Introduction
One of the applications of Natural Language Processing in machine learning is auto-correction and spelling checks. We have all encountered that if we type an incorrect or typo in the Google search engine, the engine automatically corrects it and suggests the right word in its place. How does the engine do that? How does it know what word we want to write or ask? These are all done using string similarity metrics algorithms. Whether comparing product names in an e-commerce platform or identifying duplicate entries in a database, string similarity algorithms are crucial in data science and overall computer science.

That is what we will be covering in this article. There are methods available to check this and the implementation of each process in Python.
Table of contents
String Similarity
But what exactly is string similarity? In essence, it’s a measure of how alike two strings are, quantifying their resemblance despite variations in spelling, grammar, or structure. The way to check the similarity between any data point or group is by calculating the distance between those data points. In textual data, we also check the similarity between the strings by calculating the distance between text and text.
In general, there are three main types of matching algorithms to measure string matching, which we will discuss in the next section:
- Edit-based algorithms
- Token-based algorithms
- Sequence-based algorithms
Edit-based algorithms
Edit-based algorithms, also known as edit distance algorithms, are a class of string similarity algorithms that quantify the similarity between two strings by measuring the minimum number of edit operations required to transform one string into another. The edit operations typically include insertions, deletions, and substitutions of characters.
These algorithms provide string metrics, numerical measures that express the degree of similarity or difference between strings. Common string metrics include:
Hamming Distance
Hamming Distance, named after the American mathematician, is the most straightforward algorithm for calculating string matching. It checks the similarity by comparing the changes in the number of positions between the two strings. The method compares every letter of one string with the corresponding letter of the other string.
Let’s Take These Two Words:
TIME and MINE. Every letter of the two strings will be compared in the following way:
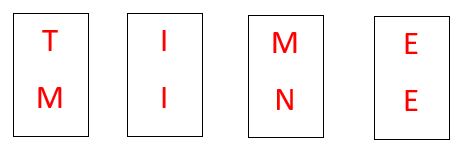
- The first two letters, T and M, are different, so the number of positions in which the two strings are different is 1 up until now.
- The next two letters, ‘I,’ are the same. Hence, the number of positions at which two strings differ is 0.
- Now, the following two letters, M and N, are again different, so the number of positions of two strings being different is 1, and
- The last two letters, E, are the same, so the number of different positions of two strings is 0.
This way, the Hamming distance is 2 = 1 + 0 + 1 + 0. It is the total number of positions different between two strings at each character’s place. In short, the number of unequal characters equals the Hamming distance.
The Hamming distance can range anywhere between 0 and any integer value, even equal to the length of the string. For this, we can also normalize the value by taking the ratio of the Hamming distance to the size of the string in the following manner:
Normalized Hamming Distance = Hamming Distance/ length of the string
Normalized Hamming distance gives the percentage to which the two strings are dissimilar. The normalized Hamming distance for the above TIME and my example is 2/4 = 0.50; hence, 50% of these two characters are not similar. A lower value of Normalized Hamming distance means the two strings are more comparable.
We can use the Scipy library in Python, which has the direct Hamming distance function. The codes are available in my GitHub Repository.
Python Code:
from scipy.spatial import distance
import numpy as np
# Example 1:
# Strings
string1 = 'TIME'
string2 = 'MINE'
# Normalized Hamming Distance
Normalized_HD = distance.hamming(list(string1),list(string2))
print("The Normalized Hamming Distance between {} and {} is {}".format(string1, string2,Normalized_HD))
# Original Hamming Distance
print("The Hamming Distance between {} and {} is {}".format (string1,string2, Normalized_HD*len(string1)))
#Let’s take one more example: MAN and WOMAN and see if can calculate the Hamming distance for strings of unequal length:
# Example 2:
# Strings:
word1 = 'MAN'
word2 = 'WOMAN'
#Normalized Hamming Distance
Normalized_HD = distance.hamming(list(word1),list(word2))
print("The Normalized Hamming Distance between {} and {} is {}.".format(word1,word2,Normalized_HD))As seen above, this metric can only be used when the strings are the same length. Hence, we need a more robust algorithm that can be used for words or strings with different lengths, and therefore, we will move to the following method: Levenshtein Distance.
Levenshtein Distance
Levenshtein distance is the most frequently used algorithm. It was founded by the Russian scientist Vladimir Levenshtein to calculate the similarities between two strings. This is also known as the Edit distance-based algorithm, which computes the number of edits required to transform one string to another. The edits count the following as an operation:
- Insertion of a character
- Deletion of a character
- Substitution of a character
The more the number of operations, the less the similarity between the two strings.
