorical variable to one hot variable.
One hot encoding method is converting categorical independent variables to multiple binary columns, where 1 indicates the observation belonging to that category.
One hot encoding is used explicitly for categorical variables that have no natural ordering in between. Example: Item_Type. We give our model signals that milk products are higher than soft drinks if we perform a label encoding on such categorical variables (nominal variables).
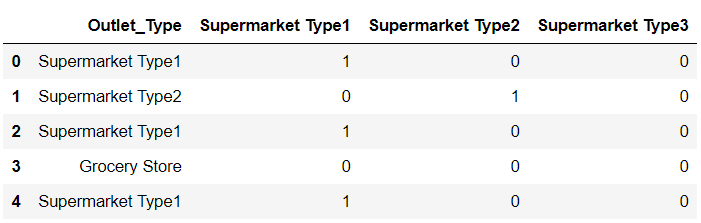
Note: In the code, I have used the parameter drop_first, which drops the first binary column(Grocery Store in our example) to avoid perfect multicollinearity.
Here, value 1 for each new binary column indicates the presence of that sub-category in the original Outlet_Type column.
cut() and qcut() for Binning
Binning is a technique of grouping together values of continuous variables into n number of bins. Binning can also be called a discretization technique as we are dividing or partitioning a continuous variable to a discrete variable.
Sometimes using a discrete variable than a continuous variable is better for some machine learning algorithms. For example: having a continuous variable like age can be used better and more interpretable if we convert it into age brackets. Binning continuous variables also help in nullifying the effect of outliers.
Pandas have two functions to bin variables i.e. cut() and qcut().
qcut(): qcut is a quantile based discretization function that tries to divide the bins into the same frequency groups. If you try to divide a continuous variable into five bins and the number of observations in each bin will be approximately equal.
Let’s try to bin Item_MRP variable from big mart sales using qcut function:
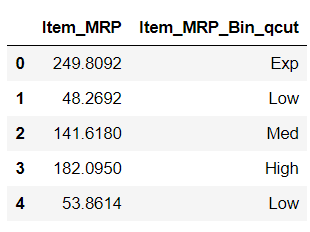
And when we check the frequency of this new variable:
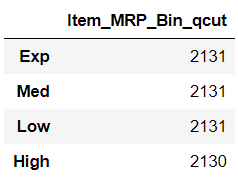
As expected, the distribution of observation is approximately equal for each sub-category of the column.
cut(): The cut function is also used for discretization of a continuous variable. With the qcut function, we aim to keep the number of observations in each of the bins equal, and we don’t specify where we want to make the split preferably just the number of bins required. In the case cut function, we explicitly provide the bin edges. There is no guarantee about the distribution of observation in each bin will be equal.
If we want to bin a continuous variable like age, then binning it based on frequency will not be an appropriate measure to find insights. Instead, we want to specifically divide like from 0-14 as childhood, 15-24 as a youth, and 60+ seniority. In such cases, using a cut function would make more sense than using a qcut function.
Let’s try to bin Item_MRP variable from big mart sales using the cut function:
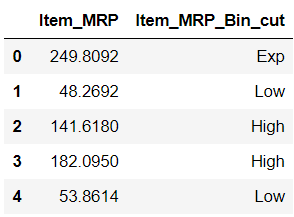
And when we check the frequency of this new variable:
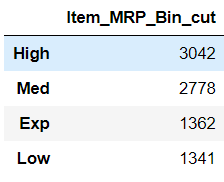
Here, we have explicitly provided the bins, and we can clearly see that each bin has a different number of observations in it.
apply() for Text Extraction:
Pandas apply function allows to pass a function on a pandas Series and pass it to every point of the variable.
It takes a function as an argument and then applies it to either the rows or the columns of the Dataframe. We can pass any function to the argument of the apply function, but I mostly use the lambda function, which helps me write the loops and conditions in a single statement.
Using apply and lambda function, we can extract repeating credentials from the unique text present in a column. For example, we can extract titles from the given names of individuals or extract website names from the Html links. These types of signals help in improving the model performance at the model building stage.
In our Big Mart Sales data, we have a column Item_Identifier which is the unique product id for each product. The first two letters of this variable have three distinctive types, i.e., DR, FD, and NC, representing Drinks, Food Items, and Non-Consumable Items. We can extract these letters and use them as a new variable as Item_Code.
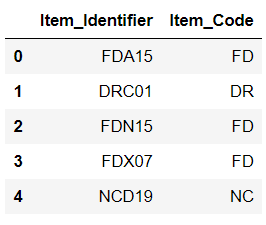
We have successfully created a new categorical variable using apply with a lambda function.
value_counts() and apply() for Frequency Encoding:
If a nominal categorical variable has many categories in it, it is not recommended to use one-hot encoding. There are two primary reasons we don’t prefer one-hot encoding. First, it unnecessarily increases dimensions, and with higher dimensions, the computation time increases. The other reason is the increase in the sparsity of the one-hot encoded binary variables. The variables will have the most values as 0, which affects the performance of the model.
That’s why if we have a nominal categorical variable with a lot of categories, we prefer using frequency encoding.
Frequency Encoding is an encoding technique that encodes categorical feature values to their respected frequencies. This will preserve the information about the values of distributions. We normalize the frequencies that result in getting the sum of unique values as 1.
