Introduction
Note from the author: In this article, we will learn how to create your own Question and Answering(QA) API using python, flask, and haystack framework with docker. The haystack framework will provide the complete QA features which are highly scalable and customizable. In this article Medium Rules, the text will be used as the target document and fine-tuning the model as well.
Basic Knowledge Required: Elasticsearch & Docker
This article contains the working code which can be directly build using docker.
Content of the article
- DocumentStores set up — Installation of Elasticsearch
- API Code Explanation
- Build the Flask API in docker
- Load data from the API
- Demonstration of the API
- Fine-tuning a model
- Code tuning (Trained/Pre-Trained)
- Summarize Result
1. DocumentStores set up
Haystack raises queries to the document which is available at DocumentStore. There are various DocumentStore included in haystack which are ElasticsearchDocumentStore, SQLDocumentStore, and InMemoryDocumentStore. In this article, I am going to use Elasticsearch which is recommended. It comes up with preloaded features like full-text queries, BM25 retrieval, and vector storage for text embeddings.
Run the below command for the installation of Elasticsearch

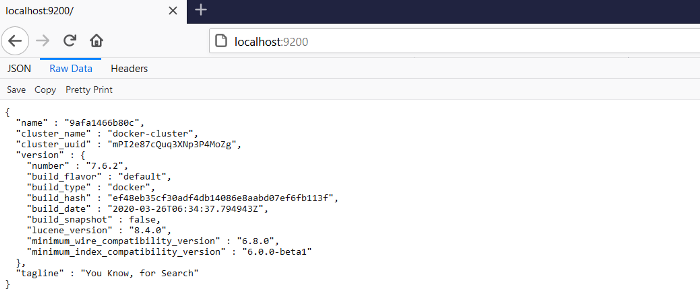
verify the installation by browsing the below URL. If install successfully it will display as in below:
2. API Code Explanation
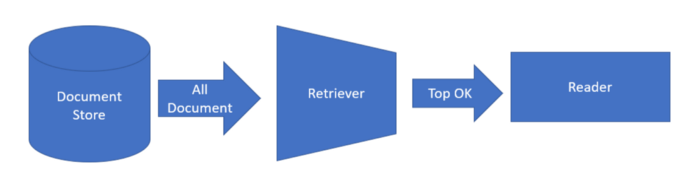
Haystack framework has main 3 basic components DocumentStore, Retriever, and Reader which we have to select based on our requirements.
DocumentStore: As recommended ElasticsearchDocumentStore will be used in this article. It comes preloaded with features like full-text queries, BM25 retrieval, and vector storage for text embeddings. Documents should be chunked into smaller units (e.g. paragraphs) before indexing to make the results returned by the Retriever more granular and accurate.
Retrievers: The answer needs to be display based on similarities on the embedded. So DensePassageRetriever is the powerful alternative to score the similarity of texts.
Readers: Farm Reader going to be used in this article if you wish Transformer readers can be used. For better accuracy “distilbert-base-uncased-distilled-squad” model going to be used by the readers.
The app structure as shown below:
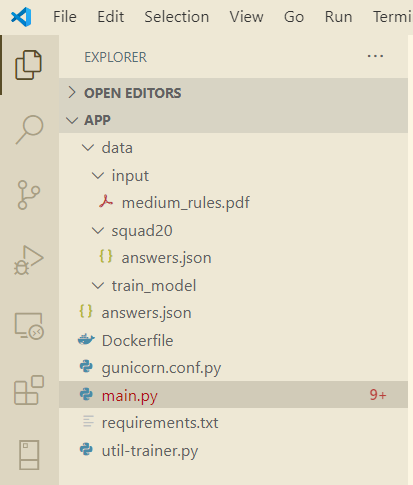
app structure
Code Explanation for main.py
In this article, we are going to use the ElasticSearch document. The application configuration is declared as in below:
Let’s implement endpoints for uploading the PDF document. The pdf document will be uploaded in the ElasticSearch with the provided index name.
Let’s implement endpoints for querying and will respond back with relevant (n)answers from the ElasticSearch document. The index needs to provide during the search query.
requirement.txt
Flask
gunicorn
futures
farm-haystack
Docker File
The Question and Answering API will be available @port 8777.
3. Build the Flask API in docker
Let’s run the below command to build the docker image:
docker build -t qna:v1 .
Build and run the flask API in docker container using the below command:
docker run — name qna_app -d -p 8777:8777 xxxxxxxxx
Note: xxxxxxxxx is the image id
Confirm the docker container using the below command:
docker ps
Its will show all the process as in below:

