Introduction
I’ve always found the naming convention for the fantasy genre really fascinating – barring perhaps detective stories, this genre has the most recurring name styles of any genre I’ve read. In fact, it seems to me like it has the most recurring titular words of any genre. So I decided it was time to make a couple of my own on-theme fantasy titles using a Markov Chain implemented in Python.
Part One: The Probabilistic Method
In order to generate a large number of fantasy-sounding titles, I decided to create a title generator. I went over to Wikipedia’s semi-comprehensive list of fantasy books to use as my data (although I noticed a marked absence of my personal favorite book, Reckless). Using the requests package to web scrape and Beautiful Soup to parse through the HTML, I created a list of (almost every) title in fantasy. Then I counted up every instance of every word in the corpus. Curious what the most common words in fantasy titles are?
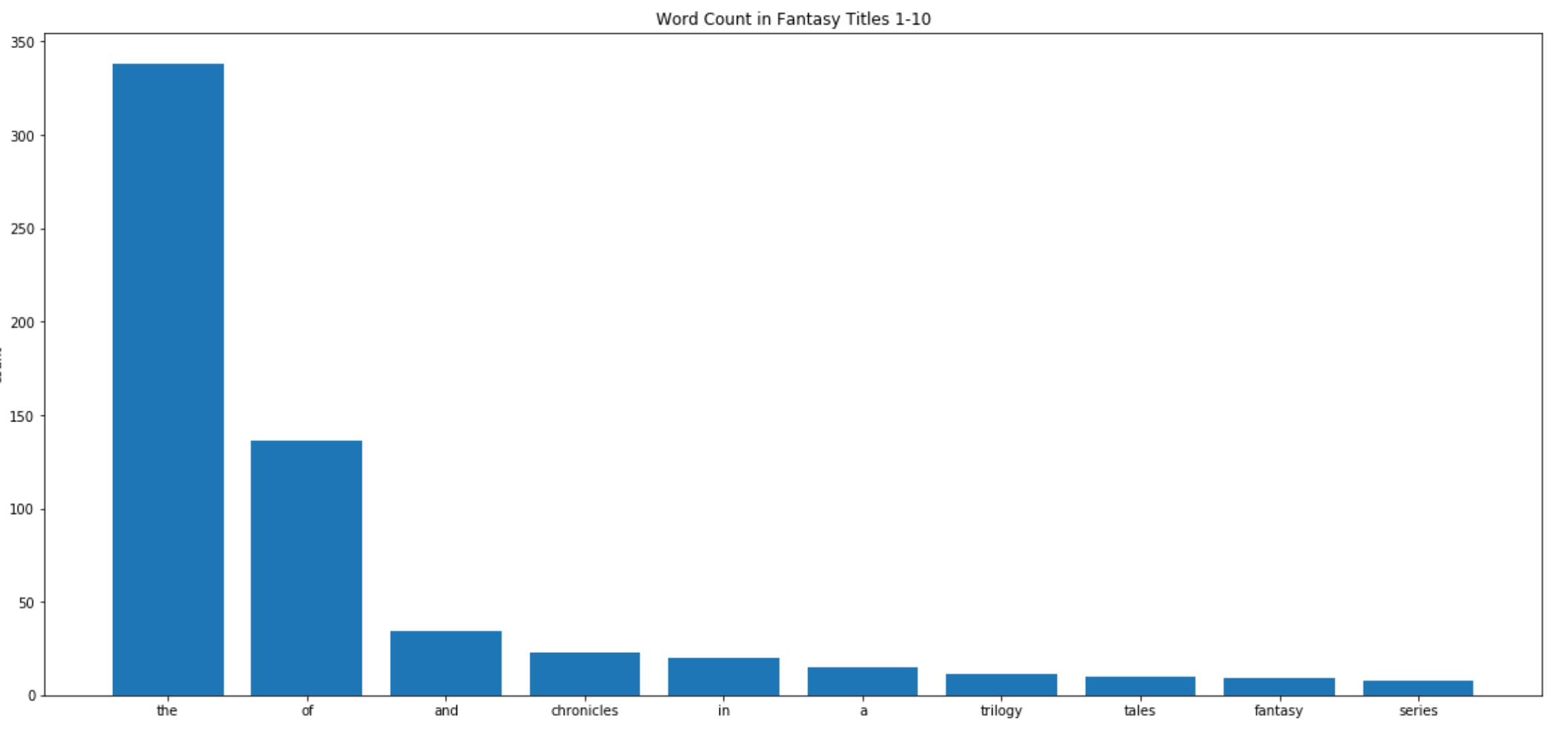
‘the’ is the most common word. No surprise there. After ‘the’ and ‘of’ it seems to drop off sharply. Let’s take a look at the common words after that.
