This article was published as a part of the Data Science Blogathon.
Introduction
Data Lake architecture for different use cases – Elegant and scalable solutions

Introduction:
Data Analytics is a blanket term in some sense which includes the job of a Data Engineer, Data Analyst, Data Scientist, and many more. In large-scale projects, many would agree with me that the job starts at databases which include creating data architectures for reading data from heterogeneous sources like your regular on-premise database, data from ERP systems, CRM systems, marketing tools, social media sites, messaging platforms, etc. Then comes decisions involving how and where to store this data – on-premise, cloud, or a hybrid model; how to manage this data – loading strategies; which ETL tool to use for data massaging, etc.
Therefore, in a real-world scenario, it becomes extremely important for Data Analytics/ Data science professionals to get their hands dirty with messy data and wear their Data Engineer’s hat also for a large part. More specifically, learn to handle and work on data on Cloud as it is surely the way forward.
This article attempts to explain the concept of a data lake and gives an overview of a few of the important and popular data lake architectures serving different use cases.
What is a Data Lake?
By definition, a data lake is a centralized repository that allows you to store all your structured and unstructured data at any scale [1].
Although the term ‘Data Lake’ was coined by James Dixon, founder of Pentaho in 2010, it has attracted many users lately since companies have realized the importance of unstructured data along with regular relational data. The advantage of using a data lake is that all files in their native format can be stored in storage file formats. It creates a big advantage when dealing with Big Data, image files, text files, logs, web content can reside in a single data repository in raw format and can be converted to actionable insights as and when required.
As more and more players move into the Cloud Computing space, the competition is making data hosting, computing, and security efficient and scalable. Every cloud player is offering a host of services in areas of storage, compute, ETL, security, analytics, machine learning, visualization, etc. basically a complete package for a company to build an analytics pipeline.
Why is there a need for a data lake when your organization already has a data warehouse?
Most likely this question will come to your mind as you start with your cloud journey. A data warehouse will host your relational database and if you have an efficient DWH it certainly is not a good idea to scrap away everything you have build over the years. It is perfectly okay for both approaches to co-exist.
Your DWH will continue to store and process transactional data and data which is required by users who consume daily or monthly dashboards or reports for making data-driven decisions, basically your operational data. Data that is required for higher data use like data mining, running machine learning algorithms on unstructured data can go into your Data Lake. A point to note here is your structured data also can reside in Data Lake and cloud companies provide fully managed database services like AWS RDS (Relational Database Service) and Amazon Redshift.
As per the data lake definition above although it is a central repository, many layers or dedicated areas can be created inside a data lake for effective implementation. For example, a curated layer is a layer that will contain all your cleansed data. An analytics sandbox will be a dedicated area for data scientists to run algorithms and so on. This advantage will be only available in a data lake.
Why AWS?
Well, a very simple answer to this is that I have worked on AWS only till now and have found it extremely scalable and a complete solution. [This is my personal opinion and not a promotional article]
Also, going by the statistics online, AWS is the most preferred solution for companies.
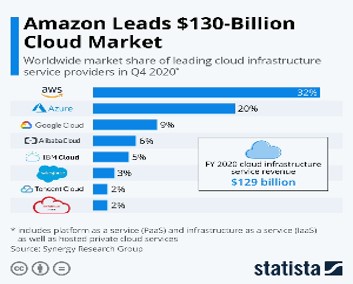
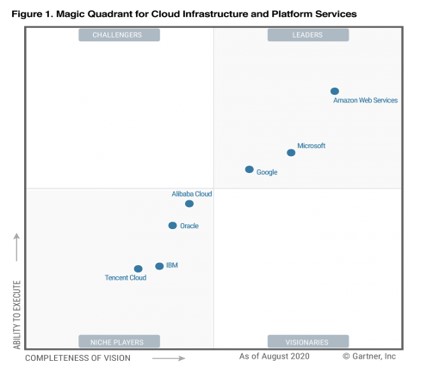
Gartner report has also for the 10th consecutive year has named AWS as leading Market Platform.
Like most cloud platforms, AWS also offers a ‘Pay as you use’ approach, which means you only pay for what you use. So while creating your first data lake, even if you are not sure of the infra, you can start small and can scale as and when required.
Having understood the concept of a data lake and its importance vis a vis a data warehouse, we will look at two possible use cases and corresponding data architectures in AWS. While there can a be wide range of scenarios based on the requirements and budgets for the project, the idea behind selecting these two scenarios is to touch upon some important services offered by AWS.
