This article was published as a part of the Data Science Blogathon.
Introduction
The Coca-Cola company has embraced the reuse of its bottles and all the environmental and monetary benefits that come with that. When customers buy a Coke drink in glass bottles, they are rewarded upon returning the empty bottle. This got me thinking about all the plastic bottles and cans that do no warrant a reward leading to them being tossed and wasted. There should be a way of automatically identifying Coca Cola bottles for reuse within the company.
Coca Cola bottles are easily discernable using the labels that have a large, “Coca Cola ” print on them. The print is usually in white. We can get the label by isolating the color white and training the model on the segmented images.
THE DEPENDENCIES
import numpy as np import pandas as pd import matplotlib.pyplot as plt from mpl_toolkits.mplot3d import Axes3D from matplotlib import cm from matplotlib import colors import os import cv2 import PIL from tensorflow.keras.layers import Dense,Conv2D, Dropout,Flatten, MaxPooling2D from tensorflow import keras from tensorflow.keras.models import Sequential, save_model, load_model from tensorflow.keras.optimizers import Adam import tensorflow as tf from tensorflow.keras.preprocessing.image import img_to_array from tensorflow.keras.preprocessing.image import load_img from tensorflow.keras.applications.inception_v3 import InceptionV3, preprocess_input from tensorflow.keras.callbacks import ModelCheckpoint from sklearn.decomposition import PCA
From the top:
- Numpy is used to manipulate array data.
- Matplotlib is used to visualize the images and to show how discernable a color is in a particular range of colors.
- OS is used to access the file structure.
- CV2 is used to read the images and convert them into different color schemes.
- Keras is used for the actual Neural Network.
CONVERTING THE COLOR SCHEME
DETERMINING THE APPROPRIATE COLOR SCHEME:
To be able to isolate the colors, we need to check how well the colors are discernable in different color schemes. We can use 3D plots for this
First, we can visualize the image in RGB color format in 3D space.
Here, we essentially split the image into its components which in this case are red, green, and blue then we set up the 3D plot. The next thing is to reshape the image after which we normalize the image which reduced the range from 0-255 up to 0-1. Finally, the scatter() function is used to create the scatter plot and then we label the axes accordingly.
red, green, blue = cv2.split(img)
fig = plt.figure()
axis = fig.add_subplot(1, 1, 1, projection="3d")
pixel_colors = img.reshape((np.shape(img)[0]*np.shape(img)[1], 3))
norm = colors.Normalize(vmin=-1.,vmax=1.)
norm.autoscale(pixel_colors)
pixel_colors = norm(pixel_colors).tolist()
axis.scatter(red.flatten(), green.flatten(), blue.flatten(), facecolors=pixel_colors, marker=".")
axis.set_xlabel("Red")
axis.set_ylabel("Green")
axis.set_zlabel("Blue")
plt.show()
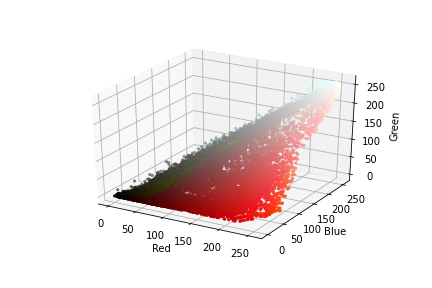
HSL and HSV schemes often serve better for image segmentation. We can plot 3D plots for the image in HSL scheme.
hue, saturation, lightness = cv2.split(img)
fig = plt.figure()
axis = fig.add_subplot(1, 1, 1, projection="3d")
axis.scatter(hue.flatten(), saturation.flatten(), lightness.flatten(), facecolors=pixel_colors, marker=".")
axis.set_xlabel("Hue")
axis.set_ylabel("Saturation")
axis.set_zlabel("Lightness")
plt.show()
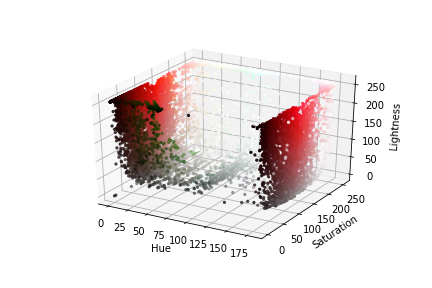
To note is that particular colors are not as jumbled up in the second plot as in the first. We can easily discern the white color pixels from the rest.