Levenshtein distance works in the following manner; let’s take the two words CLOCK and CLONE:
Here, the number of edits required is two, as the first three letters of the two words, C, L, and O, are the same. Now, we need to substitute C for N and K instead of E to transform the phrase CLOCK to CLONE. Therefore, here the Levenshtein distance is 2.
Let’s check if we can find the distance using Levenshtein’s algorithm for our original example of MAN and WOMAN, where the lengths of the string are unequal:
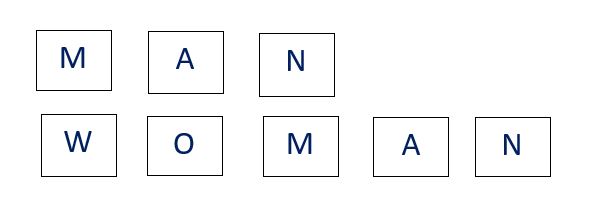
To convert the word MAN to WOMAN, we need to do two edits of inserting the first two letters W and O. Hence, the Levenshtein distance here is 2. The Levenshtein algorithm can also measure the similarity between strings of different lengths.
Up until now, we have calculated the edits directly by looking at the words. However, it would be difficult sometimes to get the minimum number of edits required to transform the words just by looking at them. Hence, there is another method to compute the Levenshtein distance by the matrix method.
Matrix Method for Levenshtein Distance
The matrix form to calculate Levenshtein distance follows:
Firstly, we’ll calculate for the CLOCK-CLONE example, where the length of the strings is equal:
Here, I have written the words CLOCK and CLONE in row and column, respectively. We can interchange this order of the words as well, which will not impact the result. We would need to write each of the letters of the respective words as a separate element of the matrix.
Step 1:
As an initial step, we first mark the letters starting from 1 to the length of the string. So here, both CLOCK and CLONE are marked from 1 to 5:
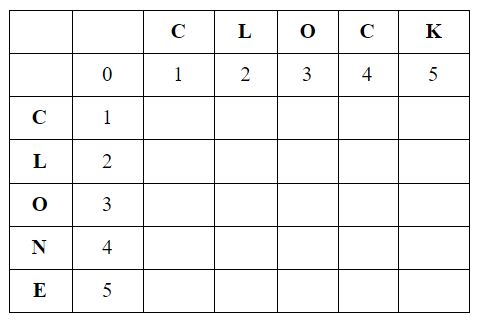
The number 0 represents a null, semantic string with no alphabets or letters. It reflects the number of edits required to convert the word to the null string.
Here, to convert CLOCK to a null string, the number of edits needed is five. Similarly, in this case, the number of edits required to convert CLONE to a null string will also be five.
To further break it down, on a granular level, if looking at the word CLOCK:
- The number of edits required to transform the first letter C to a null string (0) will be 1, hence the number under the letter C is marked as 1.
- The number of edits required to convert the second letter L to the null string will be 2, so the number under L is 2.
- Similarly, the number 3 under the letter O represents that the number of edits required to convert the third letter O to the null string will be 3 and so on.
In the same manner, the word CLONE can be broken from 1 to 5.
Step 2:
We will fill the other values of the matrix depending on how many edits are required to convert each letter of the string to another or by the surrounding values.
Method 1:
We have looked above at how to convert each letter of the word to another word. to quickly recap this, we’ll take each letter of the row and column in the following way:
i) Starting from the letter C of the row and column, we would not need to make any edits as both letters are the same. Therefore, the value corresponding to this will be 0.
ii) Moving in the same row having the letter C:
- CL of the first word CLOCK -> to convert to C of the second word CLONE: need one edit. That is to delete the letter L from CL to make it C. Hence, the Levenshtein distance between CL to C is 1.
- CLO of the first word CLOCK -> to convert to C of the second word CLONE would need two edits.
- In the same manner, CLOC of the first word CLOCK -> to convert to C of the second word CLONE would need three edits and so on.
In this way, by looking at each letter of the first-word corresponding to the letters of the next word, we can fill the first row like below:

Moving in the same row having the letter C:
- CL of the first word CLOCK -> to convert to C of the second word CLONE: need one edit. That is to delete the letter L from CL to make it C. Hence, the Levenshtein distance between CL to C is 1.
