This article was published as a part of the Data Science Blogathon.
Introduction
Random Forests are always referred to as black-box models. Let’s try to crack open it and see what is inside it. Are you ready?
BRACE FOR IMPACT! BRACE! BRACE! BRACE!
Oops!!! Our plane has crashed, but fortunately, we all are safe. We are Data scientists, so we want to open the black box and see what random things have been recorded inside it. Yes, let’s come to our topic.
What are Random forests?
You must have at least once solved a problem of probability in your high-school in which you were supposed to find the probability of getting a specific colored ball from a bag containing different colored balls, given the number of balls of each color. Random forests are simple if we try to learn them with this analogy in mind.
Random forests (RF) are basically a bag containing n Decision Trees (DT) having a different set of hyper-parameters and trained on different subsets of data. Let’s say I have 100 decision trees in my Random forest bag!! As I just said, these decision trees have a different set of hyper-parameters and a different subset of training data, so the decision or the prediction given by these trees can vary a lot. Let’s consider that I have somehow trained all these 100 trees with their respective subset of data. Now I will ask all the hundred trees in my bag that what is their prediction on my test data. Now we need to take only one decision on one example or one test data, we do it by taking a simple vote. We go with what the majority of the trees have predicted for that example.
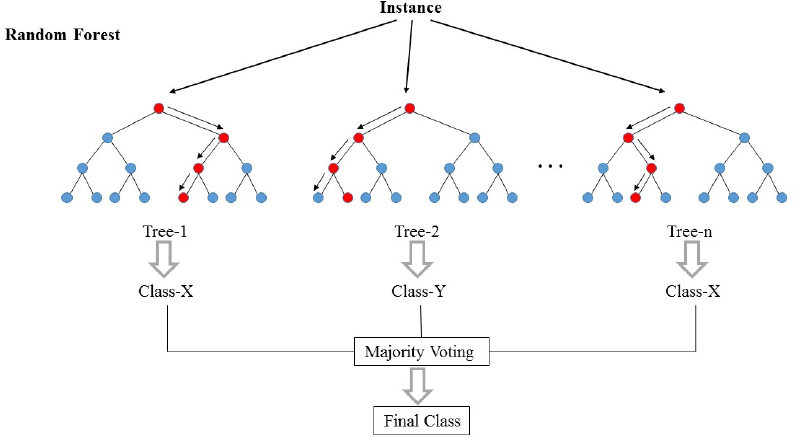
In the above picture, we can see how an example is classified using n trees where the final prediction is done by taking a vote from all n trees.
In machine learning language, RFs are also called an ensemble or bagging method. I think the bagging word might have come from the analogy that we have just discussed !!!
Let’s come a bit closer to ML Jargons!!
The Random forest is basically a supervised learning algorithm. This can be used for regression and classification tasks both. But we will discuss its use for classification because it’s more intuitive and easy to understand. Random forest is one of the most used algorithms because of its simplicity and stability.
While building subsets of data for trees, the word “random” comes into the picture. A subset of data is made by randomly selecting x number of features (columns) and y number of examples (rows) from the original dataset of n features and m examples.
Random forests are more stable and reliable than just a decision tree. This is just saying like- it’s better to take a vote from all cabinet ministers rather than just accepting the decision given by the PM.
As we have seen that the Random Forests are nothing but the collection of decision trees, it becomes essential to know the decision tree. So let’s dive deep into decision trees.
What is a Decision Tree?
In very simple words, it is a “set of rules” created by learning on a dataset that can be used to do predictions on future data. We will try to understand this with one example.

A simple small dataset is shown here. In this dataset, the first four features are independent features and the last one is the dependent features. The independent features describe the weather condition on a given day and the dependent feature tells us whether we were able to play tennis on that day or not.
Now we will try to create some rules using independent features to predict dependent features. Just by observation, we can see that if Outlook is Overcast then the Play is always yes irrespective of other features. Similarly we can create all rules to fully describe the data set. Here are all the rules.
-
- R1: If (Outlook=Sunny) AND (Humidity=High) Then Play=No
- R2: If (Outlook=Sunny) AND (Humidity=Normal) Then Play=Yes
- R3: If (Outlook=Overcast) Then Play=Yes
- R4: If (Outlook=Rain) AND (Wind=Strong) Then Play=No
- R5: If (Outlook=Rain) AND (Wind=Weak) Then Pay=Yes
We can easily convert these rules into a tree chart. Here is the tree chart.
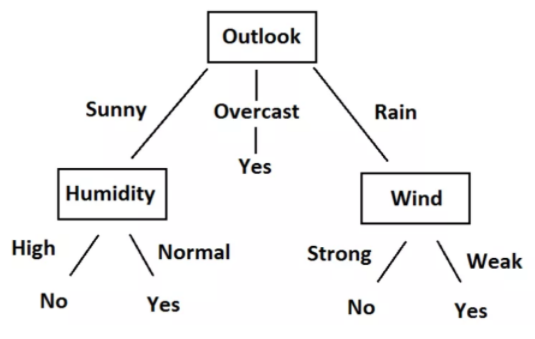
By observing Data, Rules, and Tree, you will understand that we can now predict whether we should play tennis or not, given the situation of the weather based on independent features. This whole process of creating rules for a given data is nothing but the training of the decision tree model.
We could make rules and make a tree by just observation here because the dataset is very small. But how do we train decision tree on a bigger dataset? For that, we need to know a little bit of mathematics. Now will try to understand the mathematics behind the decision tree.
Mathematical concepts behind Decision Tree
This section consists of two important concepts- Entropy and Information gain.
Entropy
Entropy is a measure of the randomness of a system. The entropy of sample space S is the expected number of bits needed to encode the class of a randomly drawn member of S. Here we have 14 rows in our data so 14 members.
Entropy E(S)= -∑p(x)*log2(p(x))
The entropy of the system is calculated by the above formula where p(x) is the probability of getting class x from those 14 members. We have two classes here one is Yes and the Other is No in the Play column. We have 9 Yes and 5 No in our dataset. So entropy calculation here will be as below
E(S)= -[p(Yes)*log(p(Yes))+ p(No)*log(p(No))]=-[(9/14)*log((9/14))+ (5/14*log((5/14)))]=0.94
Information Gain
The information gain is the amount by which the Entropy of the system reduces due to the split that we have done. We have created the tree using observations. But how come we decided that we should first split the data based on Outlook and not on any other feature? The reason is that this split was reducing the entropy by the maximum amount but we did it intuitively in the above example.
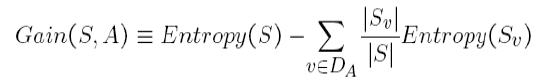

The tree split above shows us that 9 YES and 5 No have been split as (2 Y, 3 N), (4 Y, 0 N), (3 Y, 2 N), when we do the split based on outlook. The E values below every split show entropy values considering themselves as a whole system and using the entropy formula above. Then we have calculated the Information gain for the outlook split by using the above gain formula.
Similarly, we can calculate information gain for each feature split independently. And we get the below results:
-
- Gain(S, Outlook) =0.247
- Gain(S, Humidity) =0.151
- Gain(S, Wind) =0.048
- Gain(S, Temperature) =0.029
We can see that we are getting maximum information gain by splitting on the outlook feature. We repeat this procedure to create the whole tree. I hope you have enjoyed reading the article. If you like the article please share it with your colleagues and friends. Happy Reading!!!







