This article was published as a part of the Data Science Blogathon.

What Is Sentiment Analysis?
Conclusions are integral to practically all human exercises and are key influencers of our practices. Our convictions and impression of the real world, and the decisions we make, are, to an impressive degree, molded upon how others see and assess the world. Therefore, when we have to settle on a choice, we regularly search out the assessments of others. Opinions and their related concepts such as sentiments, evaluations, attitudes, and emotions are the subjects of the study of sentiment analysis.
The commencement and quick development of the field match with those of the web-based media on the Web, e.g., surveys, gathering conversations, web journals, microblogs, Twitter, and interpersonal organizations, because, without precedent for human history, we have a colossal volume of obstinate information recorded in advanced structures. Since mid-2000, supposition investigation has become one of the most dynamic examination territories in common language preparation.
It is likewise broadly considered in information mining, Web mining, and text mining. Truth be told, it has spread from software engineering to the executive’s sciences and sociologies because of its significance to business and society in general. As of late, modern exercises encompassing feeling examination have likewise flourished. Various new companies have risen. Numerous enormous enterprises have constructed their own in-house capacities.
Supposition examination frameworks have discovered their applications in pretty much every business and social space. Sentiment analysis, also called opinion mining, is the field of study that analyses people’s opinions, sentiments, evaluations, appraisals, attitudes, and emotions towards entities such as products, services, organizations, individuals, issues, events, topics, and their attributes. It represents a large problem space.
There are also many names and slightly different tasks, e.g., sentiment analysis, opinion mining, opinion extraction, sentiment mining, subjectivity analysis, effect analysis, emotion analysis, review mining, etc.
Sentiment analysis in python
There are many packages available in python which use different methods to do sentiment analysis. In the next article, we will go through some of the most popular methods and packages:
1. Textblob
2. VADER
→ Textblob:
Textblob sentiment analyzer returns two properties for a given input sentence:
- Polarity is a float that lies between [-1,1], -1 indicates negative sentiment and +1 indicates positive sentiments.
- Subjectivity is also a float that lies in the range of [0,1]. Subjective sentences generally refer to opinion, emotion, or judgment.
Let us see how to use Textblob:
Python Code:
from textblob import TextBlob
test = TextBlob("The movie was awesome!")
print(test.sentiment)Textblob will disregard the words that it does not have any acquaintance with, it will consider words and expressions that it can dole out extremity to and midpoints to get the last score.
→ VADER:
It uses a list of lexical features (e.g. word) which are labeled as positive or negative according to their semantic orientation to calculate the text sentiment. Vader sentiment returns the probability of a given input sentence to be positive, negative, and neutral.
For example:
“The movie was awesome!”
Positive: 99%
Negative: 1%
Neutral: 0%
These three probabilities will add up to 100%. Let us see how to use VADER:
from vaderSentiment.vaderSentiment import SentimentIntensityAnalyzer
analyzer = SentimentIntensityAnalyzer()
sentence = "The movie was awesome!"
vs = analyzer.polarity_scores(sentence)
print"{:-<65} {}".format(sentence, str(vs))