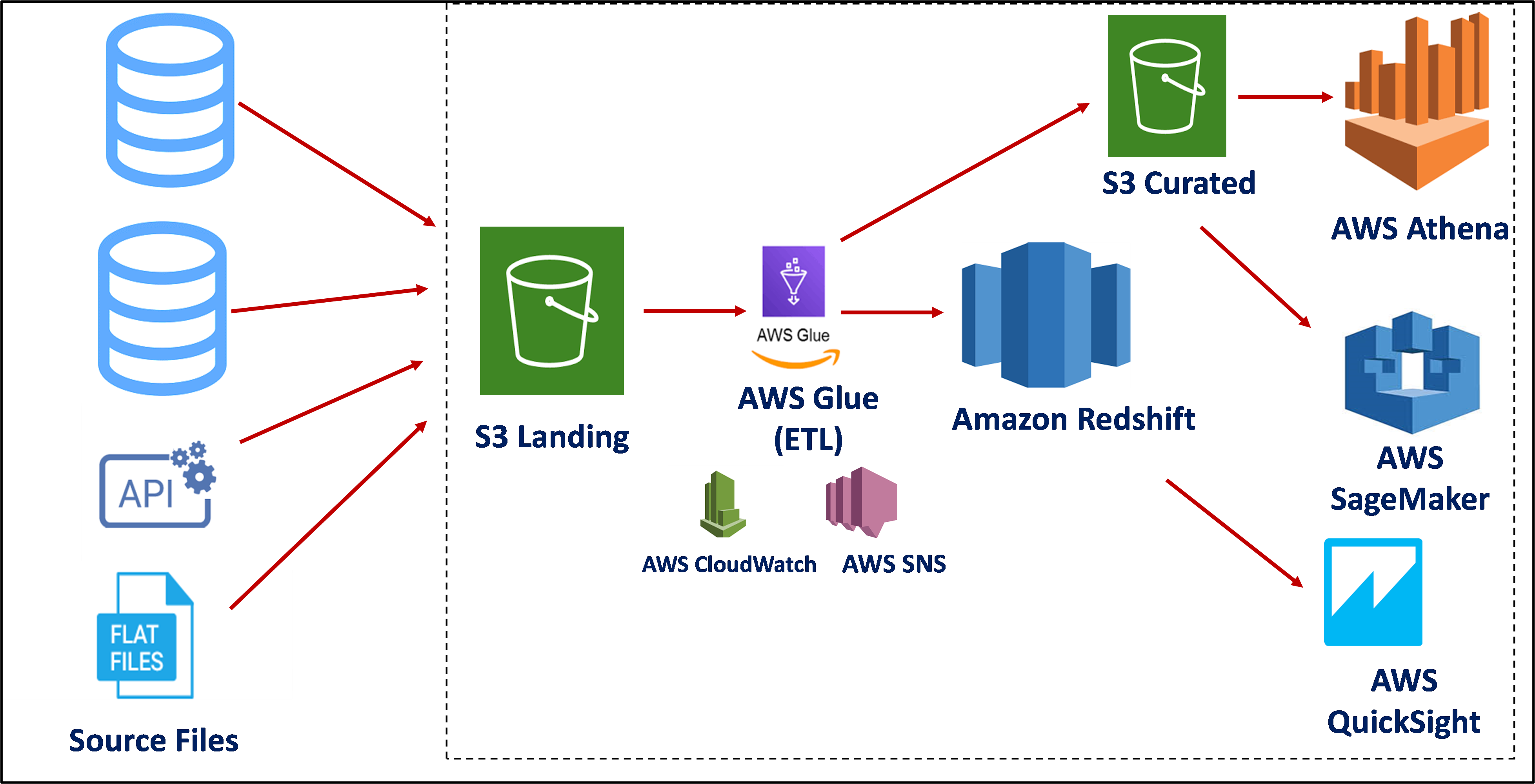
Use Case 1 – Requirement of high-performance analytics pipeline with fully managed services
The above use case can be realized by using the S3 bucket as a landing area for heterogeneous data sources. AWS Glue is used as an ETL tool, and its related services like AWS CloudWatch for monitoring and security, and AWS SNS for notifications on the status of jobs are used. From AWS Glue, data is loaded to Amazon Redshift which provides a fully managed service to store highly structured and voluminous data.
AWS Glue also loads part data that is unstructured or semi-structured in the S3 bucket which forms a curated layer for querying data directly using AWS Athena giving users the power to query data in a SQL fashion. Data scientists can use S3 curated for mining data. To save storage space, S3 files can be stored in Parquet or JSON format and can be consumed directly.
BI analysts can directly connect to Redshift for generating reports and dashboards for operational use.