- CLO of the first word CLOCK -> to convert to C of the second word CLONE would need two edits.
- In the same manner, CLOC of the first word CLOCK -> to convert to C of the second word CLONE would need three edits and so on.
In this way, by looking at each letter of the first-word corresponding to the letters of the next word, we can fill the first row like below:

Similar fashion, moving on we’ll take the next rows CL of the word CLONE to transform to the word CLOCK:
- CL of the word CLONE -> to convert to C of the word CLOCK: need one edit. That is to delete the letter L from CL to make it C. Hence, the Levenshtein distance between CL to C is 1.
- CL of the word CLONE -> to convert to CL of the word CLOCK, would not need any edits. So, the Levenshtein distance between CL and CL is 1.
- CL of the word CLONE -> to convert to CLO of the word CLOCK, would need one edit.
- CL of the word CLONE -> to convert to CLOC of the word CLOCK, would need two edits and so on.
In this way, the second row gets filled in the following manner:

The remaining rows can be filled in the above way as well resulting in:

Method 2:
Now, there is another way to find the number of edits required by looking at the surrounding values:
- When the last letter of both the strings are the same: then we take the
minimum of (the diagonal value, first corresponding element +1, second corresponding element + 1)
- When the letters of the strings are not the same, then we take the minimum of the surrounding values + 1
We’ll look at the workings of each of these two below:
Let’s say, in the first case, when we take the first letter of both the words C, which is the same. Here,

- The diagonal element is 0.
- The first corresponding element is 1, and
- The second corresponding element is also 1.
So, the output becomes: min(0, 1+1, 1+1) = 0
Hence, the number of edits or the Levenshtein distance from C to C is 0.

Now, we will see how many edits are required to convert the first two letters CL of the first word CLOCK and to the first letter C of the word string CLONE:
- Here, the last letters of the words CL and C are not the same.
- The surrounding values here are: 0,1,2
- Here, will take the minimum of the surrounding values + 1:
Hence, the output becomes = min(0,1,2) + 1 = 1
Therefore, we need one edit from CL to make it C; hence, the Levenshtein distance between CL and C is 1.

Let’s do it a couple of more times, where the last letters of the words are not the same to drive the point home:
To Change the First Three Letters of “CLOCK” to “CLO” and the First Letter of “CLONE” to “C”:
- The surrounding values here are: 1,2,3
- Here, will take the minimum of the surrounding values + 1:
So, the output becomes = min(1,2,3) + 1 = 1 + 1 = 2
Therefore, the number of edits required to transform CLO to C is 2. Hence, the Levenshtein distance between CLO and C is 2.

Now, to convert the first four letters CLOC of the first word CLOCK and to the first letter C of the word string CLONE:
- The surrounding values here are: 2,3,4
- Again, will take the minimum of the surrounding values + 1:
Hence, the output becomes = min(2,3,4) + 1 = 2 + 1 = 3
The number of edits required to transform CLOC to C is 3. Therefore, the Levenshtein distance between CLOC and C is 3.
We’ll look at it one more time via the surrounding values method, where the last letters of the words are the same. Let’s say we have reached the matrix point for CLO at both the respective row and column:

Now, will be using:
Minimum of (the diagonal value, first corresponding element +1, second corresponding element + 1) to calculate the distance.
Here,
- The diagonal element is 0.
- The first corresponding element is 1, and
- The second corresponding element is 1.
Hence, the output becomes: min(0, 1+1, 1+1) = 0
Therefore, the Levenshtein distance from CLO to CLO is 0.
In this way, the entire matrix can be filled as below. The last element represents the Levenshtein distance to convert the word CLOCK to CLONE, which is 2.
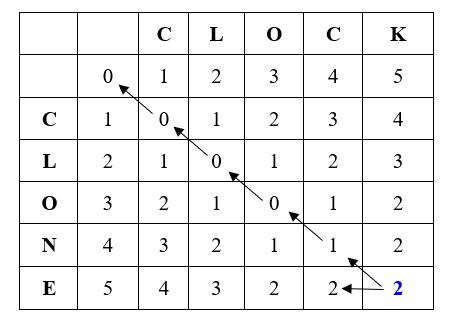
Matrix Computation Reveals all Necessary Edits to Convert Words:
- Whenever the current element is greater than 0, then we look at how we got this value. Here, the Levenshtein distance between CLOCK and CLONE is 2, which we got by taking the minimum of the surrounding values + 1 which is min(1,2,2) + 1 = 1 + 1 = 2.