CONVERTING THE COLORS
CV2 by default reads images in the BGR scheme.
img = cv2.imread(img_path) plt.imshow(img) plt.show()
This image needs to be converted to RGB format first
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) plt.imshow(img) plt.show()
Finally, this image should be converted to an HLS scheme to allow for ease of discernment of colors. HSL is the description of the Hue, Saturation, and Lightness of an image.
img = cv2.cvtColor(img, cv2.COLOR_RGB2HLS) plt.imshow(img) plt.show()
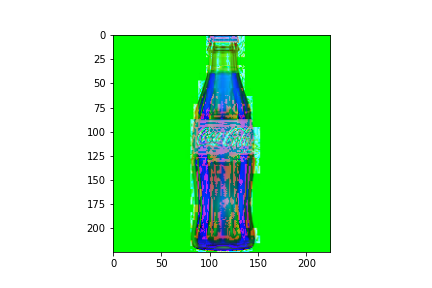
ISOLATE COLOR WHITE:
We specify the lower and higher threshold values for the color white then specify a mask using cv2.inRange() that thresholds the HSL image. This returns 0’s and 1’s. We then impose the mask upon the original RGB image using a bitwise_and function. The implication here is that it will retain the pixel value if the corresponding value of the mask is 1. A Gaussian Blur is applied to smooth out the edges.
hsl_img = cv2.cvtColor(img, cv2.COLOR_RGB2HLS) low_threshold = np.array([0, 200, 0], dtype=np.uint8) high_threshold = np.array([180, 255, 255], dtype=np.uint8) mask = cv2.inRange(hsl_img, low_threshold, high_threshold) white_parts = cv2.bitwise_and(img, img, mask = mask) blur = cv2.GaussianBlur(white_parts, (7,7), 0)
TRANSFER LEARNING WITH INCEPTIONV3
Some models can take very long to train and eventually still have unimpressive predictive accuracy. While it is entirely noble to want to create a model from scratch, transfer learning employs the use of models that have yielded great results on ImageNet images. In this particular project, I will show how to use InceptionV3.
We define the model to be used including the weights, and input shape then fit the values of X into the model and save the resultant values in a variable called “bottle_neck_features_train”.
model = InceptionV3(weights='imagenet', include_top=False, input_shape=(299, 299, 3))
bottle_neck_features_train = model.predict_generator(X, n/32, verbose=1)
bottle_neck_features_train.shape
np.savez('inception_features_train', features=bottle_neck_features_train)
train_data = np.load('inception_features_train.npz')['features']
train_labels = np.array([0] * m + [1] * p) // where m+p = n
The shape of the resultant features is ((n, 8, 8, 2048)), n being the number of images used. We then save the values in a file called ‘inception_features_train.npz’ to avoid repetitive pre-training. The above is a binary classification problem (A bottle is either a Coca Cola Bottle or it isn’t).
It follows that the labels can be either 0 for “Coke” or 1 for “Not Coke”(or any other combination of number pairs). The training labels can be cooked up by creating a series of zeros equal to the number of images of Coke bottles followed by ones for the rest of the images.
THE NEURAL NETWORK
A neural network can be described as a series of algorithms that solve a problem by mimicking the way the human brain works. Here, we employ the Sequential Keras model.
classifier = Sequential() classifier.add(Conv2D(32, (3, 3), activation='relu', input_shape=train_data.shape[1:], padding='same')) classifier.add(Conv2D(32, (3, 3), activation='relu', padding='same')) classifier.add(MaxPooling2D(pool_size=(3, 3))) classifier.add(Dropout(0.25)) classifier.add(Conv2D(64, (3, 3), activation='relu', padding='same')) classifier.add(Conv2D(64, (3, 3), activation='relu', padding='same')) classifier.add(MaxPooling2D(pool_size=(2, 2))) classifier.add(Dropout(0.50)) classifier.add(Flatten()) classifier.add(Dense(512, activation='relu')) classifier.add(Dropout(0.6)) classifier.add(Dense(256, activation='relu')) classifier.add(Dropout(0.5)) classifier.add(Dense(1, activation='sigmoid'))
The input layer is a Convolutional Layer. Parameters used for this layer are the number of filters which is 32, the kernel size which is 3 by 3, the activation function which is Rectified Linear Unit, the input shape which is the shape of one image, and the padding. The input of the first conv2d layer is always a 4D array. The first three dimensions are of the image input and the last is the channels.