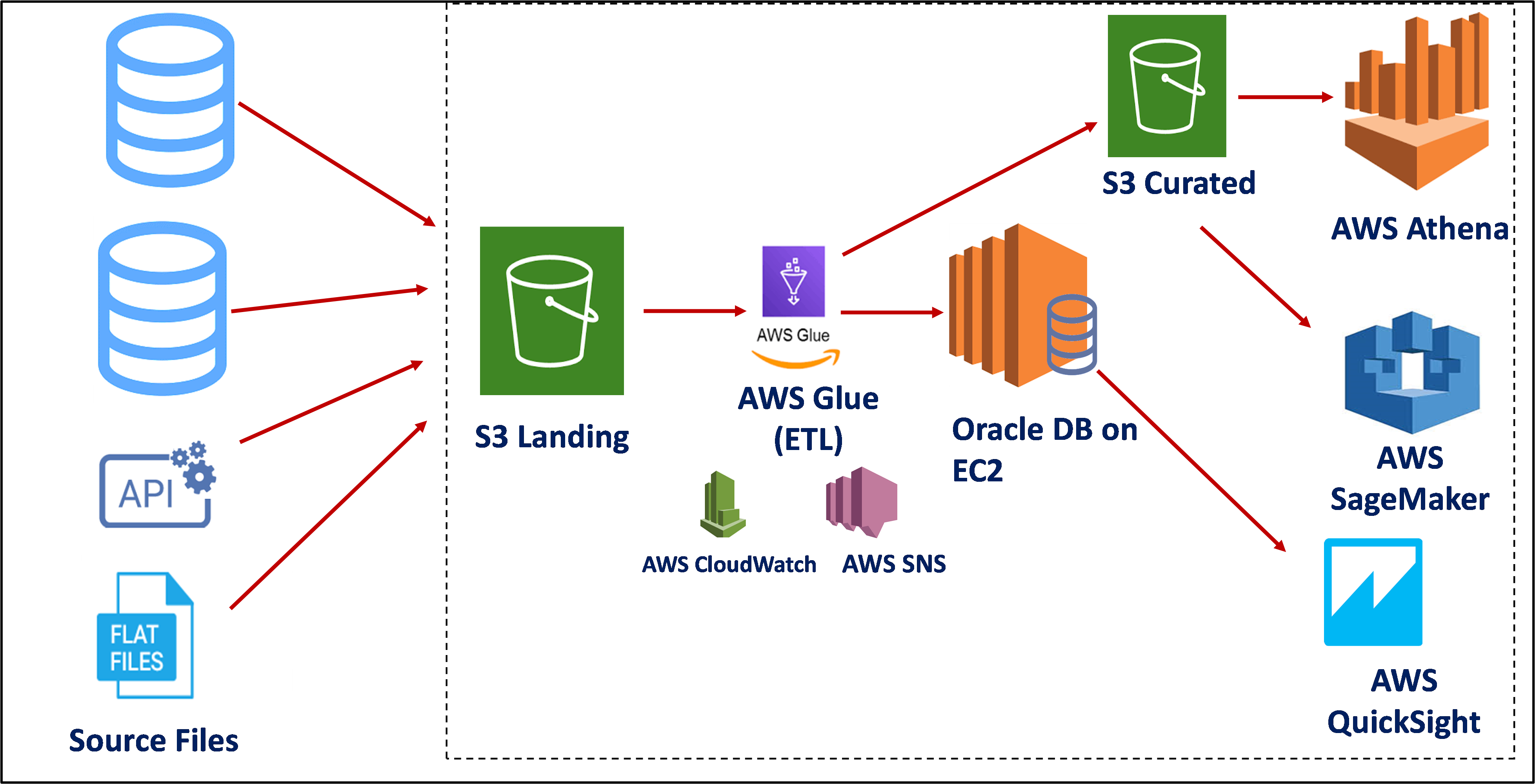
Use Case 2 – Requirement of low-cost analytics pipeline, have structured transactional data and flat files
For the second use case, a major difference is in the way data is stored after being loaded from AWS Glue. Instead of using AWS Redshift to store relational data, an Oracle instance is created on AWS Compute service called AWS EC2. Oracle on EC2 gives an advantage to companies to manage their databases and the cost is also low compared to AWS Redshift.
An added advantage being, that any other manipulations with data can be done in Oracle itself if the development team has strong Oracle skills. This highly cleansed data can be used by AWS QuickSight for analysis and data from S3 Curated can be used for creating ML algorithms.
Conclusion:
This article covered concepts of a data lake and two frequently used data lake patterns in AWS. However, it’s just a tip of an iceberg. With every changing scenario, requirement, cost considerations, team skills, and new services being introduced by cloud platforms, there is lot to cover. For example, event-driven architectures or serverless architectures using AWS Lambda or AWS Fargate, the possibilities are large. Using EMR clusters with AWS Redshift can again be a useful combination for large and voluminous data.
Hope this article was helpful to readers starting their cloud journey.
References:
[1] https://aws.amazon.com/big-data/datalakes-and-analytics/what-is-a-data-lake/ [2] https://pages.awscloud.com/GLOBAL-multi-DL-gartner-mq-cips-2020-learn.html
About the Author:
I am an analytics professional with around 10 years of experience in domain areas of healthcare, FMCG and Banking.
Happy to connect!!
LinkedIn: https://www.linkedin.com/in/ruchideshpande/
Profile on Medium: https://ruchideshpande.medium.com/






Hi can you please provide the architecture for real-time streaming data and Batch Processing Data using AWS Stack (Pyspark, Glue, Redshift, S3, Boto3)