This article was published as a part of the Data Science Blogathon.
Overview
K-means clustering is a very popular and powerful unsupervised machine learning technique where we cluster data points based on similarity or closeness between the data points how exactly We cluster them? which methods do we use in K Means to cluster? for all these questions we are going to get answers in this article, before we begin take a close look at the below clustering example, what do you think? it’s easily interpretable, right? We clustered data points into 3 clusters based on their similarity or closeness.
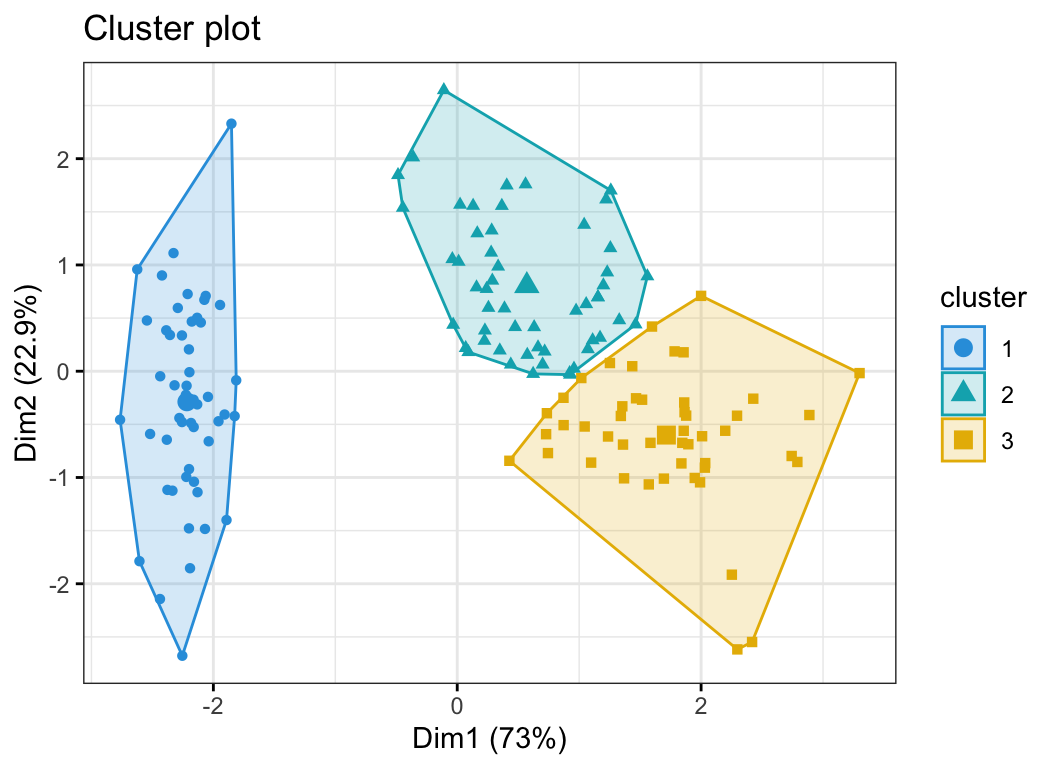
Table Of Contents
1.introduction to K Means
2.K Means ++ Algorithm
3.How To Choose K Value in K Means?
4.Practical Considerations in K Means
5.Cluster Tendency
1. Introduction
Let’s simply understand K-means clustering with daily life examples. we know these days everybody loves to watch web series or movies on amazon prime, Netflix. have you ever observed one thing whenever you open Netflix? that is grouping movies together based on their genre i.e crime, suspense..etc, hope you observed or already know this. so Netflix genre grouping is one easy example to understand clustering. let’s understand more about k means clustering algorithm.