- This value is dependent on the diagonal values, and when moving upwards on the diagonal values, then it represents Substitution. Here, we have to substitute K with E.
- Moving up the diagonal, the value is 1, which is greater than 0. We got 1 by taking the minimum of the surrounding values + 1 which is min(0,1,1) + 1 = 0 + 1 = 1. Here, we would need to substitute C with N.
- Again moving upwards on the diagonal, the elements are CLO on both the sides and the diagonal is 0, which means no edits are required. Similarly, for CL and C.
- On moving in the left direction from the last element 2, then that is Deletion. We would need to delete two letters from CLOCK to make it CLONE.
Hence, the total number of edits required to transform CLOCK to CLONE is 2.
The Levenshtein matrix for the second example of MAN-WOMAN, where the length of the string is not equal:
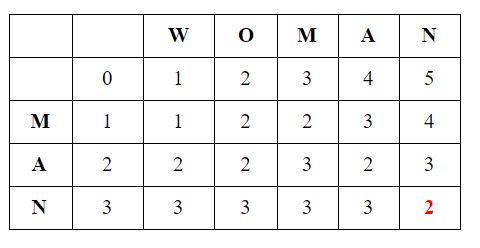
The Levenshtein distance to transform the word WOMAN to word MAN is 2.
There is no pre-written function in Python to compute Levenshtein distance, so we define a custom function to implement it.
Step 1:
Using the NumPy library, define the matrix, its shape, and the initial values in the matrix are all 0. We will fill the matrix based on the distance calculation in the future.
Length of the matrix = length of the strings + 1 because we add an extra row and column for the null string.
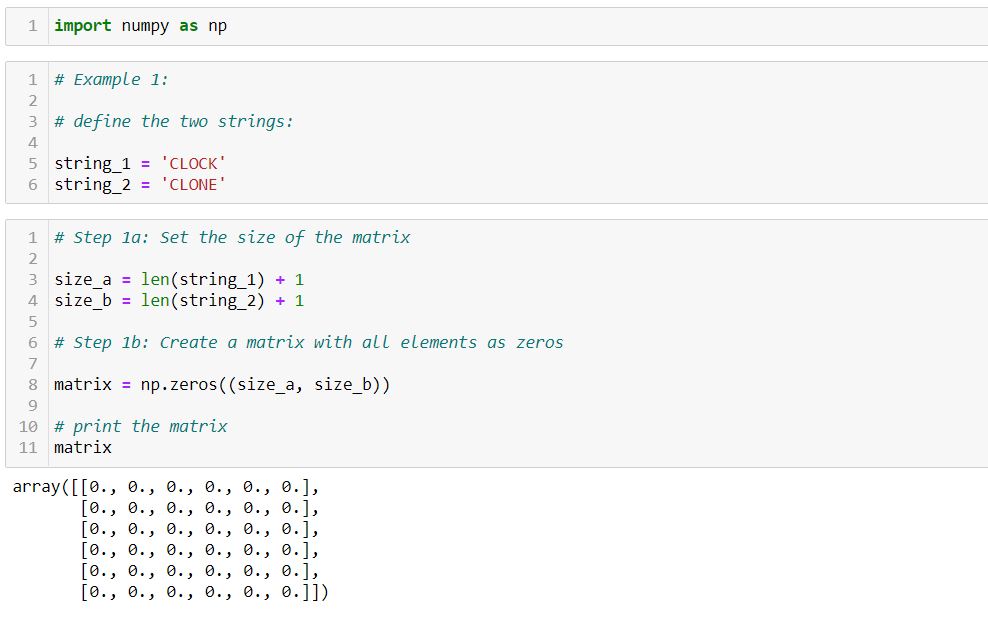
Step 2:
We fill the first column and the first row with the index of the characters from the first string and second string, respectively:

Step 3:
Fill the values of the matrix-based upon if the characters of the strings are the same or different:
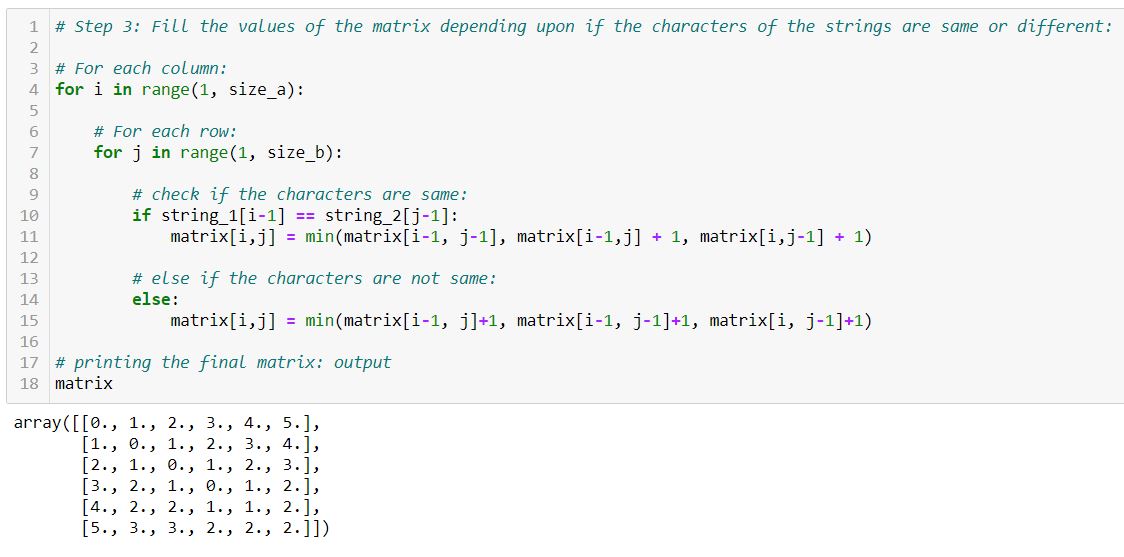
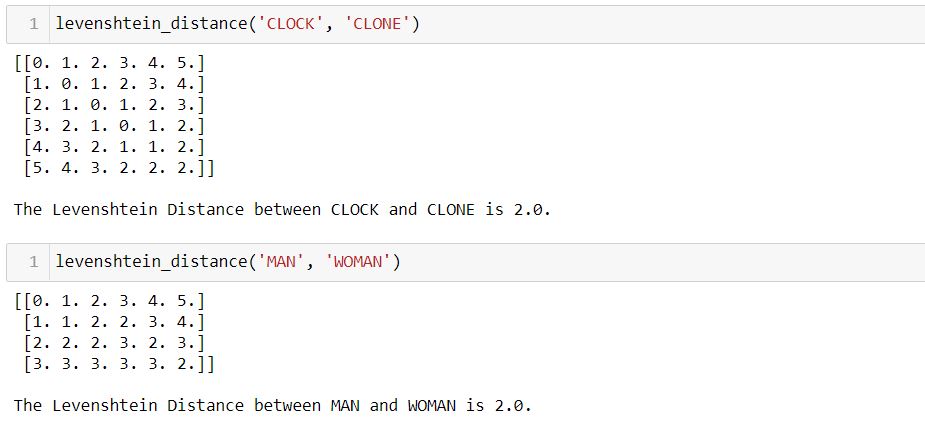
The Levenshtein distance for the above examples are as follows:
Damerau-Levenshtein Distance
The Damerau-Levenshtein Distance is a string similarity algorithm that calculates the minimum number of edit operations required to transform one string into another, allowing insertions, deletions, substitutions, and transpositions of adjacent characters. Here’s a brief explanation, along with an example:
Let’s consider two strings: “kitten” and “sitting”.
The Damerau-Levenshtein Distance between these two strings is calculated as follows:
- Insert ‘s’ at the beginning of “kitten” to match the first character of “sitting”.
- Substitute ‘k’ with ‘s’ to match the second character.
- The ‘e’ in “kitten” can be matched with ‘i’ in “sitting” by a transposition.
- The rest of the characters in “kitten” (‘t’, ‘t’, ‘e’, ‘n’) can be matched directly with characters in “sitting” (‘t’, ‘t’, ‘i’, ‘n’).
Therefore, the Damerau-Levenshtein Distance between “kitten” and “sitting” is 3, indicating that three edit operations (insertion, substitution, and transposition) are required to transform “kitten” into “sitting”.
Jaro similarity
Jaro similarity is a measure of similarity between two strings that considers the number of matching characters and the transpositions of matched characters. The output of the Jaro similarity algorithm is a value between 0 and 1, where 0 indicates no similarity, and 1 indicates an exact match.
The formula for Jaro similarity is:
J=13(mlength of string1+mlength of string2+m−tm)J=31(length of string1m+length of string2m+mm−t)Where:
- mm is the number of matching characters.