Rectified Linear Unit is a non-linear activation function although it acts and appears to be a linear function. It performs calculations that may yield the value-added as input or it may yield zero.
MaxPooling is used for feature extraction. In this case, we set a pool size of 3,3 meaning that the model will extract a 3,3-pixel image and get the maximum value in that pool.
Dropout is used to prevent overfitting. It randomly sets the outgoing edges of hidden units to 0 at each update of the training phase. The difference between overfitting, underfitting, and properly fitted is illustrated below.
The Flatten layer converts input data to a 2D array. The Dense layer ensures that each node of one layer is connected to the other node of the next layer.
We use the Sigmoid activation function for the output layer. The input is converted to a value between 0.0 and 1.0. Inputs that are much larger than 1.0 are transformed to the value 1.0, similarly, values much smaller than 0.0 are snapped to 0.0. The shape of the function for all possible inputs is an S-shape from zero up through 0.5 to 1.0.
To save the model and the weights at particular intervals, we use ModelCheckpoint along with model.fit. Setting ‘save_best_only’ to true ensures that only the model that produced the best results is saved. Finally, we compile the model and fit the data.
checkpointer = ModelCheckpoint(filepath='./weights_inception.hdf5', verbose=1, save_best_only=True) classifier.compile(optimizer='adam',loss='binary_crossentropy',metrics=['binary_accuracy']) history = classifier.fit(train_data, train_labels,epochs=50,batch_size=32, validation_split=0.3, verbose=2, callbacks=[checkpointer], shuffle=True)
PERFORMING PREDICTIONS
Since we need to use data that is similar to the data that was input to the classifier, we can write a function that will do the conversion then make the predictions.
def predict(filepath):
img = cv2.imread(filepath)
img = cv2.resize(img,(299,299))
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
hsl_img = cv2.cvtColor(img, cv2.COLOR_RGB2HLS)
low_threshold = np.array([0, 200, 0], dtype=np.uint8)
high_threshold = np.array([180, 255, 255], dtype=np.uint8)
mask = cv2.inRange(hsl_img, low_threshold, high_threshold)
white_parts = cv2.bitwise_and(img, img, mask = mask)
blur = cv2.GaussianBlur(white_parts, (7,7), 0)
print(img.shape)
clf = InceptionV3(weights='imagenet', include_top=False, input_shape=white_parts.shape)
bottle_neck_features_predict = clf.predict(np.array([white_parts]))[0]
np.savez('inception_features_prediction', features=bottle_neck_features_predict)
prediction_data = np.load('inception_features_prediction.npz')['features']
q = model.predict( np.array( [prediction_data,] ) )
prediction = q[0]
prediction = int(prediction)
print(prediction)
NEXT STEPS
Seeing as how we have the following:
- A working predictive model.
- Saved values for the model.
- Images for prediction.
- A function ready for making predictions.
We can now try and perform predictions on images.
All we need to do is to call the predict function and pass the path to the image as a parameter.
predict("./train/Coke Bottles/Coke1.png")
This should provide 1 as an output since our images of coke bottles we labeled as 1.
SAVING THE MODEL
If this is to be at all applicable in software such as a real-time app that uses OpenCV modules to view an image or video and make predictions, we cannot realistically hope to train our model every time the program is turned on.
Much more logical is to save the model and load it up once the program is opened. This means we need to make use of Keras’ load_model and save_model. We import these as follows.
from tensorflow.keras.models import Sequential, save_model, load_model
Now we can save the model by calling save_model() and entering the folder name as a parameter.
save_model(save_model)
Finally, we can tidy up any program by simply loading the model using load_model rather than entering the code to re-train the model.
load_model("./save_model")
The media shown in this article are not owned by Analytics Vidhya and is used at the Author’s discretion.