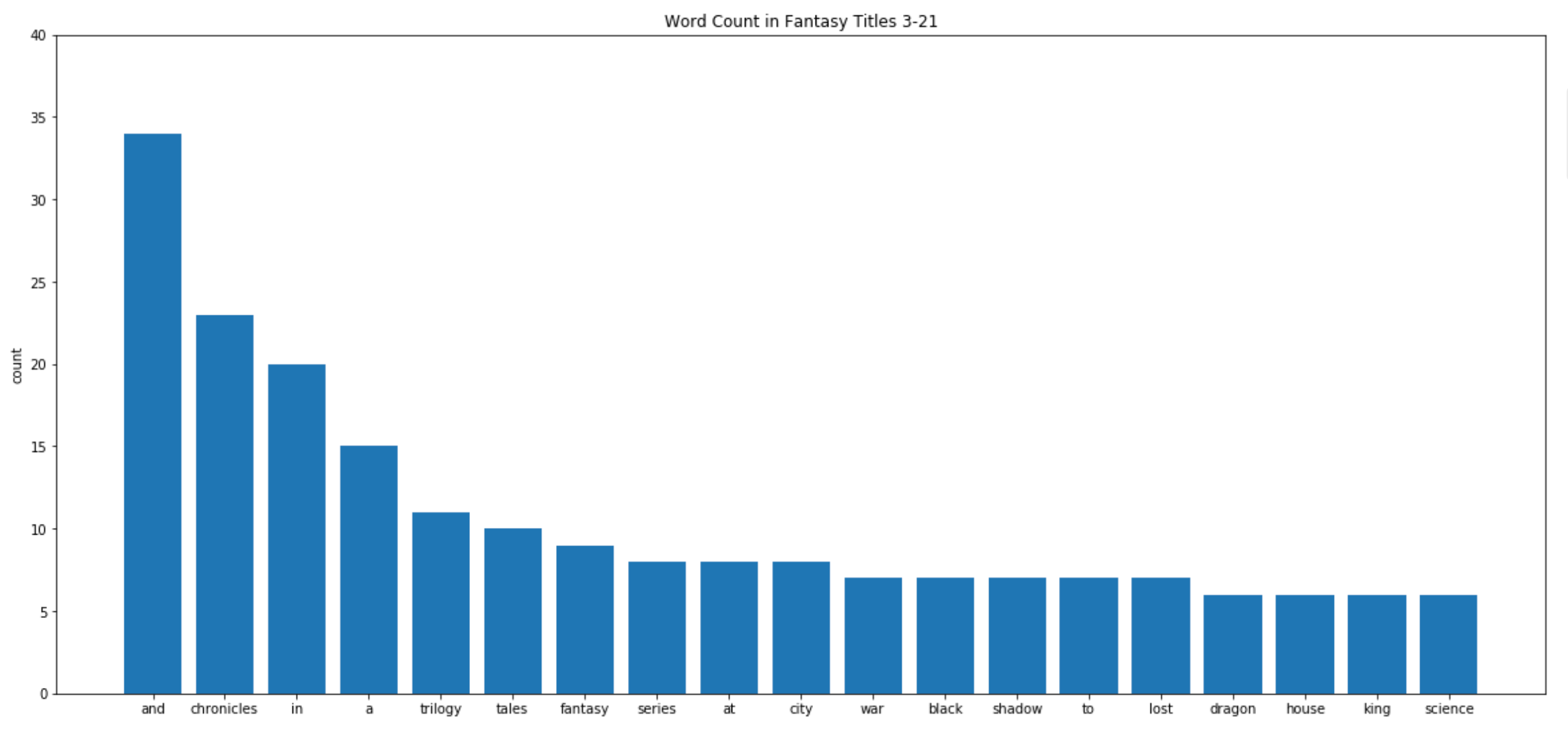
Here we are. Some classic fantasy words: ‘tales’, ‘war’, ‘black’, ‘dragon’.
Now in order to create my title generator, I am going to need the probability that a word appears in a fantasy title. Once I have this, then I simply select a sample of words probabilistically and shuffle them into a title.
Here is the same plot after dividing the count by the number of titles in the list to get the probabilities.