Now the QNA API is successfully running @ http://localhost:8777
4. Load data from the API
Let’s prepare a pdf document from Medium Rules which suppose to be upload in an elastic search document. Once you prepare the pdf document lets to upload using the API as in the below snapshot:
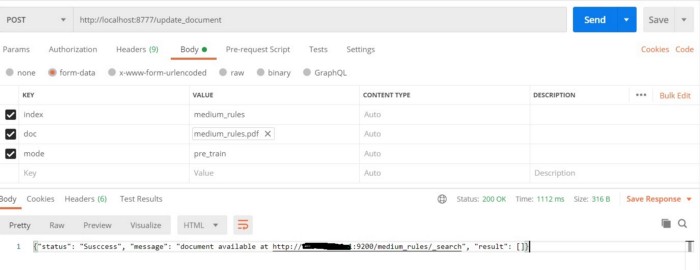
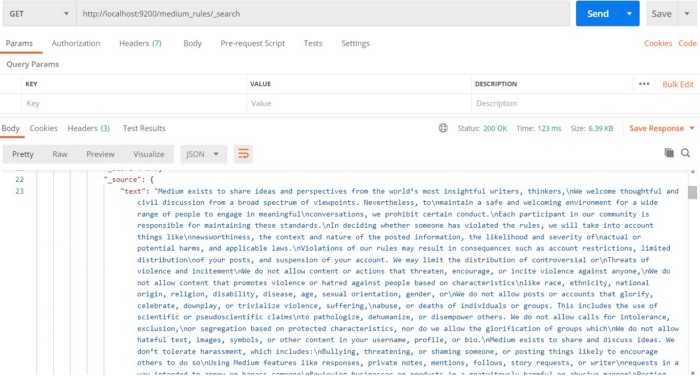
Verify the upload document as in the below snapshot:
5. Demonstration of the API
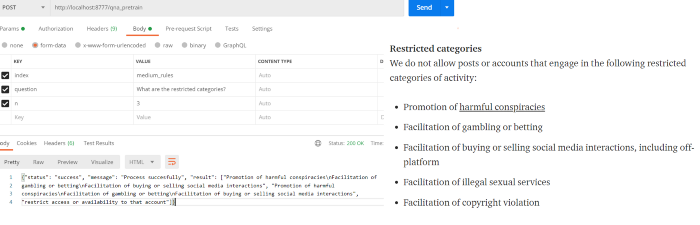
Let’s ask a question using the qna_pretrain endpoints. Currently, we have used only the pre-train model “distilbert-base-uncased-distilled-squad” which is provided good accuracy. In the next article, I will demonstrate how to annotate and improve the model. For querying a question use the API as in the below snapshot:
6. Fine-tuning a model
Let’s try to improve the model and train ourselves as per our requirements. For any domain-specific training we have to train ourselves, the Haystack Annotation tool will be used for labeling our data. In this article, I will use the hosted version of the annotation tool from the haystack.
For the local version follow here.https://github.com/deepset-ai/haystack/tree/master/annotation_tool
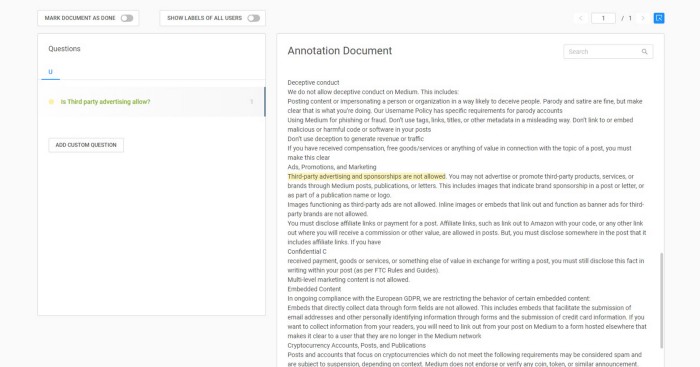
Now create an account with your personal email id and upload the txt document. Annotate your question and answers as in the below snapshot:
Now export all your labels in SQUAD format as “answers.json” and copy the file to the docker container with the below command:

Code explanation util-trainer.py
After the collection of the training labels, this python utility will help us to train and fine-tuning the model base on our requirements. Let’s proceed with the training with 10 epochs.
Use the below docker command to execute from the docker container:

To start the training run the command “python util-trainer.py “

At the end of the training, the model will be saved in the train_model directory. Now training is successfully completed.
7. Code Tuning (Trained & Untrained) Model
Let’s modify the code to subscribed the trained and pre-trained model in the same endpoint. We are going to add the additional parameter “mode” to be classified the model.
Published the code to the docker contained with the below command:
docker copy main.py qna_app:/usr/src/app/main.py
Now restart the container to reflect the changes in the API
docker restart qna_app
Now the API is ready to subscribe with the trained & pre-trained model.
8. Summarize Result
Now, let’s compare the two models (trained and pre-trained) and analyze the most probability answer. Use the below API as in the snapshot:
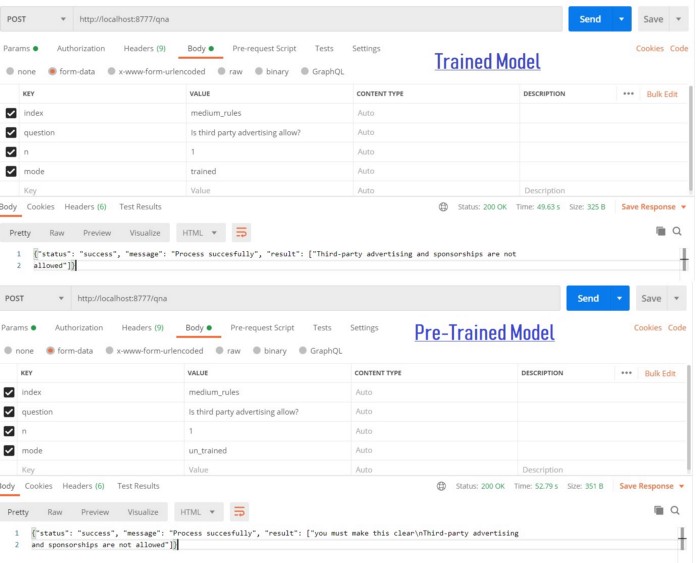
the trained model gives the perfect results as we provided the label in training data.
I hope we have learned to develop our own Question and Answering API by fine-tuning the model.
The same article is published on my medium channel
The complete source code is available here
The media shown in this article are not owned by Analytics Vidhya and is used at the Author’s discretion.




Very good and to the point article with coding examples. Thanks.