- tt is half the number of transpositions (the number of unmatched characters found in both strings but not in the same order).
For example, let’s compare the strings “MARTHA” and “MARHTA.” Here, m=6m=6 (all characters match except the fourth), and t=0t=0 (no transpositions).
J=13(66+66+6−06)=66=1J=31(66+66+66−0)=66=1So, the Jaro similarity between “MARTHA” and “MARHTA” is 1, indicating a perfect match
Jaro-Winkler similarity:
The Jaro-Winkler similarity or Jaro-Winkler Distance is a metric used to measure the similarity between two strings. It calculates a value between 0 and 1, where 0 indicates no similarity, and 1 indicates an exact match. The distance takes into account the number of matching characters and the order in which they appear, with a higher weight assigned to matching characters at the beginning of the strings.
Here’s a brief overview of the Jaro-Winkler Distance formula:
1. Calculate the Jaro Distance (J):
– Count the number of matching characters (m) between the two strings within a defined window (usually max(len(s1), len(s2))/2 – 1).
– Calculate the number of transpositions (t) by comparing the positions of matching characters.
- Jaro Distance (J) = (m / len(s1) + m / len(s2) + (m - t) / m) / 32. Apply the Jaro-Winkler factor (p):
– Define a scaling factor (p) based on the length of the common prefix between the two strings and a predefined constant (usually 0.1).
- Jaro-Winkler Distance = J + (prefix_length p (1 - J))Output: The output of the Jaro-Winkler Distance is a similarity score between 0 and 1, where a higher score indicates a greater similarity between the strings. For example, if the Jaro-Winkler Distance between two strings “hello” and “hallo” is 0.92, it suggests a high degree of similarity between the two strings.
Smith-Waterman Algorithm
The Smith-Waterman algorithm is a dynamic programming algorithm used for local sequence alignment, often applied to compare DNA or protein sequences. It identifies regions of similarity between two strings by finding the optimal local alignment, considering insertions, deletions, and substitutions.
Description of the algorithm:
1. Initialization: Create a matrix with dimensions (m+1) × (n+1), where m and n are the lengths of the two input strings. Initialize the first row and column with zeros.
2. Scoring Scheme: Define a scoring scheme for match, mismatch, insertion, and deletion operations. Typically, match scores positively, and mismatches, insertions, and deletions incur penalties.
3. Dynamic Programming: Traverse the matrix, filling in each cell by considering the optimal score that can be achieved by aligning substrings up to that point. The score in each cell is calculated based on the scores of neighboring cells and the scoring scheme.
4. Traceback: Trace back from the cell with the highest score to find the optimal alignment path. This path represents the aligned regions of the two strings with the highest similarity score.
5. Output: The output includes the optimal alignment score and the aligned substrings from the input strings, representing the regions of similarity.
Here’s a simple example with input strings “ACGT” and “AGT”:
“`
| | A | C | G | T |
— |—|—|—|—|—|
| 0 | 0 | 0 | 0 | 0 |
— |—|—|—|—|—|
A | 0 | 2 | 1 | 0 | 0 |
— |—|—|—|—|—|
G | 0 | 1 | 1 | 5 | 4 |
— |—|—|—|—|—|
T | 0 | 0 | 0 | 4 | 8 |
“`
In this example, the highest score is 8, found at the cell corresponding to the alignment of “AGT” and “AGT”, with a match at each position. The traceback path will reveal the aligned regions, and the score indicates the degree of similarity between the substrings.
Token based algorithms
Token-based algorithms for string similarity metrics involve breaking down strings into smaller units, called tokens, and then comparing these tokens to determine the similarity between the strings. Tokens can be individual characters, words, or n-grams (sequences of n characters or words). These algorithms are widely used in Natural Language Processing (NLP) tasks such as text matching, spell correction, and plagiarism detection. Here are some standard token-based algorithms for string similarity:
Jaccard Similarity
Jaccard Similarity is a measure of similarity between two sets. It is calculated by dividing the size of the intersection of the sets by the size of the union of the sets. In the context of string similarity, Jaccard Similarity calculates the similarity between two strings based on the overlap of their word sets.
