This article was published as a part of the Data Science Blogathon.
Introduction
Naive Bayes is a classification technique based on the Bayes theorem. It is a simple but powerful algorithm for predictive modeling under supervised learning algorithms. The technique behind Naive Bayes is easy to understand. Naive Bayes has higher accuracy and speed when we have large data points.
There are three types of Naive Bayes models: Gaussian, Multinomial, and Bernoulli.
- Gaussian Naive Bayes – This is a variant of Naive Bayes which supports continuous values and has an assumption that each class is normally distributed.
- Multinomial Naive Bayes – This is another variant which is an event-based model that has features as vectors where sample(feature) represents frequencies with which certain events have occurred.
- Bernoulli – This variant is also event-based where features are independent boolean which are in binary form.
Understanding Statistics behind Gaussian Naive Bayes
Gaussian Naive Bayes is based on Bayes’ Theorem and has a strong assumption that predictors should be independent of each other. For example, Should we give a Loan applicant would depend on the applicant’s income, age, previous loan, location, and transaction history? In real life scenario, it is most unlikely that data points don’t interact with each other but surprisingly Gaussian Naive Bayes performs well in that situation. Hence, this assumption is called class conditional independence.
Let’s understand with an example of 2 dice:
Gaussian Naive Bayes says that events should be mutually independent and to understand that let’s start with basic statistics.
- Event A -> Roll 1 on 1st Dice
- Event B -> Roll 1 on 2nd Dice
Let A and B be any events with probabilities P(A) and P(B). Both the events are mutually independent. So if we have to calculate the probability of both the events then:
- P(A) = 1/6 and,
- P(B) = 1/6
- P(A and B) = P(A)P(B) = 1/36
If we are told that B has occurred, then the probability of A might change. The new probability of A is called the conditional probability of A given B.
Conditional Probability:
- P(A|B) = 1/6
- P(B|A) = 1/6
We can say that:
- P(A|B) = P(A and B)/P(B) It can also be written as,
- P(A|B) = P(A) or,
- P(A and B) = P(A)P(B)
OR
- Multiplication rule: P(A and B) = P(A|B) P(B) OR,
- Multiplication rule: P(B and A) = P(B|A)P(A)
We can also write the equation as:
- P(A|B) P(B) = P(B|A)P(A)
This gives us the Bayes theorem:
P(A|B) = P(B|A)P(A)/P(B)
- P(A|B) is the posterior probability of class (A, target) given predictor (B, attributes).
- P(A) is the prior probability of class.
- P(B|A) is the probability of the predictor given class.
- P(B) is the prior probability of the predictor.
- Posterior Probability = (Conditional Probability x Prior probability)/ Evidence
Understanding how Algorithm works
Let’s understand the working of Naive Bayes with an example. consider a use case where we want to predict if a flight would land in the time given weather conditions on that specific day using the Naive Bayes algorithm. Below are the steps which algorithm follows:
- Calculate prior probability for given class labels
- Create a frequency table out of given historical data
- Find likelihood probability with each attribute of each class. For example, given it was Sunny weather, was the flight in time.
- Now put these values into the Bayes formula and calculate posterior probability.
- The class with the highest probability will be the outcome.
Problem: Given the historical data, we want to predict if the flight will land in time if the weather is Dusty?
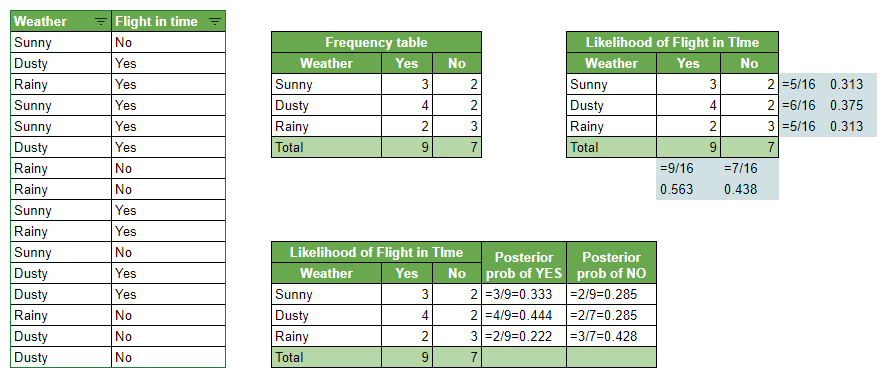
Probability of Flight arriving in time:
P(Yes | Dusty) = P( Dusty | Yes) * P(Yes) / P(Dusty)
1. Calculating Prior probability
P(Dusty) = 6/16 = 0.375
P(Yes)= 9/16 = 0.563
2. Calculating Posterior probability
P (Dusty | Yes) = 4/9 = 0.444
Putting Prior and Posterior in our equation:
P (Yes | Dusty) = 0.444 * 0.563 / 0.375 = 0.666
Probability of Flight not arriving in time:
P(No | Dusty) = P( Dusty | No) * P(No) / P(Dusty)
1. Calculating Prior probability
P(Dusty) = 6/16 = 0.375
P(No) = 7/16 = 0.438
2. Calculating Posterior probability
P(Dusty | No) = 2/7 = 0.285
Putting Prior and Posterior in our equation
P(No | Dusty) = 0.285*0.438 / 0.375 = 0.332
Given its Dusty weather flight will land in time. Here probability of flight arriving in time (0.666) is greater than flight not arriving in time (0.332), So the class assigned will be ‘In Time’.