Definition: It groups the data points based on their similarity or closeness to each other, in simple terms, the algorithm needs to find the data points whose values are similar to each other and therefore these points would then belong to the same cluster.
so how does the algorithm find out values between two points to cluster them, the algorithm finds values is by using the method of ‘Distance Measure’. here distance measure is ‘Euclidean Distance’
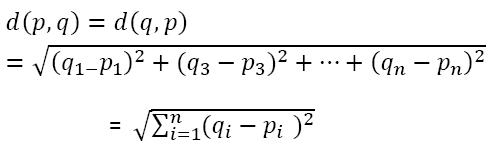
The observations which are closer or similar to each other would have low Euclidean distance and then clustered together.
one more formula that you need to know to understand K means is ‘Centroid’. The k-means algorithm uses the concept of centroid to create ‘k clusters.’
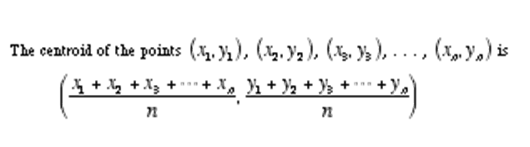
So now you are ready to understand steps in the k-Means Clustering algorithm.
Steps in K-Means:
step1:choose k value for ex: k=2
step2:initialize centroids randomly
step3:calculate Euclidean distance from centroids to each data point and form clusters that are close to centroids
step4: find the centroid of each cluster and update centroids
step:5 repeat step3
Each time clusters are made centroids are updated, the updated centroid is the center of all points which fall in the cluster. This process continues till the centroid no longer changes i.e solution converges.
You can play around with the K-means algorithm using the below link, try it.
https://stanford.edu/class/engr108/visualizations/kmeans/kmeans.html
So what next? how do you choose initial centroids randomly?
Here comes the concept of the k-Means++ algorithm.
2. K-Means ++ Algorithm:
I’m not going to stress you more on this so don’t worry. it is very easy to understand. So what is k-means++??? Let’s say we want to choose two centroids initially(k=2), you can choose one centroid randomly or you can choose one of the data points randomly. simple right? Our next task is to choose another centroid, how do you choose? any idea?
We choose the next centroid from the data points which is at a long distance from the existing centroid or the one which is at a long distance from an existing cluster that has a high chance of picking up.
3.How To Choose K Value In K-Means:
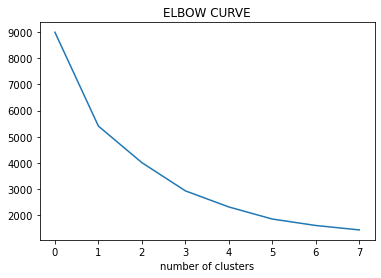
1.Elbow method
steps:
step1: compute clustering algorithm for different values of k.
for example k=[1,2,3,4,5,6,7,8,9,10]
step2: for each k calculate the within-cluster sum of squares(WCSS).
step3: plot curve of WCSS according to the number of clusters.
step4: The location of bend in the plot is generally considered an indicator of the approximate number of clusters.
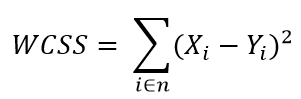
4.Practical Considerations In K-Means:
- A choosing number of Clusters in Advance(K).
- Standardization of Data(scaling).
- Categorical Data(can be solved with K-Mode).
- Impact of initial Centroids and Outliers.
5. Cluster Tendency:
Before we apply a clustering algorithm to the given data, it is important to check whether the given data has some meaningful clusters or not. The process to evaluate the data to check if the data is feasible for clustering or not is known as ‘Clustering Tendency’.so we should not blindly apply the clustering method and we should check clustering tendency. how?
We use ‘Hopkins Statistic’ to know whether to perform clustering or not for a given dataset.it examines whether the data points differ significantly from uniformly distributed data in multidimensional space.
This concludes our article on the k-means clustering algorithm. In my next article, I will talk about the python implementation of the K-means clustering algorithm.
Thank you!
The media shown in this article are not owned by Analytics Vidhya and is used at the Author’s discretion.