Here, In our Big Mart Sales data, we will be using frequency encoding on the Item_Type variable, which has 16 unique categories.
groupby() and transform() for Aggregation Features
Groupby is my go-to function to perform different tasks throughout the data analysis, transformation, and pre-processing. Groupby is a function that can split the data into various forms to get information that was not available on the surface. GroupBy allows us to group our data based on different features and get a more accurate idea about your data.
The most useful thing about the groupby function is that we can combine it with other functions like apply, agg, transform, and filter to perform tasks from data analysis to feature engineering. For our purpose, we will be using groupby with transform function to create new aggregating features.
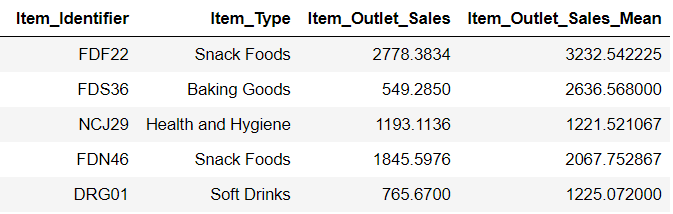
Here, we will be grouping the variables Item_Identifier and Item_Type are will look at the mean Item_Outlet_Sales.
Note: We can perform the groupby function on any categorical variable and perform any aggregation function like mean, median, mode, count, etc.
From the first row, we can understand, if the Item_Identifier is FD22 and Item_Type is Snack Foods, then the mean sales will be 3232.54. And this is how we can create multiple columns. Be careful while performing this type of feature engineering, as there could be chances that your model gets biased as you are using the target variable to create new features.
Series.dt() for date and time based features
Date and Time features are a gold mine for data scientists. The amount of information that we can retrieve through just one date-time variable is surprising at first, but once to get a hold of it, you’ll immediately get your hand dirty the next time we see a date-time variable in your data set.
12-07-2020 01:00:45, look at this date and think of all the possible components this particular date has. From first glance, we can tell we have a day, month, year, hour, minute, and second. But if you emphasize the date, you’ll see that you can also calculate the day of the week, a quarter of the year, week of the year, day of the year, and so on. There is no limit to the number of new variables we can create through this one date-time variable. But not every variable would be useful for the model, and using all of it means increasing dimension and even feeding noise to the model. So, it is essential to extract only those variables relevant to your data problem.
Now that we got the idea of what variables we can extract, the only thing left is to extract those features. To make this process easy, pandas have a dt function using which we can extract all the features we named above and more. I would highly recommend reading the pd.Series.dt documentation to understand what each function does.
Note: The dataset we were working on so far doesn’t have any date-time variable. Here we are using NYC Taxi Trip Duration data to demonstrate how to extract features through date-time variables.
Here, have a glance at the dataset:
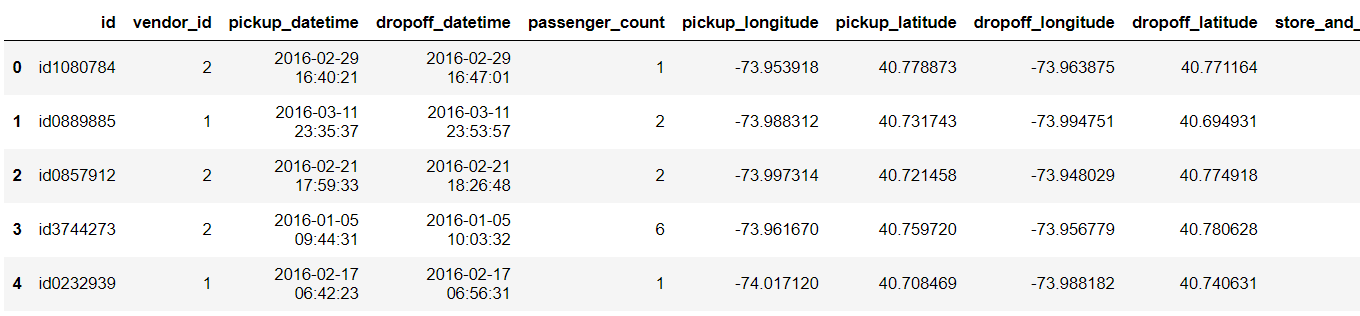
We will be using pickup_datetime to extract features using pandas.
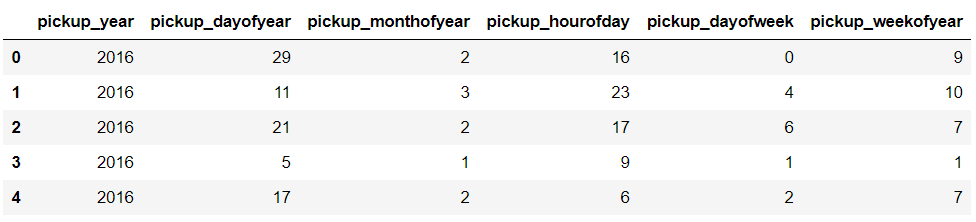
Isn’t it amazing, just by a single date-time variable, we can create six new variables that will surely be very useful at the time of model building.
Note: There are more than 50 different ways we can create new features using pandas dt function. It depends on the problem statement and the frequency of date-time variables (daily, weekly, or monthly data) to decide the new variables to create.
End Notes:
That’s the power of pandas; with just a few code lines, we have created different types of new variables that can boost your model’s performance to another level.
There is no conventional way or type to create new features, but pandas, with their wide variety of functions, make your job much more comfortable. I would highly recommend picking up any of the datasets and try all of the listed techniques on your own and comment below how much and which approach helped you the most. It would be fun to keep this discussion going.







Very well written and informative blog.