Zero Probability Phenomena
Suppose we are predicting if a newly arrived email is spam or not. The algorithm predicts based on the keyword in the dataset. While analyzing the new keyword “money” for which there is no tuple in the dataset, in this scenario, the posterior probability will be zero and the model will assign 0 (Zero) probability because the occurrence of a particular keyword class is zero. This is referred to as “Zero Probability Phenomena”.
We can get over this issue by using smoothing techniques. One of the techniques is Laplace transformation, which adds 1 more tuple for each keyword class pair. In the above example, let’s say we have 1000 keywords in the training dataset. Where we have 0 tuples for keyword “money”, 990 tuples for keyword “password” and 10 tuples for keyword “account” for classifying an email as spam. Without Laplace transformation the probability will be: 0 (0/1000), 0.990 (990/1000) and 0.010 (10/1000).
Now if we apply Laplace transformation and add 1 more tuple for each keyword then the new probability will be 0.001 (1/1003), 0.988 (991/1003), and 0.01 (11/1003).
Pros and Cons
Pros
- Simple, Fast in processing, and effective in predicting the class of test dataset. So you can use it to make real-time predictions for example to check if an email is a spam or not. Email services use this excellent algorithm to filter out spam emails.
- Effective in solving a multiclass problem which makes it perfect for identifying Sentiment. Whether it belongs to the positive class or the negative class.
- Does well with few samples for training when compared to other models like Logistic Regression.
- Easy to obtain the estimated probability for a prediction. This can be obtained by calculating the mean, for example, print(result.mean()).
- It performs well in case of text analytics problems.
- It can be used for multiple class prediction problems where we have more than 2 classes.
Cons
- Relies on and often an incorrect assumption of independent features. In real life, you will hardly find independent features. For example, Loan eligibility analysis would depend on the applicant’s income, age, previous loan, location, and transaction history which might be interdependent.
- Not ideal for data sets with a large number of numerical attributes. If the number of attributes is larger then there will be high computation cost and it will suffer from the Curse of dimensionality.
- If a category is not captured in the training set and appears in the test data set then the model is assign 0 (zero) probability which leads to incorrect calculation. This phenomenon is referred to as ‘Zero frequency’ and to overcome ‘Zero frequency’ phenomena you will have to use smoothing techniques.
Python Code
# Gaussian Naive Bayes Classification import numpy as np import pandas as pd from sklearn.model_selection import cross_val_score from sklearn.metrics import accuracy_score, confusion_matrix from sklearn.naive_bayes import GaussianNB from sklearn.model_selection import train_test_split,GridSearchCV import matplotlib.pyplot as plt import seaborn as Sns sns.<a onclick="parent.postMessage({'referent':'.seaborn.set_style'}, '*')">set_style("whitegrid") import Warnings warnings.filterwarnings("ignore") import scipy.stats as stats %matplotlib inline data = pd.<a onclick="parent.postMessage({'referent':'.pandas.read_csv'}, '*')">read_csv('/kaggle/input/pima-indians-diabetes-database/diabetes.csv') X = data.drop(columns=['Outcome'],axis=1) Y = data['Outcome']
from sklearn.impute import SimpleImputer
rep_0 = SimpleImputer(missing_values=0, strategy="mean")
cols = X_train.columns X_train = pd.<a onclick="parent.postMessage({'referent':'.pandas.DataFrame'}, '*')">DataFrame(rep_0.fit_transform(X_train)) X_test = pd.<a onclick="parent.postMessage({'referent':'.pandas.DataFrame'}, '*')">DataFrame(rep_0.fit_transform(X_test)) X_train.columns = cols X_test.columns = cols X_train.head()
#Predicting train and test accuracy
predict_train = model.fit(X_train, y_train).predict(X_train)
# Accuray Score on train dataset a
accuracy_train = accuracy_score(y_train,predict_train) print('accuracy_score on train dataset : ', accuracy_train) # predict the target on the test dataset predict_test = model.predict(X_test) # Accuracy Score on test dataset accuracy_test = accuracy_score(y_test,predict_test) print('accuracy_score on test dataset : ', accuracy_test)
#accuracy_score on train dataset : 0.7597765363128491 #accuracy_score on test dataset : 0.7575757575757576
Hyperparameter Tuning to improve Accuracy
np.<a onclick="parent.postMessage({'referent':'.numpy.logspace'}, '*')">logspace(0,-9, num=10)
from sklearn.model_selection import RepeatedStratifiedKFold
cv_method = RepeatedStratifiedKFold(n_splits=5, n_repeats=3, random_state=999)
from sklearn.preprocessing import PowerTransformer params_NB = {'var_smoothing': np.<a onclick="parent.postMessage({'referent':'.numpy.logspace'}, '*')">logspace(0,-9, num=100)} gs_NB = GridSearchCV(estimator=model, param_grid=params_NB, cv=cv_method,verbose=1,scoring='accuracy') Data_transformed = PowerTransformer().fit_transform(X_test) gs_NB.fit(Data_transformed, y_test);
results_NB = pd.DataFrame(gs_NB.cv_results_['params'])
results_NB['test_score'] = gs_NB.cv_results_['mean_test_score']
# predict the target on the test dataset predict_test = gs_NB.predict(Data_transformed) # Accuracy Score on test dataset accuracy_test = accuracy_score(y_test,predict_test) print('accuracy_score on test dataset : ', accuracy_test)
#accuracy_score on test dataset : 0.7922077922077922
The media shown in this article are not owned by Analytics Vidhya and is used at the Author’s discretion.






Hey congrats Akshay, nice article 🙂