# Jaccard Similarity in Pythondef jaccard_similarity(string1, string2): set1 = set(string1.split()) set2 = set(string2.split()) intersection = len(set1.intersection(set2)) union = len(set1.union(set2)) return intersection/union# Example usage:string1 = "hello world"string2 = "world hello"print("Jaccard Similarity:", jaccard_similarity(string1, string2))Output: Jaccard Similarity: 1.0
Cosine Similarity
Cosine Similarity is a similarity measure between two non-zero vectors in an inner product space. In the context of similarity score between two strings, it calculates the cosine of the angle between the vector representations of two strings, typically using word frequencies as components of the vectors. The output ranges from -1 (entirely dissimilar) to 1 (perfectly similar), with 0 indicating no similarity.
Output example:
Vector 1: [2, 3, 0, 1]
Vector 2: [1, 2, 1, 0]
Cosine Similarity = (2*1 + 3*2 + 0*1 + 1*0) / (sqrt(2^2 + 3^2 + 0^2 + 1^2) * sqrt(1^2 + 2^2 + 1^2 + 0^2))
= (2 + 6 + 0 + 0) / (sqrt(4 + 9 + 0 + 1) * sqrt(1 + 4 + 1 + 0))
= 8 / (sqrt(14) * sqrt(6))
≈ 0.78
Sorensen-Dice
Sørensen-Dice similarity, also known as Dice’s coefficient, is a token-based algorithm that measures the similarity between two strings. It calculates the similarity based on the size of the intersection of the token sets divided by the average size of the two token sets. In other words, it measures the similarity by considering the standard tokens between the strings relative to the total number of tokens in both strings.
Formula: Dice(A,B)=2×∣A∩B∣∣A∣+∣B∣Dice(A,B)=∣A∣+∣B∣2×∣A∩B∣Where:
- AA and BB are sets of tokens from the two strings.
- ∣A∩B∣∣A∩B∣ denotes the size of the intersection of the token sets.
- ∣A∣∣A∣ and ∣B∣∣B∣ represent the sizes of the token sets for strings AA and BB, respectively.
string1 = “apple”
string2 = “banana”
similarity_score = dice_similarity(string1, string2)
print(“Dice similarity between ‘{}’ and ‘{}’ is {:.2f}”.format(string1, string2, similarity_score))
Dice similarity between ‘apple’ and ‘banana’ is 0.20
Sequence-based algorithms
Sequence-based algorithms for string similarity focus on comparing strings by analyzing their sequences of characters or tokens. These algorithms aim to quantify the similarity between two strings based on their sequences’ similarity. Here are some standard sequence-based algorithms for string similarity:
Longest Common Subsequence (LCS)
The Longest Common Subsequence (LCS) algorithm finds the longest subsequence common to two strings. Unlike substrings, subsequences are not required to occupy consecutive positions within the original strings.
Let’s consider two strings: “ABCDGH” and “AEDFHR.” The longest common subsequence between these two strings is “ADH,” with a length of 3.
Here’s how the LCS algorithm works:
- Construct a matrix where rows represent the characters of the first string and columns represent the characters of the second string.
- Initialize the first row and the first column with zeros.
- Iterate through each character of both strings:
- If the characters match, add 1 to the value in the cell diagonal to the current cell.
- If they don’t match, take the maximum value from the cell above or to the left and assign it to the current cell.
- The value in the matrix’s bottom-right cell represents the LCS’s length.
- Trace back from this cell to reconstruct the LCS.
Using the example strings “ABCDGH” and “AEDFHR,” here’s the matrix after applying the LCS algorithm:
| | A | E | D | F | H | R |
—|—|—|—|—|—|—|—|
| 0 | 0 | 0 | 0 | 0 | 0 | 0 |
A | 0 | 1 | 1 | 1 | 1 | 1 | 1 |
B | 0 | 1 | 1 | 1 | 1 | 1 | 1 |
C | 0 | 1 | 1 | 1 | 1 | 1 | 1 |
D | 0 | 1 | 1 | 2 | 2 | 2 | 2 |
G | 0 | 1 | 1 | 2 | 2 | 2 | 2 |
H | 0 | 1 | 1 | 2 | 2 | 3 | 3 |
The LCS length is 3, and by tracing back from the bottom-right cell, we get the LCS “ADH.”
Ratcliff-Obershelp similarity
Ratcliff/Obershelp similarity is a similarity score between two strings algorithm that compares two strings by recursively finding the longest common subsequence (LCS) between them. It calculates a similarity score based on the length of the LCS and the total length of the strings. The algorithm returns a value between 0 and 1, where 1 indicates a perfect match, and 0 indicates no similarity.