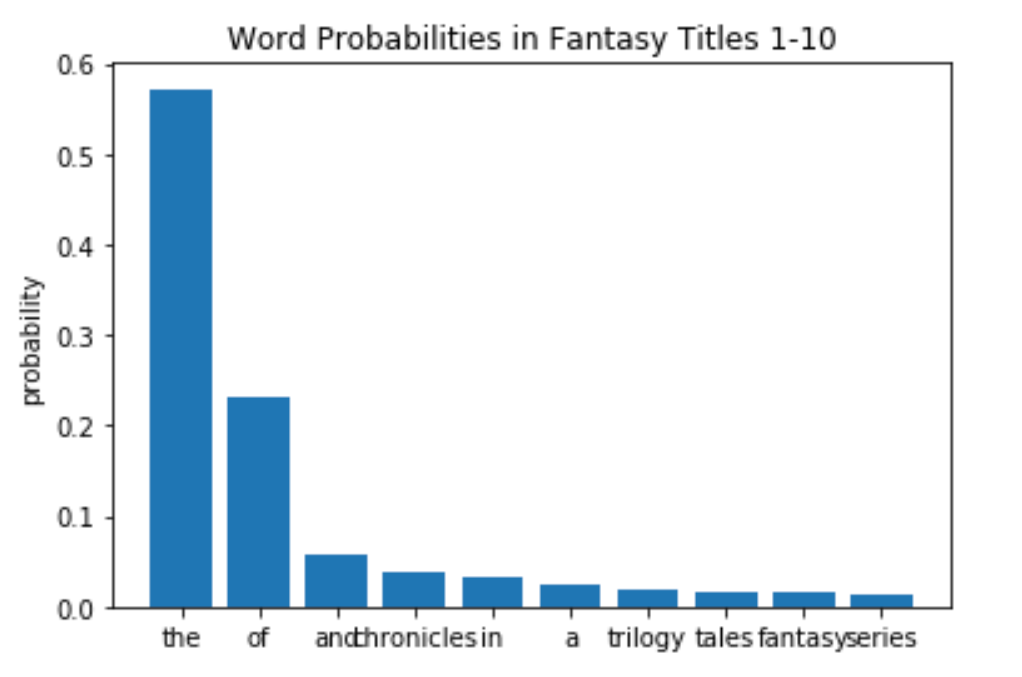
So ‘the’ is in just over half of all fantasy titles.
And now for the generator:
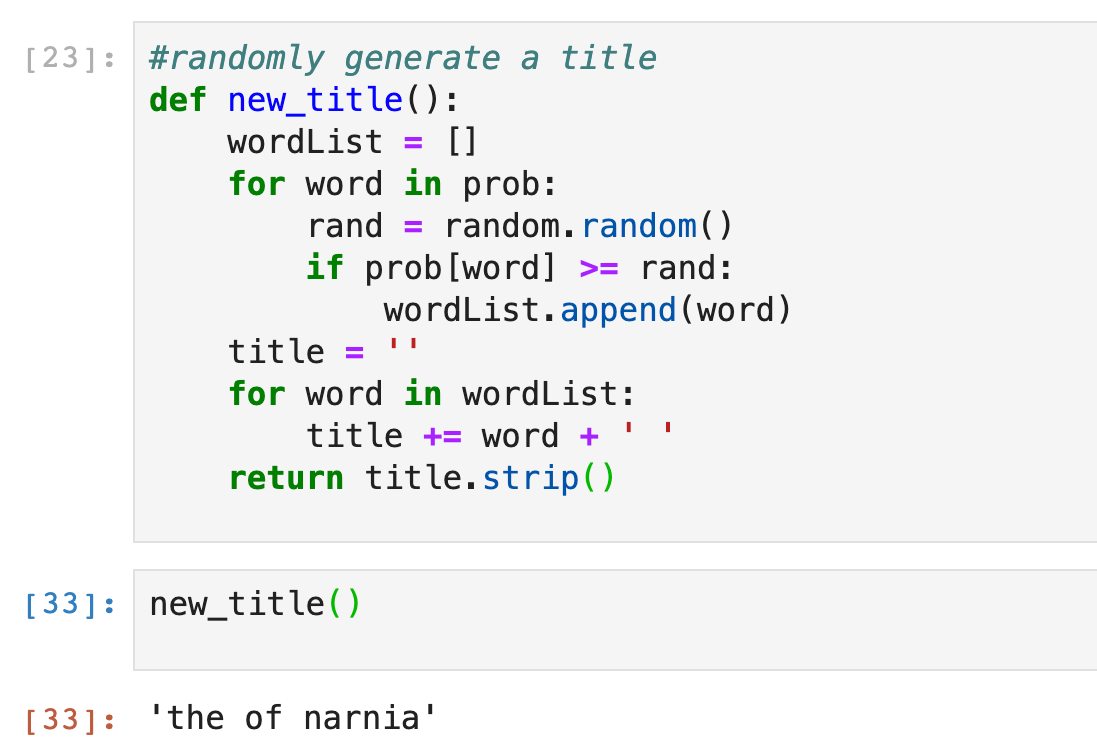
There are some clear issues with this. ‘The of’ for one thing. I made a slightly more nuanced version that disallowed this — it keeps shuffling the order of the words until it meets a set of requirements (for instance, of cannot follow the).