VADER Sentiment Analysis
Vader is optimized for social media data and can yield good results when used with data from Twitter, Facebook, etc. As the above result shows the polarity of the word and their probabilities of being pos, neg neu, and compound.
Now, I will clarify the above with the assistance of the inn dataset i.e. Hotel-Review dataset, where there are opinions of clients who stayed in the Hotel.
To outline the process very simply:
1) Pre-processing of the input into its component sentences or words.
2) Identify and tag each token with a part-of-speech component (i.e., noun, verb, determiners, sentence subject, etc).
3) Assign a sentiment score from -1 to 1, Where -1 is for negative sentiment, 0 as neutral and +1 is a positive sentiment
4) Return score and optional scores such as compound score, subjectivity, etc. by using the two powerful python tools — Textblob and VADER.
Textblob :
from nltk.sentiment.vader import SentimentIntensityAnalyzer
from nltk.sentiment.util import *
from textblob import TextBlob
from nltk import tokenize
df = pd.read_csv('hotel-reviews.csv')
df.head()
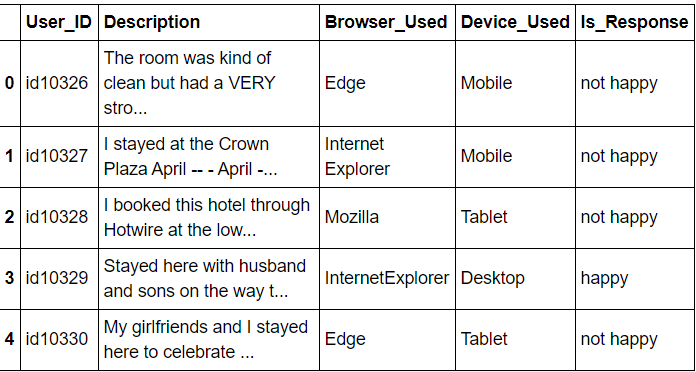
The above is the dataset preview of the hotel’s dataset.
df.drop_duplicates(subset =”Description”, keep = “first”, inplace = True)
df['Description'] = df['Description'].astype('str')
def get_polarity(text):
return TextBlob(text).sentiment.polarity
df['Polarity'] = df['Description'].apply(get_polarity)
In the above, using the TextBlob(text).sentiment.polarity, to generate sentiment polarity.
df['Sentiment_Type']='' df.loc[df.Polarity>0,'Sentiment_Type']='POSITIVE' df.loc[df.Polarity==0,'Sentiment_Type']='NEUTRAL' df.loc[df.Polarity<0,'Sentiment_Type']='NEGATIVE'
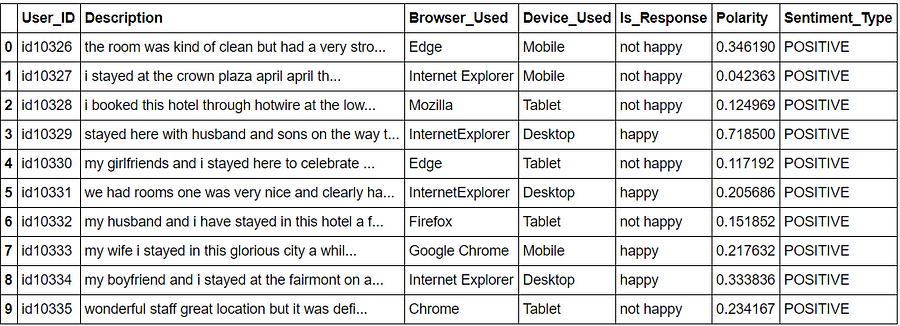
After the TextBlob the polarity and sentiment type for each comment/description received.
df.Sentiment_Type.value_counts().plot(kind='bar',title="Sentiment Analysis")
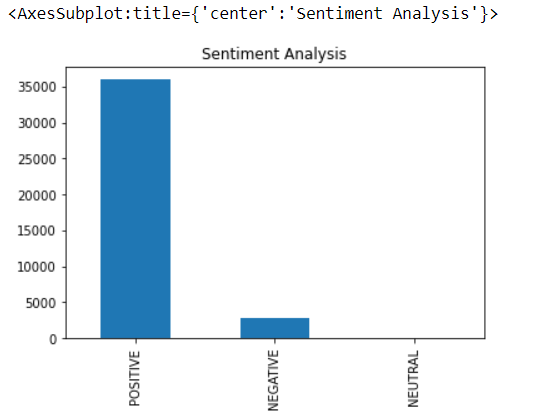
Plotting the bar graph for the same, the positive sentiments are more than negative which can build understanding as people are happy with service.
VADER :
VADER (Valence Aware Dictionary and sEntiment Reasoner) is a rule/lexicon-based, open-source sentiment analyzer pre-built library, protected under the MIT license.
import nltk
nltk.download('vader_lexicon')
from nltk.sentiment.vader import SentimentIntensityAnalyzer
sid = SentimentIntensityAnalyzer()
With VADER, using the sid.polarity_scores(Description)), to generate sentiment polarity.
df['scores'] = df['Description'].apply(lambda Description: sid.polarity_scores(Description)) df.head()

After the VADER the scores that have pos,neg,neu and compound.
df['compound'] = df['scores'].apply(lambda score_dict: score_dict['compound']) df['sentiment_type']='' df.loc[df.compound>0,'sentiment_type']='POSITIVE' df.loc[df.compound==0,'sentiment_type']='NEUTRAL' df.loc[df.compound<0,'sentiment_type']='NEGATIVE'
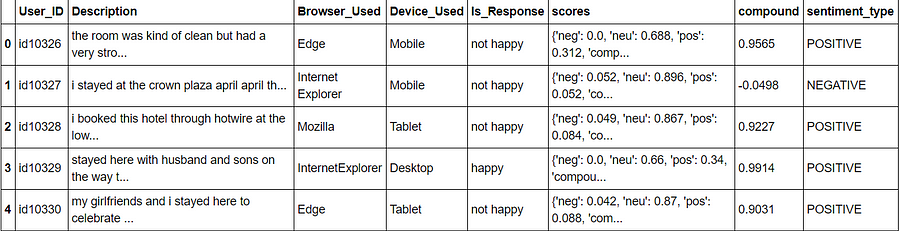
After the VADER the compound and sentiment type for each comment/description received.
df.sentiment_type.value_counts().plot(kind='bar',title="sentiment analysis")
Both Textblob and Vader offer a host of features — it’s best to try to run some sample data on your subject matter to see which performs best for your requirements. Plotting the bar graph for the same, the positive sentiments are more than negative which can build understanding as people are happy with service.
Hope this helps 🙂
Follow me if you like my posts. For more help, check my Github for Textblob and VADER.
Connect via LinkedIn https://www.linkedin.com/in/afaf-athar-183621105/
Happy learning 😃







For vader, I believe the authors recommend using -0.05 to 0.05 as the threshold for a comment to be neutral, and not simply 0.