Here’s a Python implementation of Ratcliff/Obershelp similarity:
def ratcliff_obershelp(s1, s2):
# Recursive function to find the length of the LCS
def lcs(s1, s2): if not s1 or not s2: return 0 if s1[-1] == s2[-1]:return 1 + lcs(s1[:-1], s2[:-1])
else:
return max(lcs(s1, s2[:-1]), lcs(s1[:-1], s2))# Calculate similarity score
lcs_length = lcs(s1, s2) similarity = (2.0 * lcs_length) / (len(s1) + len(s2)) return similarity# Example usage
s1 = "hello"s2 = “hallo”
similarity_score = ratcliff_obershelp(s1, s2)
print(“Ratcliff/Obershelp similarity:”, similarity_score)
Ratcliff/Obershelp similarity: 0.8
Summary
The Hamming distance tells the number of positions where the two strings differ. Normalized Hamming distance is the ratio of the Hamming distance to the length of the string. A lower value of Normalized Hamming distance suggests the two strings are more similar.
The Levenshtein distance can be computed to find the distance between the two strings and the number of edits. It can be found using the surrounding values in a matrix form and can also be used for strings with different lengths. To summarize:
- Firstly, mark the number of words from 1 to the length of the string. The number 0 is the null string reflecting the number of edits required to convert the word to the null string.
- When the last letter of both the strings is the same, then we take the
minimum of (the diagonal value, first corresponding element +1, second corresponding element + 1)
- When the letters of the strings are not the same, then we take the minimum of the surrounding values + 1
The last element of the Levenshtein matrix represents the Levenshtein distance between the strings. Moving upwards on the diagonal represents the Substitution of the elements, and moving in the left direction is the Deletion of the elements.
Conclusion
In conclusion, similarity score between two strings are indispensable tools in Natural Language Processing (NLP) and other fields where text comparison and analysis are vital. From correcting spelling errors in search engines to detecting database duplicates, these algorithms enable machines to understand and process textual data effectively. Throughout this article, we delved into the intricate world of similarity score between two strings, exploring edit-based, token-based, and sequence-based algorithms. We discussed the use cases of these algorithms, ranging from spell correction to plagiarism detection. We examined famous metrics such as Hamming distance, Levenshtein distance, Jaccard similarity, and Ratcliff-Obershelp similarity. By harnessing these fuzzy string similarity metrics measures, developers and data scientists can unlock new insights from text data and enhance various NLP applications.
With Python as our trusty companion, we embarked on a journey through string similarity, equipped with the knowledge to tackle diverse text comparison tasks with finesse and accuracy.
Frequently Asked Questions
Q1. What is string similarity?
A. String similarity measures how alike two strings (sequences of characters) are. It’s useful in tasks like spell checking, text matching, and natural language processing, where you need to determine how close two text strings are in terms of content.
Q2. What is an example of string similarity?
A. An example of string similarity is comparing the strings “kitten” and “sitting”. Using the Levenshtein distance method, which counts the minimum number of single-character edits (insertions, deletions, or substitutions) needed to change one word into the other, we find that “kitten” can be transformed into “sitting” with three edits (kitten → sitten → sittin → sitting).
Q3.What is string similarity in AI?
A. In AI, string similarity is used in various applications like text mining, machine translation, and voice recognition. AI models use string similarity algorithms to handle tasks such as matching user queries to database entries, correcting typos, and comparing text inputs to predefined templates.
Q4. What is the best string similarity algorithm?
A. The “best” string similarity algorithm depends on the specific use case. Some commonly used algorithms include:
Levenshtein Distance: Good for general purposes, calculates edit distance.
Jaccard Index: Measures similarity between sets of characters or words, useful in text mining.
Cosine Similarity: Used in vector space models, helpful for comparing longer texts.
Smith-Waterman: Used in bioinformatics, finds local sequence alignment.
Hi there! I am Neha Seth. I work as a Data Scientist in Larsen & Toubro Infotech (LTI). I hold a Postgraduate Program in Data Science & Engineering from the Great Lakes Institute of Management and a Bachelors in Statistics. I have been featured as Top 10 Most Popular Guest Authors in 2020 on Analytics Vidhya (AV).
My area of interest lies in NLP and Deep Learning. I have also passed the CFA Program. You can reach out to me on LinkedIn and can read my other blogs for AV.







Nice article. Very well explained. Keep it up.
This is a fantastic article. Exactly what I was looking for!