Here are some titles the procedure generated:
the regard young
the cycle solstice
in of chrestomanci unknown sorrow tree saga
the to shattered
dragonology night unicorn
series dirk desire
damiano
the power prince matilda mountain
the shadow science inkdeath nothing fortune
the taller ever
It’s still pretty bad. And this generator has some significant limitations. First of all, because we’re picking each word based on a probability, the same word can’t appear twice in a title. But we can imagine that the word ‘the’, for instance, might appear twice in some fantasy titles. Secondly, the generator has no sense of semantics, stapling nouns together like a conga line. And it won’t pick up on common name patterns, like titles formatted as “The noun of the noun.”
So, can we do better?
Part Two: The Markov Chain
A Markov Chain is a process that describes a possible sequence of events through a matrix. The rows represent the current state (the current word, in this case) and the columns represent the next state. The row-column element of the matrix is the probability that the column will follow that row. In this section, I’ll demonstrate how I built the Markov Chain using Python and applied it to generate fantasy titles.
Below is the Markov transition matrix I created for the titles data. I created it through the following process:
- for each word, I counted up every word that followed it in a title
- the rows of the transition matrix represented each word plus a start phrase token that I called *
- the columns of the matrix represented each word plus an end phrase token that I called #
- in each row-column element, I put the count of the number of times that column word followed that row word in a title
- finally, I normalized each element by the row sum to get the probability that the column word would follow the row word
I also add a very small probability to every count so that there is a tiny possibility of any word showing up. This adds some noise that hopefully keeps the generator from creating actual fantasy titles too often.
And here’s the generator:

In brief, we start by setting our variable word to the phrase start token *. Then, as long as the word is not the phrase end token #, we move from state to state in the Markov chain. By the end, we will have randomly created a path of words connecting * to #. That path is our title.
How did the Markov Generator do? Well, let’s take a look at some titles.
the city of fairy tale
tomoe gozen
gloriana or the fates of alvin maker
clockwork angel tower
the walls
lilith
the end of narnia
dungeons dragons
the anubis gates
the stress of fantasy
That certainly sounds better! No nonsense phrases like the last model. I would totally read the city of a fairy tale!
Let’s look at a couple more:
chimera
shadowplay
coraline
pellucidar
witch of honey
sangreal trilogy
brak the revenants
overtime
the golden cage
the well at the wolf leader
inkspell
septimus heap
chrestomanci
the kin of the fates of somebody the last unicorn
eragon
the vollplaen crock of atrix wolfe
vampire academy
the tree of night land
the kane chronicles
chernevog
Perhaps you can now start to see the limitations of our Markov model — and they’re very different from the limitations of the probabilistic model.
Limitation number one: one-word titles. They show up a lot since every word that appears at the end of a title has a high likelihood of stopping there. Since we’re following Markov trails rather than picking each word independently, we hit phrase ends often and come up with lots of one-word titles. And while there are plenty of real one-word fantasy titles, I don’t think there are this many.
Limitation number two: reproducing real fantasy titles. Coraline, Eragon, The Kane Chronicles. The problem is that we are following the paths laid by real fantasy novels – meaning that we oftentimes just follow the path completely and regurgitate the actual title. I added extra noise in the system in order to eliminate this problem, but clearly, it is still happening rather often. You could add more noise in to try to fix this, but at some point, the titles will just look so random it will be like the probabilistic model again.
So, in summation, is the Markov Chain model better than the probabilistic model? Well, yes and no. I find it more enjoyable to read since I can usually parse the titles. And many of them sound like things I might actually read on a lazy summer day. But it also falls into some traps that the probabilistic model avoids. The probabilistic model will almost never recreate an actual title.
Are we doomed then to pick between the probabilistic method’s randomness and the syntax of the Markov Chain method? Will our computer-generated titles always sound too far or too close to real printed titles?
Perhaps, perhaps. But we are only using simple methods. The most promising way to create a fantasy title generator is with machine learning – having an algorithm teach itself to create titles and compare them with real titles to learn what titles are bad and which are good. So fire up the portal and outline the pentagram. If you want truly (artificially) inspired titles, you’ll have to summon up a neural net.

Want to try running the code yourself? Generate some titles at my repl.it here.





